




همانگونه که اشاره شد پردازش زبان طبیعی به معنای بهکارگیری کامپیوتر برای پردازش زبان گفتاری و زبان نوشتاری است. توسعهدهندگان سعی میکنند به کامپیوترها این توانایی را بدهند تا گفتار یا نوشتار تولید شده در قالب و ساختار یک زبان طبیعی را تحلیل و درک کند یا آنرا تولید نمایند. در این صورت، با استفاده از آن میتوان به ترجمه زبانها پرداخت، از صفحات وب و بانکهای اطلاعاتیِ نوشتاری جهت پاسخ دادن به پرسشها استفاده کرد، یا با دستگاهها، مثلاً برای مشورت گرفتن به گفتوگو پرداخت. اینها تنها مثالهایی از کاربردهای متنوع پردازش زبانهای طبیعی هستند.
هدف اصلی در پردازش زبان طبیعی، ایجاد تئوریهایی محاسباتی از زبان، با استفاده از الگوریتمها و ساختارهای دادهای موجود در علوم رایانه است. بدیهی است که در راستای تحقق این هدف، نیاز به دانشی وسیع از زبان است و علاوه بر محققان علوم رایانه، نیاز به دانش زبان شناسان نیز در این حوزه میباشد. با پردازش اطلاعات زبانی میتوان آمار مورد نیاز برای کار با زبان طبیعی را استخراج کرد. کاربردهای پردازش زبان طبیعی به دو دسته کلی قابل تقسیم است: کاربردهای نوشتاری و کاربردهای گفتاری. از کاربردهای نوشتاری آن میتوان به استخراج اطلاعاتی خاص از یک متن، ترجمه یک متن به زبانی دیگر یا یافتن مستنداتی خاص در یک پایگاه داده نوشتاری (مثلاً یافتن کتابهای مرتبط به هم در یک کتابخانه) اشاره کرد. نمونههایی از کاربردهای گفتاری پردازش زبان عبارتند از: سیستمهای پرسش و پاسخ انسان با رایانه، سرویسهای اتوماتیک ارتباط با مشتری از طریق تلفن، سیستمهای آموزش به فراگیران یا سیستمهای کنترلی توسط صدا. در سالهای اخیر این حوزه تحقیقاتی توجه دانشمندان را به خود جلب کردهاست و تحقیقات قابل ملاحظهای در این زمینه صورت گرفته است.
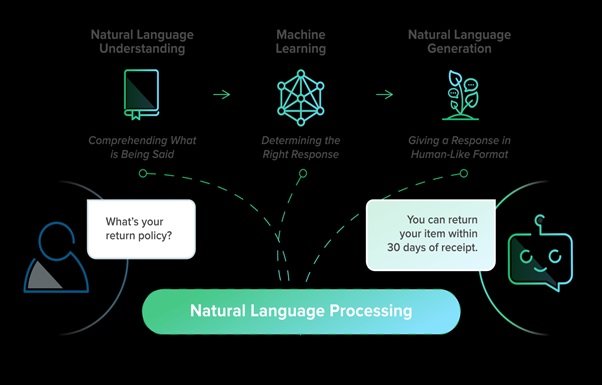
پردازش زبانهای طبیعی رهیافت بسیار جذابی برای ارتباط بین انسان و ماشین محسوب میشود و در صورت عملی شدنش بهطور کامل میتواند تحولات شگفتانگیزی را در پی داشتهباشد. سیستمهای قدیمی محدودی مانند SHRDLU که با واژههای محدود و مشخصی سر و کار داشتند، بسیار عالی عمل میکردند، بهطوریکه پژوهشگران را به شدت نسبت به این حوزه امیدوار کردهبودند. اما در تقابل با چالشهای جدیتر زبانی و پیچیدگیها و ابهامهای زبانها، این امیدها کمرنگ شدند. مسئله پردازش زبانهای طبیعی معمولاً یک مسئله AI-Complete محسوب میشود، چرا که محقق شدن آن بهطور کامل مستلزم سطح بالایی از درک جهان خارج و حالات انسان برای ماشین است.
