


اصطلاح کلان داده به حجم بزرگی از دادهها و روش پردازش آنها اشاره دارد. هر سازمان و کسب و کار بزرگی میتواند با استفاده از ابزارهای پیشرفته در این زمینه دادهها را پردازش کرده و نتایج شگفتانگیزی بهدست آورد. امروزه ابزارهای مختلفی در زمینه جمعآوری، پردازش و مشاهده کلان دادهها وجود دارد. علاوه بر ابزارهای کاربردی باید به چارچوبها و روشهایی که برای این منظور در دسترس متخصصان قرار دارد اشاره کرد که از مهمترین آنها باید به آپاچی هادوپ (Apache Hadoop)، الگوریتم نگاشتکاهش (MapReduce)، سیستم فایل توزیع شده هدوپ (Hadoop Distributed File System)، آپاچی هایو (Apache Hive)، آپاچی ماهوت (Apache Mahout)، آپاچی اسپارک (Apache Spark)، دریاد (Dryad)، استورم (Storm)، آپاچی دریل (Apache Drill)، جاسپرسافت (Jaspersoft) و اسپلانک (Splunk) اشاره کرد.
متخصصان فعال در حوزه پردازش دادهها فارغ از ابزارهایی که برای تحلیل دادهها از آنها استفاده میکنند، بهطور معمول از روشهای پردازش دستهای (batch processing)، پردازش جریانی (stream processing) و تحلیل تعاملی (interactive analysis) استفاده میکنند. بیشتر ابزارهای پردازش دستهای مبتنی بر زیرساخت آپاچی هدوپ، و آپاچی ماهوت و دریاد هستند.
برنامههای پردازش دادههای جریانی بیشتر برای تحلیلهای بلادرنگ استفاده میشوند که از مهمترین زیرساختهای مرتبط با این گروه باید به استورم و اسپلانک اشاره کرد.
تحلیل تعاملی به متخصصان امکان تعامل مستقیم و بلادرنگ با دادهها و پردازش لحظهای آنها را میدهد. بهطور مثال، درِمِل و آپاچی دریل (Dremel and Apache Drill) اصلیترین زیرساختهای این گروه هستند که پشتیبانی خوبی از تحلیلهای تعاملی به عمل میآورند.
هر یک از ابزارهای یاد شده برای کاربردهای خاصی استفاده میشوند و اینگونه نیست که برای پردازش هر نوع مجموعه داده بزرگی از یک ابزار واحد استفاده کرد. بر همین اساس در این مقاله به معرفی ابزارهایی میپردازیم که برای پردازش کلان دادهها در دسترس توسعهدهندگان قرار دارد.
آپاچی هدوپ و رویکرد نگاشتکاهش
هدوپ یک چارچوب نرمافزاری منبعباز است که برای پردازش توزیعشده دادههای بزرگ میزبانی شده روی خوشههایی از سرورها استفاده میشود. چارچوب مذکور به زبان جاوا نوشته شده و برای پردازش توزیع شده روی هزاران ماشین با تحملپذیری خطای بالا طراحی شده است. یکی از مهمترین دلایلی که باعث شده تا متخصصان از هدوپ به عنوان یکی از ابزارهای تحلیل کلان دادهها استفاده کنند عدم وابستگی به سختافزارهای گرانقیمت است، زیرا این زیرساخت از تحملپذیری در مقابل خطا در خوشهها و الگوریتمهای نرمافزاری به منظور تشخیص و مدیریت خرابی در لایههای مختلف استفاده میکند. این زیرساخت به شکل گستردهای توسط شرکتهای بزرگی مثل متا و گوگل استفاده میشود و به خوبی از فناوری ارتباطی RPC سرنام Remote Procedure Call پشتیبانی میکند. یکی از پر کاربردترین زیرساختهای نرمافزاری برای تحلیلهای کلاندادهها آپاچی هدوپ و الگوریتم نگاشتکاهش است. آپاچی هدوپ شامل هسته هدوپ، الگوریتم نگاشتکاهش، سیستم فایل توزیع شده هدوپ و آپاچی هایو (Apache Hive) است.

