








تاریخچه کوتاهی از پانداس
پانداس ابتدا توسط وس مککینی (Wes McKinney) در سال 2008 زمانی که در موسسه AQR Capital Management کار میکرد، توسعه یافت. مککینی، شرکت AQR را متقاعد کرد که به او اجازه دهند پانداس را منبعباز کند. در ادامه، یکی دیگر از کارمندان شرکت AQR، بهنام چانگ شی در روند توسعه کتابخانههای اصلی پانداس در سال 2012 به او کمک کرد. با گذشت زمان نسخههای مختلفی از پانداس منتشر شدند که آخرین نسخه، پانداس 1.4.1 است.
پانداس چیست؟
اگر به علم دادهها بهعنوان یک شغل فکر میکنید، یکی از اولین کارهایی که باید انجام دهید یادگیری پانداس است. پانداس، کتابخانهای است که برای ساخت و دستکاری دادههای ساختیافته در پایتون استفاده میشود. منظور از دادههای ساختیافته چیست؟ ساختیافته، به دادههای ذخیرهشده در جداول اشاره دارد. جداولی که شامل سطرها و ستونها هستند. شبیه به آن چیزی است که در یک صفحه گسترده یا بانک اطلاعاتی مشاهده میکنید. دانشمندان علم دادهها، تحلیلگران، برنامهنویسان، مهندسان و بیشتر مشاغل حوزه فناوری مجبور به ساختاردهی و قالببندی دادههای خود هستند. پانداس به متخصصان اجازه میدهد دادههای خود را بهگونهای طبقهبندی کنند که امکان استفاده از آنها روی کامپیوترهایی که حداقل حافظه اصلی را دارند، بهوجود آید. البته، ترکیب نحوی و عملیاتی که پانداس روی دادهها انجام میدهد، الهامگرفته از کتابخانهها و چارچوبهایی مثل PySpark، Dask، Modin، cuDF، Baloo، Dexplo ، Table، StaticFrame و نمونههای مشابه است. در شرایطی که این کتابخانهها برای مقاصد مختلفی استفاده میشوند، در بیشتر موارد مناسب کار با کلان دادهها هستند، در حالی که پانداس قابلیت کار روی دادههایی که چندان حجیم نیستند را دارد.
پانداس چه کاربردی دارد؟
برنامهنویسان میتوانند از پانداس برای پروژههای مختلفی استفاده کنند. بهطور کلی، پانداس زیرساختی برای تعامل با دادهها در اختیارتان قرار میدهد، بهطوری که امکان پالایش، تبدیل و تجزیهوتحلیل دادهها را ارائه میکند. بهعنوان مثال، فرض کنید در نظر دارید کاوشی در مجموعه دادهای انجام دهید که در قالب یک فایل CSV روی سیستمتان ذخیرهسازی شده است. پانداس دادهها را از فایل CSV خوانده و به یک دیتافریم (DataFrame) که ساختار جدولی دارد، انتقال میدهد. در ادامه، به شما اجازه میدهد کارهای زیر را روی دادهها انجام دهید:
- محاسبات آماری روی دادهها انجام داده و به اطلاعاتی مثل میانگین، میانه، حداکثر یا حداقل مقدار هر ستون، دست پیدا کنید.
- بررسی کنید که آیا ستون A با ستون B همبستگی دارد یا خیر؟
- توزیع دادهها در ستون C چگونه است؟
- فرآیند تمیزکاری دادهها را بر مبنای فیلترهایی که روی ردیفها یا ستونها اعمال میشود، انجام دهید.
- دادهها را با کمک Matplotlib مصورسازی کنید و میلهها، خطوط، هیستوگرام، حبابها و موارد دیگر را ترسیم کنید.
- دادههای پالایششده را به قالب یک فایل CSV، پایگاه داده و غیره تبدیل کرده و ذخیره کنید.
قبل از اینکه وارد مبحث مدلسازی یا مصورسازی دادهها شویم، اجازه دهید، کمی درباره مفهوم مجموعه دادهها و کارهایی که پانداس قادر به انجام آنها است، صحبت کنیم.
پانداس چه مزایایی در اختیار توسعهدهندگان قرار میدهد؟
- سرعت بالا و عملکرد بهتر در ویرایش و تجزیهوتحلیل دادهها.