چالشهای متعدد پیش روی زبان طبیعی
نیاز به درک معانی: رایانه برای آن که بتواند برداشت درستی از جملهای داشته باشد و اطلاعات نهفته در آن جمله را درک کند، گاهی لازم است که برداشتی از معنای کلمات موجود در جمله داشته باشد و تنها آشنایی با دستور زبان کافی نباشد. مثلاً جمله آلکس سیب را نخورد برای اینکه کال بود. و جمله آلکس سیب را نخورد برای اینکه سیر بود. ساختار دستوریِ کاملاً یکسانی دارند و تشخیص اینکه کلمات «کال» و «سیر» به «آلکس» برمیگردند یا به «سیب»، بدون داشتن اطلاعات قبلی درباره ماهیت «آلکس» و «سیب» ممکن نیست.
دقیق نبودن دستور زبانها: دستورِ هیچ زبانی آنقدر دقیق نیست که با استفاده از قواعد دستوری همیشه بتوان به نقش هریک از اجزای جملههای آن زبان پی برد.
پردازش زبانهای طبیعی آمارگرا
پردازش زبانهای طبیعی بهشکل آمارگرا عبارت است از استفاده از روشهای تصادفی، احتمالاتی و آماری برای حل مسائلی مانند آنچه در بالا ذکر شد. بهویژه از این روشها برای حل مسائلی استفاده میکنند که ناشی از طولانی بودن جملات و زیاد بودن تعداد حالات ممکن برای نقش کلمات هستند. این روشها معمولاً مبتنی بر نمونههای متنی و مدلهای مارکف هستند.
کاربردهای پردازش زبان طبیعی
پردازش زبان طبیعی کاربردهای مختلفی دارد که از مهمترین آنها به موارد زیر میتوان اشاره کرد:
خلاصهسازی خودکار
خلاصهسازی خودکار به عملیاتی گفته میشود که به وسیله یک برنامه کامپیوتری، باعث کاهش حجم متن و تولید خلاصهای حاوی مهمترین نکات و جملات مهم است. در دنیای امروز، حجم اطلاعات موجود بسیار زیاد است و این امر دسترسی ما به دادهها را پیچیده میکند؛ بنابراین لازم است روشی پیدا کنیم که دسترسی به اطلاعات مورد نظر را ساده کند. بهترین روش خلاصه کردن و سپس طبقهبندی اطلاعات است. همه ما از خلاصهسازی به صورتهای گوناگون استفاده میکنیم. از مهمترین کاربردهای خلاصهسازی میتوان به موتورهای جستجو گر وب، ارسال اخبار به صورت فشرده و کوتاه، و جمعبندی نتایج تحقیق و مقاله اشاره کرد. سیستم خلاصهسازی شامل یک کامپیوتر است که متنی را به عنوان ورودی دریافت میکند و خلاصه آن را به شکل خروجی تحویل میدهد. در حالت کلی خلاصهسازی در قالب چگونگی پردازش، مخاطب و متن، اطلاعات ورودی، سبک، نوع کاربر و چگونگی پردازش خلاصهسازی طبقهبندی میشود.
استخراج اطلاعات
استخراج اطلاعات (Information extraction) به عملیات استخراج خودکار اطلاعات ساختار یافته، از اسناد و مدارک قابل خواندن بدون ساختار یا نیمه ساختار یافته اطلاق میگردد. بخش اعظم فعالیتهای استخراج اطلاعات مربوط به پردازش متون توسط روش پردازش زبانهای طبیعی میباشد. امروزه فعالیتهای مربوط به پردازش اسناد چندرسانهای مانند حاشیهنویسی خودکار، استخراج متون و مطالب از تصاویر، فایلهای صوتی و کلیپهای ویدیویی، از تکنیکهای استخراج اطلاعات بشمار میآیند. پیشینه استخراج اطلاعات به اواسط دهه ۱۹۸۰ بازمیگردد، که یک سیستم معاملاتی جایگزین تحت نام تجاری JASPER برای رویترز ساخته شد. این سیستم با هدف ارائه اخبار مالی در زمان واقعی به معامله گران مالی طراحی شده بود.