نگاشت کاهش یک چارچوب برنامهنویسی برای پردازش دادههای کلان بر مبنای رویکرد تقسیم و حل است. روش تقسیم و حل در دو گام نگاشت (Map) و کاهش (Reduce) پیادهسازی میشود. بهطور معمول، هدوپ فرایند پردازش دادهها را بر مبنای الگوی گره اصلی و گره کارگر مدیریت میکند. گره اصلی، ورودی را به دو زیرمسئله کوچکتر تقسیم میکند و در گام نگاشت آنها را برای گرههای کارگر توزیع میکند. پس از آن گره اصلی خروجیها را برای همه زیرمسائل در گام کاهش ترکیب میکند. با توجه به عملکرد خوبی که این مکانیزم در پردازش کلان دادهها دارد و مکانیزم قدرتمندی برای پردازش کلان دادهها ارایه میکند، آپاچی هدوپ اصلیترین زیرساخت بهکار گرفته شده در این حوزه است. این چارچوب برای ذخیرهسازی دارای تحمل خطا (fault-tolerant storage) و پردازش حجم گستردهای از دادهها مفید است. هسته اصلی هدوپ از یک بخش ذخیرهسازی به نام سیستم فایل توزیع شده هدوپ و پردازش/ نگاشت ساخته شده است. هدوپ فایلها را به بلوکهای بزرگ شکسته و آنها را میان گرههای یک خوشه توزیع میکند. برای پردازش دادهها بخش Map/Reduce کدی را برای گرهها ارسال میکند تا پردازش بهشکل موازی انجام شود. در الگوی فوق پردازش ابتدا روی گرههای محلی در دسترس انجام میشود تا دادهها سریعتر پردازش شوند.
چارچوب اصلی هدوپ از ماژولهای بخش مشترکات هدوپ (شامل کتابخانهها و بستههای نرمافزاری لازم)، سیستم فایل توزیع شده هدوپ HDFS (یک سیستم فایل توزیع شده که دادهها را روی ماشینهای خوشه ذخیره کرده و از پهنای باند به شکل بهینه استفاده میکند)، YARN (یک پلتفرم مدیریت منابع که مسئول مدیریت منابع محاسباتی در خوشهها است) و Map/Reduce (یک مدل برنامهنویسی برای پردازش داده در مقیاسهای بالا است) تشکیل شده است. کاری که هدوپ انجام میدهد این است که یک سیستم فایل توزیع شده آماده میکند که میتواند دادهها را روی هزاران سرور ذخیره کند و وظایف اجرایی را توسط مکانیزم نگاشتکاهش روی ماشینها پخش کرده و پردازش دادهها را انجام دهد.
همانگونه که اشاره شد، هدوپ بر مبنای الگوی MapReduce کار میکند که یک محاسبه بزرگ توزیع شده را بهشکل دنبالهای از عملیات توزیع شده روی مجموعه دادهای از زوجهای کلید/مقدار نشان میدهد. چارچوب مذکور یک خوشه از ماشینها را انتخاب میکند و فرایند نگاشتکاهش تعریف شده توسط کاربر را روی گروههای این خوشه اعمال میکند. در این فرایند دو مرحلهای نگاشت و کاهش انجام محاسبات بر مبنای مجموعه دادهای از جفتهای کلید/مقدار انجام میشود.
در مرحله نگاشت چارچوب مذکور، داده ورودی را به تعداد زیادی قطعه تقسیم میکند و هر قطعه به یک وظیفه نگاشت تخصیص میدهد. علاوه بر وظایف نگاشت که زیاد هستند، فرایند توزیع بین گرههای یک خوشه برای اجرا را نیز مدیریت میکند. هر وظیفه نگاشت از زوج کلید/مقدار بخش تخصیص یافته استفاده میکند و مجموعهای از زوجهای میانی کلید/مقدار را تولید میکند. برای هر زوج کلید/مقدار (Key, Value)، مرحله نگاشت یک تابع نگاشت تعریف شده توسط کاربر را فراخوانی میکند که ورودی را به زوج کلید/مقدار متفاوتی تبدیل میکند تبدیل کند. در ادامه مرحله نگاشت چارچوب، دادههای میانی را با توجه به کلید مرتبسازی میکند و مجموعهای از جفتهای (K,V) تولید میکند تا تمام مقادیر مربوط به یک کلید مشخص با هم نشان داده شوند. علاوه بر این، مجموعه چندتاییها را به چند قطعه مساوی با تعداد وظایف کاهش تقسیم میکند.