- توانایی بارگذاری دادهها از منابع مختلف.
- مدیریت ساده دادههای ازدسترفته در محاسبات نقطه شناور و دادههای غیر نقطه شناور.
- توانایی تغییر اندازه ستونها بهطوری که توسعهدهندگان میتوانند اشیاء با ابعاد بالاتر در DataFrame را درج یا حذف کنند.
- ادغام و یکپارچه کردن مجموعه دادهها.
- انعطافپذیری در شکلدهی به مجموعه دادهها و تعیین نقطه چرخش (Pivot).
- ارائه قابلیتهایی برای سریهای زمانی.
چرا پانداس مهمترین ابزاری است که یک متخصص علم دادهها در اختیار دارد؟
کتابخانه پانداس نهتنها یکی از مولفههای کلیدی علم دادهها است، بلکه در تعامل با کتابخانههای دیگر قابل استفاده است. پانداس بر مبنای بسته نامپای (NumPy) ساخته شده است، به این معنی که بخش عمدهای از ساختارهای نامپای در پانداس استفاده یا تکرار شدهاند. دادهها در پانداس اغلب برای تغذیه تحلیلهای آماری در SciPy، رسم توابع از Matplotlib و الگوریتمهای یادگیری ماشین در اسکیتلرن (Scikit-learn) استفاده میشوند. نوتبوکهای ژوپیتر نیز محیط خوبی برای استفاده از پانداس برای کاوش و مدلسازی دادهها ارائه میدهند، هرچند این امکان وجود دارد تا پانداس را با ویرایشگرهای متنی دیگر نیز مورد استفاده قرار داد. نوتبوکهای ژوپیتر به ما توانایی اجرای کد در یک سلول خاص بهجای اجرای کامل یک فایل را میدهند. رویکرد فوق، هنگامی که قرار است با مجموعه دادههای بزرگ و حجیمی کار کنیم که ممکن است فرآیند تبدیلها را پیچیده کنند، صرفهجویی قابل ملاحظهای در زمان بههمراه میآورد. همچنین، نوتبوکها راهی ساده برای مصورسازی فریمهای دادهای و نمودارهای پانداس فراهم میکنند.
چه زمانی باید استفاده از پاندس استفاده کنیم؟
اگر تجربهای در کدنویسی پایتون ندارید، نباید به سراغ یادگیری پانداس بروید. البته، برای کار با پانداس نیازی نیست عالیترین مفاهیم مهندسی نرمافزار را بدانید، اما آگاهی درباره اصول اولیه مثل، لیستها، تاپلها، دیکشنریها، توابع و حلقههای تکرار ضروری است. همچنین، بهدلیل شباهتهای زیادی که پانداس به نامپای دارد، پیشنهاد میکنیم ابتدا بهفکر یادگیری نامپای باشید.
چگونه از پانداس استفاده کنیم؟
اولین قدم برای کار با پانداس، نصب آن در پوشه پایتون است. برای انجام اینکار باید از دستور pip استفاده کنیم. در سیستمعامل ویندوز، پنجره خط فرمان را باز کرده، پوشه پایتون را باز کنید و به سراغ پوشهای بروید که python-pip در آن نصب شده است. پس از پیدا کردن پوشه مورد نظر، دستور را زیر را اجرا کنید:
Pip install pandas
پس از نصب پانداس، باید کتابخانه آنرا به برنامه خود وارد کنید. روند اضافه کردن ماژول فوق بهشکل زیر انجام میشود:
Import pandas as pd
در اینجا، pd بهعنوان نام مستعار پانداس شناخته میشود. البته، وارد کردن کتابخانه با استفاده از نام مستعار ضروری نیست و تنها با هدف کوتاه کردن کدنویسی در هنگام فراخوانی یک متد یا ویژگی مورد استفاده قرار میگیرد.
ساختارهای دادهای در پانداس
بهطور کلی، پانداس دو ساختار دادهای Series و DataFrame را برای دستکاری دادهها در اختیار برنامهنویسان قرار میدهد.