بازیابی اطلاعات
بازیابی اطلاعات (Information Retrieval) فعالیت بدست آوردن منابع سیستم اطلاعاتی که مربوط به اطلاعات لازم از یک مجموعه است را میگویند. جستجوها میتوانند برپایه جستجوی تمام متن یا سایر جستجوهای مبتنی بر محتوا نمایه گذاری شوند. بازیابی اطلاعات علم جستجو اطلاعات در یک سند، جستجو برای خود سندها، جستجو برای فرادادهها که دادهها را توصیف میکنند و برای پایگاه داده های متنی، عکسی یا آوایی است. سیستمهای بازیابی اطلاعات خودکار برای کاهش چیزی که آن را سرریز دادهها (اضافهبار اطلاعات) میگوییند، استفاده میشوند. سیستم بازیابی اطلاعات نرمافزاری است که دسترسی، ذخیره و مدیریت کتابها، مقالات و دیگر سندها را فراهم میکند. موتورهای جستجوگر وب (موتور جستجوی وب) از قابل مشاهدهترین برنامههای کاربردی بازیابی اطلاعات هستند.
با افزایش روزافزون حجم اطلاعات ذخیرهشده در منابع قابل دسترس و گوناگون، فرایند بازیابی و استخراج اطلاعات اهمیت ویژهای یافتهاست. اطلاعات مورد نظر ممکن است شامل هر نوع منبعی مانند متن، تصویر، صوت و ویدئو باشد. بر خلاف پایگاه دادهها، اطلاعات ذخیره شده در منابع اطلاعاتی بزرگ مانند وب و زیرمجموعههای آن مانند شبکههای اجتماعی از ساختار مشخصی پیروی نمیکنند و عموماً دارای معانی تعریف شده و مشخصی نیستند. هدف بازیابی اطلاعات در چنین شرایطی، کمک به کاربر برای یافتن اطلاعات موردنظر در انبوهی از اطلاعات ساختار نایافتهاست.
جستجوگرهای گوگل، یاهو و بینگ سه نمونه از پراستفادهترین سیستمهای بازیابی اطلاعات هستند که به کاربران برای بازیابی اطلاعات متنی، تصویری، ویدئویی و غیره کمک میکنند. لازم به توضیح است که تفاوت بازیابی داده و بازیابی اطلاعات دو مفهوم متفاوت از هم هستند. دادهها ابهام ندارند، اما اطلاعات نیاز به تفسیر دارد و در نتیجه مبهم میشوند. سیستمی که برای بازیابی داده طراحی شده نیازی به رفع این ابهامها ندارد، اما در سیستم بازیابی اطلاعات باید هر چه بهتر اطلاعات را مدل کرد تا ابهام در درک اطلاعات توسط سیستم کمتر شوند. به همین علت بر خلاف سیستمهای بازیابی داده که در آن کارایی سیستم از نظر سرعت و فضا به عنوان معیار ارزیابی در نظر گرفته میشود، در سیستمهای بازیابی اطلاعات، معیار دقت (precision) و بازخوانی (recall) و معیارهایی شبیه به آنها به عنوان معیارهای اصلی ارزیابی به کار میروند.