در مرحله کاهش، هر فرایند کاری یک چندتایی (K,V) را دریافت کرده و فرایند پردازش روی آنها را انجام میدهد. برای هر چندتایی، هر وظیفه کاهنده یک تابع کاهنده تعریف شده توسط کاربر را فراخوانی میکند که چندتایی را به یک خروجی زوج کلید/مقدار (K, V) تبدیل میکند. پس از انجام پردازشهای موردنیاز، تمامی فرایندهای انجام شده روی گرههای خوشه، توزیع شده و قطعه مناسب داده میانی را به هر وظیفه کاهنده انتقال میدهند. وظایف در هر مرحله بهشکل تحملپذیر در مقابل خطا اجرا میشوند، بهطوری که اگر گرهای در فرایند محاسبه خراب شد، وظیفه تخصیص یافته به آن میان گرههای باقیمانده بازتوزیع شود. داشتن وظایف زیاد نگاشت و کاهش باعث توزیع مناسب بار شده و اجازه میدهد تا وظایف ناموفق با سربار زمانی کم دوباره اجرا شوند.
معماری Map/Reduce
چارچوب Map/Reduce هدوپ مبتنی بر معماری (Master/Slave) است. این چارچوب یک سرور Master بهنام jobtracker و سرورهای Save بهنام tasktracker به ازای هر گره در خوشه دارد. jobtracker نقطه تعامل بین کاربران و چارچوب است. متخصصان کارهای نگاشتکاهش را به jobtracker ارسال میکنند تا jobtracker این کارها را در یک صف از کارهای در حال انتظار قرار داده و آنها را بر مبنای رویکرد اولین ورودی/اولین سرویس اجرا میکند. jobtracker تخصیص وظایف نگاشت و کاهش به tasktrackerها را مدیریت میکند. tasktrackerها، وظایف را بر مبنای دستورالعمل jobtracker اجرا میکند و فرایند انتقال دادهها میان مراحل نگاشت و کاهش را مدیریت میکند.
1. HDFS قلب تپنده هادوپ
سیستم فایل توزیع شده هادوپ راهکاری مطمئن برای ذخیرهسازی فایلهای بزرگ روی خوشهها است. HDFS هر فایل را بهشکل یک دنباله از بلوکها ذخیره میکند. لازم به توضیح است که تمام بلوکهای موجود در یک فایل به غیر از آخرین بلوک هم اندازه هستند. برای غلبه بر مشکل خطا و افزایش تحملپذیری سیستم در برابر خطا از تمامی اطلاعات نسخه کپی (replication) تهیه میشود. البته اندازه بلوک و فاکتور تهیه کپی در هر فایل قابل تنظیم است. علاوه بر این، فایلهای موجود در HDFS از ویژگی Write Once پشتیبانی میکنند به این معنا که هر لحظه تنها یک کاربر قادر به دستکاری آنها است. HDFS نیز همانند چارچوب نگاشتکاهش از رویکرد Master/Slave استفاده میکند. ساختار HDFS شامل یک گره نام است که یک سرور Master است و فضای نام فایل سیستم را مدیریت کرده و دسترسی به فایلها توسط کلاینتها را امکانپذیر میکند. به علاوه، تعدادی گره دادهای نیز وجود دارد. گرههای دادهای دسترسی به عملیاتی مثل باز کردن، بستن، تغییر نام فایلها و پوشهها را از طریق پروتکل RPC امکانپذیر میکند. علاوه بر این، گره دادهای وظیفه رسیدگی به درخواستهای خواندن و نوشتن دریافتی از طرف کلاینتهای فایل سیستمی را دارد. لازم به توضیح است که فرایند تولید، حذف و ساخت کپی از بلوکها بر مبنای دستورالعمل گره دادهای انجام میشود.
