








بیشتر بانکهای اطلاعاتی که کسبوکارها از آنها استفاده میکنند شامل دادههای ساختیافتهای متشکل از فیلدهای عددی و مقادیر عددی+الفبا هستند، در حالی که پایگاههای اطلاعاتی علمی ممکن است شامل هر سه فیلد باشند.
نمونههایی از دادههای نیمه ساختاری، تصاویر الکترونیکی اسناد تجاری، گزارشات پزشکی، خلاصه گزارشهای مدیریتی و دفترچههای راهنما هستند. اکثر اسناد وب نیز در این گروه قرار میگیرند. از دادههای بدون ساختار میتوان به ویدئوییهایی که توسط دوربینهای مداربسته در یک فروشگاه بزرگ ضبط میشوند اشاره کرد. کاهش قیمت تجهیزات نظارت تصویری تحت شبکه باعث شده تا کسبوکارهای مختلف از این دوربینها در فروشگاهها استفاده کنند، به همین دلیل شاهد افزایش دادههای بدون ساختاری هستیم که توسط دوربینهای ویدویی ضبط میشوند. بهطور کلی برای استخراج اطلاعات از چنین دادههایی به کار بیشتر و پردازشهای گستردهتر نیاز است.
دادههای ساختاری اغلب به عنوان دادههای سنتی شناخته میشوند، در حالی که دادههای نیمه ساختاری و غیر ساختاری به صورت دادههای غیر سنتی (دادههای چندرسانهای نامیده میشوند) در دسترس ما قرار دارند. بیشتر روشهای فعلی دادهکاوی و ابزارهای تجاری برای کار با دادههای سنتی توسعه پیدا کردهاند. با این حال، توسعه ابزارهای دادهکاوی برای دادههای غیر سنتی و رابطهای تبدیل این مدل اطلاعات به قالبهای ساختاریافته با سرعت زیادی در حال پیشرفت است.
در مدل استاندارد دادههای ساخت یافته که برای دادهکاوی استفاده میشود، مجموعهای مشخص از ویژگیها وجود دارند. در دنیای دادهکاوی اندازهگیریهای بالقوه بهنام ویژگیها شناخته میشوند و بهطور کلی در بیشتر موارد به شکل یکسان اندازهگیری میشوند. بهطور معمول، نمایش دادههای ساخت یافته در قالب جدولی یا در قالب یک رابطه واحد (اصطلاحی که در ارتباط با پایگاه دادههای رابطهای استفاده میشود) انجام میشود، در این حالت ستونها ویژگیهای اشیا ذخیره شده در جدول هستند و سطرها مقادیر این ویژگیها برای نهادهای خاص هستند. نمایش گرافیکی ساده یک مجموعه دادهای و مشخصات آن در شکل زیر مشخص است.
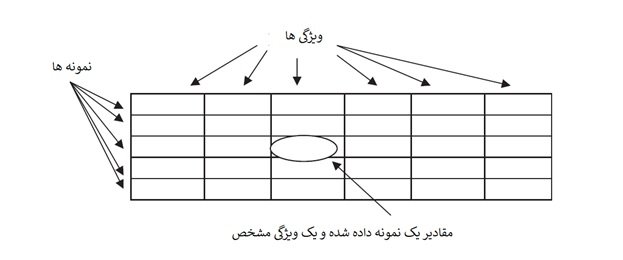
در ادبیات دادهکاوی، بهطور معمول از اصطلاحات نمونهها یا موارد برای توصیف سطرها استفاده میکنیم. انواع مختلفی از ویژگیها (خصلتها یا متغیرها) به عنوان مثال، زمینهها - در رکوردهای دادههای ساختاریافته در داده کاوی وجود دارد. با اینحال به این نکته مهم دقت کنید که تمامی الگوهای دادهکاوی در تعامل با ویژگیها عملکرد یکسانی ندارند و باید در جای درست از آنها استفاده کرد. روشهای مختلفی برای توصیف ویژگیها وجود دارد. یکی از روشهای رایج بررسی یک ویژگی که بیشتر با اصطلاح متغیر از آن نام برده میشود این است که ببینیم متغیر مستقل است یا وابسته، یعنی اینکه آیا متغیری است که مقادیر آن وابسته به مقادیر دیگر متغیرهای نشان داده شده در یک مجموعه دادهای وابسته هستند یا خیر. این یک روش مبتنی بر مدل برای طبقهبندی متغیرها است. همه متغیرهای وابسته به عنوان خروجی سیستمی که ما برای آن مدلی ایجاد میکنیم پذیرفته میشوند و متغیرهای مستقل ورودی به سیستم هستند، همانگونه که شکل زیر نشان میدهد.