Series
سریها در پانداس آرایههای برچسبدار تک بعدی هستند که انواع مختلفی از دادهها مثل اعداد صحیح، رشتهها، مقادیر شناور، اشیاء پایتون و غیره را نگهداری میکنند. در اینجا، برچسبهای محور (Axis Labels) شاخص (Index) نامیده میشوند. این برچسبها لزومی ندارد منحصربهفرد باشند، بلکه باید از نوع قابل درهمسازی (Hashable) باشند. به بیان دقیقتر، سریهای پانداس شبیه به ستونها در صفحه اکسل هستند. اشیاء در پایتون از هر دو حالت شاخصگذاری مبتنی بر اشیاء و عدد صحیح پشتیبانی میکنند و مجموعهای از متدها را برای انجام عملیات شاخصگذاری در اختیار توسعهدهندگان قرار میدهند. شکل ۱، نمونهای از مجموعه دادهها از نوع سری را نشان میدهد.

نحوه ساخت یک سری
در دنیای واقعی، یک سری پانداس از طریق دانلود مجموعه دادهها از فضای ذخیرهسازی ایجاد میشود. این فضای ذخیرهسازی میتواند پایگاه داده SQL، فایل CSV یا یک فایل اکسل باشد. سری پانداس را میتوان از لیستها، دیکشنریها، از یک مقدار اسکالر و غیره ایجاد کرد. قطعه کد زیر، نحوه انجام اینکار را نشان میدهد.
import pandas as pd
import numpy as np
# Creating empty series
ser = pd.Series()
print(ser)
# simple array
data = np.array([‘g’, ‘e’, ‘e’, ‘k’, ‘s’])
ser = pd.Series(data)
print(ser)
خروجی قطعه کد فوق بهشرح زیر است:
Series([], dtype: float64)
0 g
1 e
2 e
3 k
4 s
dtype: object
DataFrame
دیتافریم پانداس، یک ساختار دادهای دوبعدی با اندازه متغیر، دادههای ناهمگن با محورهای برچسبدار (ردیفها و ستونها) است. فریمداده یک ساختار داده دو بعدی است، به این معنا که دادهها بهصورت جدولی در قالب ردیفها و ستونها تراز میشوند. DataFrame از سه مولفه اصلی، دادهها، ردیفها و ستونها تشکیل شده است. شکل 2، نمونهای از دادههای DataFrame را نشان میدهد.

شکل 2
به بیان دقیقتر، DataFrame را باید نسخه پیشرفتهتر سریها بنامیم، به این دلیل که توانایی نگهداری ستونها را دارد (شکل 3). همانگونه که مشاهده میکنید، DataFrames و Series کاملا شبیه به هم هستند، در نتیجه امکان اجرای بیشتر عملیات روی هر دو نوع وجود دارد.

شکل 3
نحوه ساخت یک DataFrame
دیتافریم نیز همانند سریها از طریق دانلود مجموعه دادهها از رسانه ذخیرهسازی ایجاد میشوند. به بیان دقیقتر، مهندس دادهها باید دادهها را جمعآوری و در مخزن دادهای ذخیرهسازی کند. در ادامه، دیتافریم را میتوان از طریق بهکارگیری لیستها، دیکشنریها و غیره ایجاد کرد. قطعه کد زیر نحوه انجام اینکار را نشان میدهد.
import pandas as pd
# Calling DataFrame constructor
df = pd.DataFrame()
print(df)
# list of strings
lst = [‘Geeks’, ‘For’, ‘Geeks’, ‘is’,
‘portal’, ‘for’, ‘Geeks’]
# Calling DataFrame constructor on list
df = pd.DataFrame(lst)
print(df)
خروجی قطعه کد فوق بهشرح زیر است:
Empty DataFrame
Columns: []
Index: []
0
0 Geeks
1 For
2 Geeks
3 is
4 portal
5 for
6 Geeks
چگونه باید دادهها را بخوانیم؟
دانلود دادهها از فایلها و انتقال آنها به یک دیتافریم ساده است. بهطور مثال، فرض کنید، در نظر داریم دادههای درون یک فایل CSV را خوانده و آنها را به یک دیتافریم انتقال دهیم. برای فایلهای CSV اینکار ساده و تنها با یک خط قابل انجام است.
df = pd.read_csv(‘purchases.csv’)
خروجی همانند شکل ۴ خواهد بود. نکتهای که باید درباره فایلهای CSV به آن دقت کنید این است که فایلهای فوق فاقد ویژگی شاخصهای دیتافریم هستند. بنابراین، باید هنگام خواندن اطلاعات از فایلهای CSV پارامتر index_col را مشخص کنیم.