2. آپاچی ماهوت
دومین پلتفرم مطرح در این زمینه آپاچی ماهوت است که زیرساختی قدرتمند برای پردازش کلان دادهها، روشهای یادگیری ماشین گسترشپذیر و نرمافزارهای تحلیل داده ارایه میکند. الگوریتمهای اصلی ماهوت شامل خوشهبندی، دستهبندی، کاوش الگو، رگرسیون، کاهش ابعاد، الگوریتمهای تکاملی و فیلتر مشارکتی دستهای (Batch) هستند که بر مبنای زیرساخت هادوپ طراحی شدهاند. آپاچی ماهوت نیز از چارچوب نگاشتکاهش برای پردازش دادهها استفاده میکند. از شرکتهای بزرگی که از آپاچی ماهوت و الگوریتمهای گسترشپذیر یادگیری ماشین استفاده میکنند باید به گوگل، آیبیام، آمازون، یاهو و فیسبوک اشاره کرد.
3. آپاچی اسپارک
آپاچی اسپارک یکی دیگر از چارچوبهای پردازش کلان داده است که متنباز است و برای پردازش سریع و تحلیلهای پیچیده از آن استفاده میشود. این چارچوب که مورد توجه توسعهدهندگان ایرانی قرار دارد در سال 2009 میلادی در آزمایشگاه UC Berkeleys AMPLab ساخته شده است. اسپارک به توسعهدهندگان اجازه میدهد برنامههای خود را به زبانهای جاوا، اسکالا یا پایتون بنویسند. اسپارک علاوه بر الگوریتم نگاشتکاهش از محاورههای اسکیوال، جریان داده، یادگیری ماشین و پردازش دادههای گراف پشتیبانی میکند. این چارچوب نیز بر مبنای زیرساخت سیستم فایل توزیع شده هدوپ (HDFS) ساخته شده، با این تفاوت که تغییراتی در زیرساخت اصلی اعمال کرده تا انجام برخی کارها سریعتر و بهتر انجام شوند. اسپارک مولفههای مختلفی دارد که از مهمترین آنها باید به برنامه راهانداز، مدیر خوشه و گرههای کارگر اشاره کرد. مدیر خوشه فرایند تخصیص منابع را مدیریت میکند تا پردازش دادهها به شکل مجموعهای از وظایف انجام شود. هر برنامه شامل مجموعهای از پردازهها است که به آنها اجراکنندگان گفته میشود. بزرگترین مزیتی که آپاچی اسپارک نسبت به نمونههای مشابه دارد این است که استقرار برنامههای اسپارک در خوشه هدوپ پشتیبانی میشوند. شکل1 معماری آپاچی اسپارک را نشان میدهد.
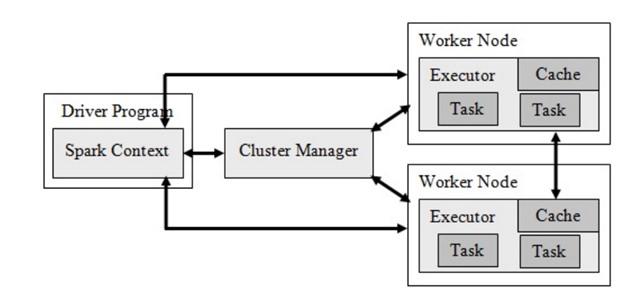
شکل 1
تمرکز اصلی اسپارک بر مجموعه دادههای توزیع شده انعطافپذیر (Resilient Distributed Datasets) است که دادهها را در حافظه ذخیره میکند و قابلیتهای کاربردی خوبی برای مقابله با خرابیها دارد. علاوه بر این، از رایانش بازگشتی پشتیبانی کرده و سرعت زیادی در پردازش دادهها ارایه میکند. اسپارک علاوه بر نگاشتکاهش از جریانهای داده، یادگیری ماشین و الگوریتمهای گراف نیز پشتیبانی میکند. مزیت بزرگ دیگری که اسپارک دارد پشتیبانی از زبانهای برنامهنویسی جاوا، آر، پایتون و اسکالا است. معماری اسپارک به گونهای است که میتواند یک برنامه در خوشه هدوپ را صد مرتبه سریعتر اجرا کند، زیرا دادهها را درون حافظه واکشی کرده و تمامی فعالیتهای پردازشی را درون حافظه انجام میدهد. به همین دلیل برای استفاده از چارچوب فوق به حافظه اصلی زیادی نیاز است. اسپارک به زبان برنامهنویسی اسکالا نوشته شده و روی ماشین مجازی جاوا اجرا میشود.