یک سیستم واقعی، علاوه بر متغیرهای ورودی (مستقل) X و (وابسته) خروجی Y ، اغلب دارای ورودیهای مشاهده نشده Z است.
نکته مهمی که باید به آن دقت کنید این است که برخی متغیرهای اضافی وجود دارند که بر رفتار سیستم تأثیرگذار هستند، اما مقادیر مربوطه در یک مجموعه داده در طی یک فرآیند مدلسازی در دسترس نیستند. دلایل مختلفی باعث پدید آمدن این مشکل هستند که از آن جمله باید به پیچیدگی بالا، هزینه زیاد اندازهگیری ویژگیها، عدم دانش و درک عمیق مدلساز در ارتباط با اهمیت برخی از عوامل و تأثیر آنها بر روی مدل اشاره کرد. این مدل ویژگیها بهنام متغیرهای مشاهده نشده شناخته میشوند که عامل اصلی شکلگیری مدلی میشوند که نتایج اشتباهی را ارائه میکند. ویژگیهای شناخته نشده بهنام دادههای گمشده نیز توصیف میشوند.
کامپیوترهای امروزی و ابزارهای نرمافزاری ارائه شده این ظرفیت را دارند تا مجموعه دادههایی متشکل از میلیونها نمونه و صدها ویژگی را پردازش کنند. مجموعه دادههای بزرگ شامل مجموعههایی که نوعهای دادهای ترکیبی را شامل میشوند محیط ایدهآلی را پدید میآورند که مناسب برای بهکارگیری تکنیکهای دادهکاوی مناسب هستند.
وقتی مقدار زیادی داده در کامپیوتری ذخیره میشود، نمیتوان به سرعت به سراغ تکنیکهای دادهکاوی رفت، زیرا ابتدا باید مشکل مهم کیفیت دادهها حل شود. علاوه بر این، بدیهی است که تجزیه و تحلیل کیفیت به شیوه دستی در این مرحله فراهم نیست. بنابراین، تهیه تجزیه و تحلیل کیفیت دادهها در مراحل اولیه فرآیند دادهکاوی ضروری است. بهطور معمول این فرآیند باید در مرحله پیشپردازش دادهها انجام شود.
تحلیل کیفی دادهها تأثیر عمیقی بر تصویر سیستم دارد و مدل متناظر را که بهطور ضمنی توصیف میشود را مشخص میکند. با استفاده از تکنیکهای موجود دادهکاوی، به سختی میتوان تغییرات عمده کیفی در سازمانی که اطلاعات با کیفیت پایین تولید میکند را تشخیص داد. علاوه بر این، شناسایی جدید در دادههای علمی بدون کیفیت تقریباً غیرممکن است. شاخصهای کیفی مختلفی در ارتباط با دادهها وجود دارند که باید در مرحله پیشپردازش دادهکاوی به آنها دقت کنید. برخی از آنها به شرح زیر هستند:
1. دادهها باید دقیق باشند. تحلیلگر باید بررسی کند که آیا نامها به درستی تلفظ شدهاند، کد در یک محدوده مشخص است، مقدار کامل است و غیره.
2. دادهها باید در نوعهای دادهای مناسب ذخیره شده باشند. تحلیلگر باید اطمینان حاصل کند که مقدار عددی به صورت کاراکتر ارائه نشده است، اعداد صحیح (integer) هستند و به شکل واقعی (Real) نیستند و غیره.
3. دادهها باید یکپارچه باشند. بهروزرسانیها نباید نادیده گرفته شوند، زیرا کاربران مختلف ممکن است تغییراتی در دادهها اعمال کنند. اگر مکانیزمی به شکل پیشفرض از طریق سامانه مدیریت پایگاه دادهها (DBMS) در دسترس نیست، ضروری است که بهطور منظم از دادهها نسخه پشتیبان تهیه شود که در صورت لزوم دادهها بازیابی شوند.
4- دادهها باید سازگار باشند. شکل و محتوا باید پس از ادغام مجموعه دادههای بزرگ از منابع مختلف یکسان باشند.
5- دادهها نباید زائد باشند. در عمل، دادههای زائد باید به حداقل برسند، تکرارها کنترل شوند یا رکوردهای تکراری حذف شوند.
6. دادهها باید در زمان درست استفاده شوند. مولفه زمانی دادهها باید بهطور صریح از طریق دادهها یا بهطور ضمنی و به شیوه دستی از طبقهبندی دادهها تشخیص داده شود.
7. دادهها باید به خوبی درک شوند. استانداردهای نامگذاری شرط لازم هستند، اما به تنهایی برای درک دادهها کافی نیستند. کاربر باید بداند که دادهها با متناظر با دامنهای هستند که آنها را منتشر کرده است.
8- مجموعه دادهها باید کامل باشد. نرخ از دست رفتن دادهها باید به حداقل برسد. از دست رفتن دادهها میتواند کیفیت مدل را کاهش دهد. با اینحال، برخی از تکنیکهای دادهکاوی برای پشتیبانی از تجزیه و تحلیل مجموعه دادهها حتا با مقادیر از دست رفته عملکرد خوبی دارند.
موضوع مهمی که باید بررسی کنید این است که چگونه مشکل دادههای با کیفیت پایین را برطرف کنید، بنابراین ضروری است که همواره به دنبال بهترین الگوها باشید، به ویژه زمانی که در حال پردازش اولیه داده ها هستید. این فرایندها اغلب با استفاده از فناوری انباره دادهها انجام میشود.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.























نظر شما چیست؟