df = pd.read_csv(‘purchases.csv’, index_col=0)
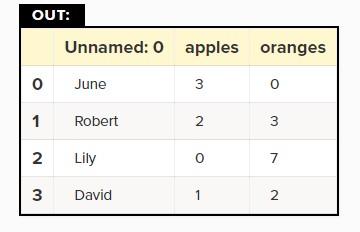
شکل 4
در این حالت، اطلاعات بهشکل خواناتر و دقیقتری وارد میشوند (شکل 5).
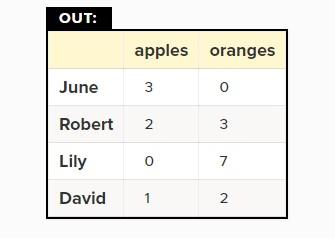
شکل 5
در اینجا ما شاخص را روی ستون صفر تنظیم کردیم. بهطور کلی، بیشتر CSVها فاقد ستون شاخص هستند و به همین دلیل نگرانی خاصی در این زمینه وجود ندارد.
خواندن دادهها از JSON
اگر یک فایل JSON دارید، پایتون میتواند اطلاعات درون این فایل را خوانده و به نوع دادهای دیکشنری انتقال دهد. در نتیجه یک مکانیزم قدرتمند برای کار با اطلاعات JSON ارائه میدهد.
df = pd.read_json(‘purchases.json’)
مزیتی که دادههای JSON دارند این است که فرآیند شاخصگذاری را بهشکل توکار انجام میدهند و نیازی نیست در این زمینه کار خاصی انجام دهیم. پانداس با تجزیهوتحلیل ساختار JSON یک دیتافریم ایجاد میکند، اما گاهیاوقات این فرآیند بهدرستی انجام نمیشود. برای حل این مشکل، کافی است از آرگومان کلمه کلیدی orient استفاده کنید.
خواندن دادهها از یک پایگاه داده SQL
اگر دادههایی دارید که درون یک پایگاه داده SQL ذخیرهسازی شده است، در این حالت باید یک کار اضافی انجام دهید. به این صورت که ابتدا از یک کتابخانه پایتون برای برقراری ارتباط با پایگاه داده SQL استفاده کنید، در ادامه، یک پرسوجو برای پانداس ارسال کنید. بهطور مثال، فرض کنید پایگاه داده SQLite را داریم. برای خواندن اطلاعات درون این پایگاه داده باید مراحل زیر را دنبال کنید.
ابتدا باید pysqlite3 را نصب کنیم. خط فرمان را باز کرده، به پوشه پایتون بروید و دستور زیر را اجرا کنید:
pip install pysqlite3
اگر از ژوپیتر نوتبوک استفاده میکنید، در سلولی دستور زیر را اجرا کنید:
!pip install pysqlite3
sqlite3 برای برقراری ارتباط با یک پایگاه داده استفاده میشود. بههمین دلیل، اولین کاری که باید انجام دهیم برقراری ارتباط با پایگاه داده و در ادامه ساخت یک دیتافریم با استفاده از کوئری SELECT است. برای برقراری ارتباط با یک فایل پایگاه داده SQLite از دستورات زیر استفاده میکنیم:
import sqlite3
con = sqlite3.connect(“database.db”)
در پایگاه داده فرضی SQLite، ما جدولی به نام purchases داریم و ایندکس ما در ستونی به نام index قرار دارد. در ادامه، باید محاوره خود را همراه با لینک اتصالی که ایجاد کردهایم بهشرح زیر فراخوانی کنیم:
df = pd.read_sql_query(“SELECT * FROM purchases”, con)
درست مانند فایلهای CSV، میتوانیم از index_col=’index' برای تنظیم موقعیت شاخص استفاده کنیم.
df = df.set_index(‘index’)
در واقع، میتوانیم از set_index در هر دیتافریم و روی هر ستونی استفاده کنیم. شاخصگذاری در سریها و دیتافریمها یکی از کارهای رایجی است که متخصصان علم دادهها باید انجام دهند. بههمین دلیل، باید دانش خود درباره شاخصگذاریها را افزایش دهید.