4. استورم (Storm)
استورم یک سیستم محاسباتی زمان واقعی توزیع شده دارای تحملپذیری خطا برای پردازش جریانهای دادهای است. زیرساخت مذکور برخلاف هدوپ که برای پردازش دستهای طراحی شده برای پردازشهای بلادرنگ طراحی شده است. بهعلاوه، راهاندازی و اجرای آن ساده است. استورم به دو دلیل مهم گسترشپذیری و تحملپذیری در برابر خطا مورد توجه توسعهدهندگان قرار دارد. توسعهدهندگان میتوانند توپولوژیهای مختلفی را روی استورم اجرا کنند که درست در نقطه مقابل زیرساخت هدوپ قرار دارد که برای اجرای برنامههای متناظر از الگوریتم نگاشتکاهش استفاده میکند. استورم شامل دو نوع خوشه گره اصلی و کارگر است. گره اصلی و کارگر دو نوع از نقشها مانند nimbus را ایجاد میکنند که یکسان با مولفههای jobtracker و tasktracker در چارچوب نگاشتکاهش هستند. Nimbus مسئولیت توزیع کد در خوشه استورم، برنامهریزی و تخصیص وظایف به گرههای کارگر و نظارت بر کل سیستم را عهدهدار است. کل فناوری محاسباتی به تعدادی فرآیند کارگر تقسیمبندی و توزیع شدهاند و هر فرآیند کارگر بخشی از توپولوژی را پیادهسازی میکند.
5. آپاچی دریل (Apache Drill)
آپاچی دریل یکی دیگر از سیستمهای توزیع شده برای تحلیلهای تعاملی کلان دادهها است. زیرساخت مذکور انعطافپذیری بیشتری برای پشتیبانی از زبانهای محاورهای، فرمتهای داده و منابع دادهای دارد. بهعلاوه، این سیستم قابلیت پشتیبانی از دادههای تو در تو را دارد و میتواند از 10 هزار سرور پشتیبانی کند. به بیان دقیقتر، قابلیت پردازش دادهها در مقیاس پتابایتها را دارد. دریل از سیستم فایل توزیع شده هدوپ (HDFS) برای ذخیرهسازی و نگاشتکاهش برای انجام تحلیل دستهای استفاده میکند.
6. دریاد (Dryad)
دریاد از پارادایمهای برنامهنویسی قابل توجه برای پیادهسازی برنامههای موازی و توزیع شده برای مدیریت گرافهای جریان دادهای است. این پارادایم شامل خوشهای از گرههای کامپیوتری است و به توسعهدهنده اجازه میدهد از منابع یک خوشه برای اجرای برنامهها به شیوه توزیع شده استفاده کند. مزیت اصلی پارادایم فوق این است که کاربر نیازی به دانستن جزییات فنی برنامهنویسی همروند ندارد. یک برنامه دریاد روی یک گراف جهتدار محاسباتی اجرا میشود که از راسهای محاسباتی و کانالهای ارتباطی تشکیل شده است. به همین دلیل، دریاد میتواند طیف گستردهای از قابلیتها مثل ساخت گراف کار، برنامهریزی ماشینها برای فرآیندهای موجود، مدیریت شکست انتقال (transition failure handling) در خوشه و بصریسازی کار را ارایه میکند.