ترجمه ماشینی
ترجمه ماشینی (Machine translation) زیر شاخهای از زبانشناسی محاسباتی است که نحوه استفاده از نرمافزار برای ترجمه متن یا گفتار از یک زبان به زبان دیگر را بررسی میکند. در سطح مقدماتی، ترجمه ماشینی یک جایگزینی ساده برای کلمات از زبان طبیعی به زبان دیگری است. با استفاده از تکنیکهای زبانشناسی پیکرهای، ترجمههای پیچیده بیشتری قابل دستیابی هستند. همچنین این تکنیکها کنترل بهتر تفاوتهای گونهشناسی در زبان، تشخیص عبارات و ترجمه اصطلاحات را به خوبی و درستی جدا کردن عبارات نامتعارف در متن، مقدور میسازند. نرمافزارهای ترجمه ماشینی کنونی اغلب به کاربر اجازه تغییر دلخواه بر اساس حوزه کاری یا حرفهای دلخواه را میدهند (همانند گزارش آب و هوا). در واقع ارتقاء کیفیت خروجی با استفاده از محدود کردن کلمات جایگزین شونده، انجام میشود. این تکنیک بهطور خاص در حوزهٔ رسمی یا زبانهای فرموله شدهاستفاده میشود. این بدین معنی است که ترجمه ماشینی از اسناد قانونی و دولتی آسانتر از تولید خروجی قابل استفاده از مکالمات یا متون غیر چهارچوب بندی شده دیگر است. همچنین کیفیت خروجی بهبود یافته میتواند با استفاده از دخالت انسان بدست آید. برای مثال سیستمهایی موجودند که اگر کاربر بهطور کاملاً واضحی کلماتی که اسامی خاص هستند را معین کرده باشد، قادر به ترجمه دقیقتری هستند. با کمک گرفتن از این تکنیکها ترجمه ماشینی به عنوان یک ابزار برای کمک کردن به مترجمان (انسانها) و بسیاری از موضوعهای محدود، قادر به تولید خروجی قابل استفاده و نهایی است.
اسکن نوری مطالب
اسکن نوری مطالب که بهنام نویسه خواننوری معروف است و بیشتر منابع از OCR برای توصیف آن استفاده میکنند عبارت است از تشخیص (recognition) خودکار متون موجود در تصاویر اسناد و تبدیل آنها به متون قابل جستجو و ویرایش توسط رایانه. تصویر سند غالباً توسط روبشگر یا دوربین دیجیتال تولید میشود. این تصاویر شامل تعدادی پیکسل با رنگهای مختلف است که هر رنگ با ترکیب سه رنگ اصلی سبز، آبی و قرمز ساخته میشوند. از دید انسان، یک سند ممکن است ارزش اطلاعاتی زیادی داشته باشد، لیکن از دید رایانه تصویر یک سند با تصویر یک منظره تفاوتی ندارد، چرا که هر دوی آنها مجموعهای از پیکسلها هستند. برای اینکه بتوان از اطلاعات نوشتاری تصویر سند استفاده کرد، بایستی به نحوی نوشتههای موجود در سند را تشخیص دهیم. چنین کاری توسط نرمافزارهای نویسه خوان نوری انجام میشود.
نویسهخوان نوری ابتدا تنها در مورد بازشناسی ارقام و حروف چاپی بکار گرفته میشد. سامانه نویسه خوان مثل یک نفر ماشیننویس، متن سند را میخواند و آن را به قالب مناسب برای ذخیره در رایانه تبدیل میکند. معمولاً اسکنر، تصاویر مورد نیاز برای تشخیص نویسه را فراهم میآورند. سامانه نویسهخوان، اشیاء موجود در تصویر سند را که ارقام، حروف، علائم و کلمات هستند، بازشناسی کرده و رشتهی متناظر با آنها را در قالب مناسب ذخیره میکند. یک فایل تصویری، حجم زیادی دارد و جستجوی متنی در آن ممکن نیست. این در حالی است که فایل خروجی سامانه نویسه خوان بسیار کم حجم و قابل جستجو است. سامانههای نویسه خوان مثل بسیاری از سامانههای هوشمند دیگر، پیچیدگی زیادی دارد. پردازش تصویر و بازشناسی الگو دو مبحث اصلی در این سامانهها هستند. پیچیدگی این سامانهها برای زبانهای گوناگون، متفاوت است. به عنوان مثال نوشتن نویسه خوانی نوری برای زبانهای لاتین به دلیل اینکه حروف آنها بهطور مجزا نوشته میشود آسانتر است از زبانهایی مثل فارسی و عربی که حروف یک کلمه به یکدیگر میچسبند. این موضوع به علاوه جمعیت کم کاربران زبان فارسی، سبب شده سامانههای نویسه خوان زبان فارسی نقاط ضعف زیادی داشته باشند. البته در سالهای اخیر تلاشهای قابل تقدیری از سوی برخی شرکتهای فعال در زمینه پردازش تصویر انجام شده که برخی از آنها منجر به محصولات قابل قبولی شدهاست.