نحوه تبدیل CSV، JSON، یا SQL
پس از آنکه تمیزکاری روی دادهها را انجام دادید، آماده ذخیره دادهها در فایلهای دلخواه هستید. فرآیند نوشتن دادهها در فایلها مشابه خواندن آنها است. فرآیند ذخیره دادهها در فایلها به اشکال زیر انجام میشود:
df.to_csv(‘new_purchases.csv’)
df.to_json(‘new_purchases.json’)
df.to_sql(‘new_purchases’, con)
وقتی فایلهای JSON و CSV را ذخیره میکنیم، تنها کاری که هنگام فراخوانی توابع باید انجام دهیم، تعیین نام و فرمت فایلی است که اطلاعات باید در آن نوشته شوند. برای SQL، ما فایل جدیدی ایجاد نمیکنیم، بلکه یک جدول جدید را با استفاده از متغیر con که ارتباط با پایگاه داده را برقرار میکند به آن اضافه میکنیم.
چرا از پانداس استفاده میکنیم؟
پانداس بیشتر برای پروژههای یادگیری ماشین و علم دادهها استفاده میشود، اما بهدلیل اینکه امکان استفاده از آن همراه با کتابخانههای دیگر مورد استفاده در علم دادهها مثل نامپای وجود دارد، متخصصان علم دادهها از آن استفاده میکنند. دادههای تولیدشده توسط پانداس اغلب بهعنوان ورودی برای رسم توابع Matplotlib، تجزیهوتحلیل آماری در SciPy و الگوریتمهای یادگیری ماشین در Scikit-learn استفاده میشوند. توسعهدهندگان میتوانند از هر ویرایشگر متنی برای پانداس استفاده کنند، اما توصیه میشود از Jupyter Notebook استفاده کنید، زیرا ژوپیتر توانایی اجرای کدها در یک سلول خاص بهجای اجرای کل فایل را دارد. ژوپیتر راهی ساده برای مصورسازی فریمها، دیتافریمها و نمودارهای داده در پانداس ارائه میدهد.
پانداس چه قابلیتهایی در اختیار توسعهدهندگان قرار میدهد؟
تجزیهوتحلیل اکتشافی دادهها یکی از قابلیتهای مهم ارائهشده توسط پانداس است که امکان مقایسه دادههای عددی و طبقهبندی آنها را ارائه میکند. برای این منظور پانداس تکنیکهای مختلفی برای مصورسازی دادهها در اختیار برنامهنویسان قرار میدهد. پانداس قابلیت اعمال فیلتر روی ردیفها را ارائه میکند که فرآیند پیادهسازی محاورهها روی دادهها با هدف انتخاب زیرمجموعهها بر اساس شرایط منطقی را امکانپذیر میکند.
ترازبندی شاخص (Index Alignment) یکی دیگر از قابلیتهای مهمی است که پانداس در اختیار برنامهنویسان قرار میدهد تا به نتایج دقیقی دست پیدا کنند. گروهبندی با هدف دستیابی به تجمیع، تصفیه و تحلیل دادهها، یکی دیگر از قابلیتهایی است که پانداس در اختیار برنامهنویسان قرار میدهد و برای تجزیهوتحلیل دادهها ضروری است؛ بهطوری که امکان ساخت توابع سفارشی و اعمال آنها روی گروهها را بهوجود میآورد.
پانداس امکان بازسازی دوباره دادهها در یک Tidy Form را ارائه میکند. بهبیان دقیقتر به شما اجازه میدهد به اشکال مختلفی مجموعه دادههای غیرشفاف را بهشکل مرتبشده و ساختیافته تبدیل کرده و از آنها استفاده کنید. همچنین، تجزیهوتحلیل سریهای زمانی (Time Series Analysis) و قابلیتهای پیشرفته و قدرتمندی ارائه میکند که اجازه میدهد روی دادهها به روشهای مختلف کار کنید.
در نهایت، ویژگی اشکالزدایی و آزمایش اجازه میدهد تا مشکلات پیرامون دیتافریمها و کدهای پانداس را شناسایی کنید. اگر برنامهای برای استقرار پانداس در یک محیط تولیدی دارید، این ویژگی کاملا مفید خواهد بود.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.



















نظر شما چیست؟