7. جابرسافت (Jaspersoft)
بسته نرمافزاری متنباز Jaspersoft به دلیل اینکه گزارشهایی در ارتباط با ستونهای پایگاه داده تولید میکند مورد توجه توسعهدهندگان قرار دارد. این بسته یک زیرساخت گسترشپذیر تحلیل کلانداده ارایه میکند و ظرفیت بصریسازی سریع دادهها روی پلتفرمهای ذخیرهسازی محبوب مانند مونگودیبی (MangoDB)، کاساندرا (Cassandra)، ردیس (Redis) و موارد مشابه را دارد. یکی از مهمترین ویژگیهای Jaspersoft این است که کلان دادهها را به سرعت و بدون استخراج، تبدیل، بارگذاری و پردازش میکند. بهعلاوه، توانایی ساخت گزارشها و داشبوردهای تعاملی مبتنی بر HTML را بهطور مستقیم از انباره داده دارد. گزارشهای تولید شده توسط این زیرساخت قابل اشتراکگذاری با افراد مختلف را دارند.
8. اسپلانک (Splunk)
اسپلانک یک زیرساخت بلادرنگ و هوشمند برای پردازش کلان دادههایی است که توسط ماشینها و حسگرهای هوشمند تولید میشوند. این پلتفرم فناوریهای ابرمحور و الگوریتمهای پردازشی مختلف را با یکدیگر ترکیب میکند تا توسعهدهندگان در زمینه جستوجو، نظارت و تحلیل دادههای تولید شده توسط ماشین از طریق یک رابط وب مشکل خاصی نداشته باشند. اسپلانک به شیوه نوآورانهای مثل گرافها، گزارشها و هشدارها نتایج را به توسعهدهندگان نشان میدهد. از جمله تفاوتهای اسپلانک با دیگر ابزارهای موجود میتوان به شاخصگذاری دادههای ساختاریافته و ساختارنیافته تولید شده توسط ماشینها، جستوجوی زمان واقعی، گزارش نتایج تحلیلی و داشبوردها اشاره کرد. این زیرساخت با هدف ارایه سنجههایی برای کاربردهای گوناگون، تشخیص خطا برای زیرساختهای فناوری اطلاعات و پشتیبانی هوشمند برای عملیات کسبوکارها توسعه پیدا کرده است.
کلام آخر
شواهد به وضوح نشان میدهند تا دو سال آینده حجم دادههای جمعآوری شده از حوزهها و صنایع مختلف در جهان دستکم دو برابر زمان حال خواهد بود. در حالت عادی این دادهها هیچ کاربردی ندارند، مگر اینکه برای کسب اطلاعات مفید تحلیل شوند. همین مسئله توسعه روشهایی برای تسهیل تحلیلهای کلان دادهها را ضروری میکند. تبدیل دادهها به دانش با پردازشهای دارای عملکرد و گسترشپذیری بالا فرایندی دشوار است که انتظار میرود با بهرهگیری از پردازش موازی و پردازش توزیع شده در معماریهای کامپیوتر نوظهور تسهیل شود. در ارتباط با دادهها و کلان دادهها باید به دو نکته مهم دقت کنید. اول آنکه دادهها همواره با مشکل عدم قطعیت روبرو هستند و دوم آنکه اغلب دارای مقادیر از دست رفته (missing values) هستند. مشکلات این چنینی روی عملکرد، تاثیرگذاری و گسترشپذیری مدلها و سیستمهای محاسباتی تاثیر منفی میگذارند. برای حل مشکلات این چنینی ضروری است پژوهشهای کاربردی در مورد کلان دادهها و نحوه ثبت و دسترسی موثر به دادهها انجام شود. بهعلاوه، برنامهنویسی تحلیلهای کلانداده یکی دیگر از مشکلات این حوزه هستند. تشریح نیازمندیهای دسترسی به دادهها در برنامههای کاربردی و طراحی انتزاعی زبان برنامهنویسی برای بهرهبرداری از پردازش موازی از ملزومات دیگر این حوزه هستند.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.






















نظر شما چیست؟