بازشناسی گفتار
هدف از تشخیص گفتار که در متون علمی بیشتر با نام بازشناسی گفتار شناخته شدهاست، طراحی و پیادهسازی سیستمی است که اطلاعات گفتاری را دریافت و متن و فرمان گوینده را استخراج میکند. فناوری بازشناسی گفتار به رایانهای که توانایی دریافت صدا را دارد (برای مثال به یک میکروفن مجهز است) این قابلیت را میدهد که گفتار کاربر را متوجه شود. فناوری تبدیل گفتار به متن ممکن است به عنوان جایگزینی برای صفحه کلید یا ماوس برای وارد کردن دستورها مورد استفاده قرار گیرد. سیستمهای واکافتکننده گفتار انواع مختلفی دارند، بعضی قادرند گفتار پیوسته را شناسایی نمایند، بعضی دیگر فقط میتوانند گفتار گسسته (که بین کلمات سکوت وجود دارد) را شناسایی کنند. همچنین سیستمها قادرند واژگان گفته شده توسط افراد مختلف یا فقط توسط یک گوینده را تشخیص دهند. به هر حال ایدهآلترین سیستم آن است که بتواند گفتار پیوسته غیر وابسته به گوینده را در محیط نویزی شناسایی نماید. این سیستمها با بکارگیری روشهای مختلف طبقهبندی و شناسایی الگو قادرند به تشخیص واژگان هستند که البته برای افزایش دقت در شناسایی از یک فرهنگ لغات نیز در انتهای سیستم استفاده میشود. روشهایی مانند Hidden Markov Model یا Neural Network در بسیاری از سیستمهای تشخیص گفتار مورد استفاده قرار میگیرند و در بخشهای انتهایی سیستم از هوش مصنوعی کمک گرفته میشود. یک سیستم بازشناسی گفتار خودکار (Automatic Speech Recognition) که به اختصار ASR نامیده میشود با چالشهای فراوانی روبروست. از جمله مهمترین این چالشها میتوان به وجود نویز، انتخاب مجموعه ویژگیهای مناسب، انتخاب مدل آکوستیکی مناسب، تنوع زبان، تنوع جنسیت و مشکل لهجه در بازشناسی گفتار اشاره نمود. در مورد زبانهای رایج مانند انگلیسی کارهای زیادی در جهت مقابله با این چالشها انجام شدهاست اما در مورد زبان فارسی هنوز راه زیادی در پیش است. تشخیص کلمات کلیدی گفتار به معنای پیدا کردن یک کلمه یا عبارت خاص در گفتار میباشد که برای کاربردهای امنیتی، آرشیوهای صوتی و جستجوی صوتی قابل استفادهاست. نسخههای تلفنی و غیر تلفنی این نرمافزار آماده شدهاست و تحقیق برای بهبود آن ادامه دارد.
برای آمادهسازی یک سیستم واقعی، معیار اطمینان یکی از پارامترهای مهم میباشد. به کمک معیار اطمینان میتوان دقت را در موارد خاص بررسی نمود یا در هنگام آموزش از این ویژگی استفاده نمود. کاربرد دیگر معیار اطمینان در بدست آوردن کلمات خارج از دادگان است. کلمات خارج از دادگان یکی از پارامترهای اصلی سیستمهای تشخیص فرامین صوتی میباشد. ویرایشگری یا ویراستاری یا ادیتوری به فرایند انتخاب و آمادهسازی محصولات نوشتاری، دیداری، تصویری، شنیداری، و رسانهایِ برای انتقال اطلاعات میگویند. در فرایند ویرایش ممکن است تصحیح، تلخیص (خلاصهسازی)، ساماندهی و بسیاری از تغییرات دیگر به قصد تولیدِ اثری منسجم، یکدست، درست، دقیق و کامل صورت گیرد. به شخصی که ویرایش میکنند ویرایشگر یا ویراستار میگویند.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.























نظر شما چیست؟