




انواع شبکههای عصبی مصنوعی
در حالت کلی شبکههای عصبی بر مبنای یک معماری چند لایه دادهها را پردازش و خروجی مناسب را ارائه میکنند. به بیان سادهتر، در هر لایه، پردازش یا پیشپردازشی روی دادهها انجام میشود و نتیجه برای لایه بعدی ارسال میشود، با اینحال، عملکرد تمامی شبکههای عصبی اینگونه نیست و هر یک بر مبنای کارکردی که برای آنها تعریف شده از نوع خاصی از همبندی برای پردازش اطلاعات استفاده میکنند.
شبکه عصبی پرسپترون
پرسپترون (Perceptron) سادهترین و قدیمیترین نوع شبکههای عصبی است (شکل 1). پرسپترون تعدادی ورودی را دریافت، آنها را ترکیب و تابع فعالسازی روی آنها اجرا میکند و در نهایت نتایج را برای لایه خروجی ارسال میکند. شبکههای عصبی پرسپترون چندلایه، متشکل از یک لایه ورودی، لایههای نهان و لایه خروجی هستند. در این شبکهها گرههای شبکه عصبی که سلول عصبی نامیده میشوند واحدهای محاسباتی هستند. در شبکههای عصبی پرسپترون چندلایه، خروجیهای لایه اول به عنوان ورودیهای لایه نهان استفاده میشوند و این روند ادامه پیدا میکند تا وقتی که خروجی آخرین لایه یا لایههای نهان به عنوان ورودی لایه خروجی استفاده شود. در این شبکهها به لایههایی که میان لایه ورودی و لایه خروجی قرار میگیرند لایه نهان (Hidden Layers) گفته میشود.
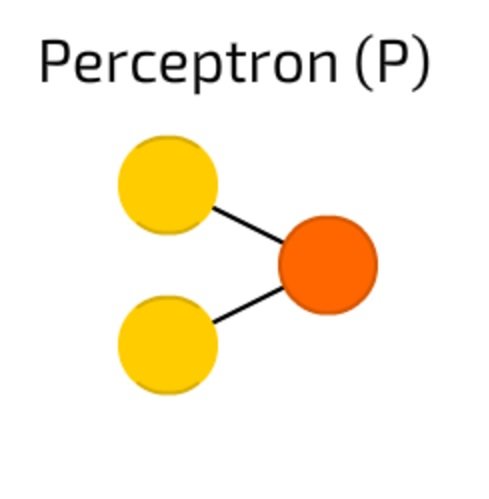
شکل 1
شبکه عصبی پیشخور
شبکههای عصبی پیشخور (Feed Forward Neural Networks) قدمتی بیش از 50 سال دارند و همانند شبکه عصبی پرسپترون یکی از قدیمیترین شبکههای عصبی به شمار میروند (شکل 2). معماری این شبکههای عصبی به این گونه است که تمامی گرهها بهطور کامل به یکدیگر متصل هستند. در این شبکهها فعالسازی از لایه ورودی به خروجی بر مبنای یک لایه پنهان میان ورودی و خروجی و بدون آنکه مشکل حلقه رو به عقب به وجود آید انجام میشود. در بیشتر موارد، برای آموزش شبکههای عصبی پیشخور از رویکرد پسانتشار (Backpropagation) استفاده میشود.
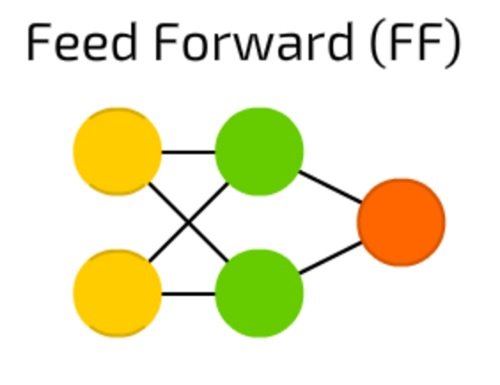
شکل 2
شبکه عصبی شعاعی پایه
شبکههای عصبی شعاعی پایه (Radial Basis Networks) نوع بهبودیافته شبکههای عصبی پیشخور هستند که برای عملکرد بهتر از تابع شعاعی پایه به جای تابع لجستیک به عنوان تابع فعالساز استفاده شده است
(شکل 3). شبکههای عصبی پیشخور و شعاعی چه تفاوتی با یکدیگر دارند؟ تابع لجستیک برخی از مقادیر دلخواه را به یک بازه صفر تا یک نگاشت میکند تا بتواند به یک پرسش بله یا خیر پاسخ دهد. این مدل شبکههای عصبی برای طبقهبندی (Classification) و سامانههای تصمیمگیر(Making Systems) مناسب هستند، در نتیجه زمانی که قرار است از مقادیر پیوسته در این شبکهها استفاده شود، دیگر سودبخش نیستند. در نقطه مقابل، توابع شعاعی پایه برای پاسخگویی به این پرسش استفاده میشوند که چقدر از هدف دور هستیم؟ شبکههای عصبی شعاعی پایه برای تخمین تابع و کنترل ماشین (به عنوان جایگزینی برای کنترلکننده PID) مناسب هستند. در مجموع باید بگوییم که شبکههای شعاعی پایه نوع بهبودیافته شبکههای عصبی پیشخور با تابع فعالساز و ویژگیهای متفاوت هستند.
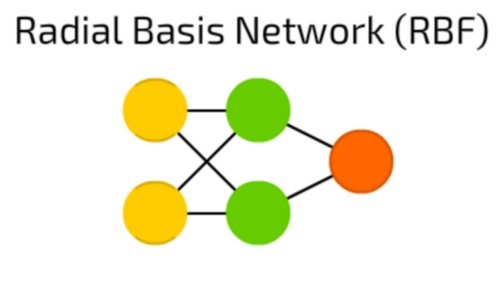
شکل 3
شبکه عصبی پیشخور عمیق
شبکه عصبی پیشخور عمیق (Deep Feed Forward Neural Networks) اوایل دهه 90 میلادی پدید آمدند (شکل 4). این شبکههای عصبی شبیه به شبکههای عصبی پیشخور هستند با این تفاوت که بیش از یک لایه پنهان در آنها تعبیه شده است. این شبکههای عصبی چه تفاوتی با شبکههای عصبی پیشخور قدیمی دارند؟ در زمان آموزش شبکه عصبی پیشخور، تنها بخش کوچکی از خطا به لایه عقب ارسال میشود. با توجه به اینکه از لایههای زیادی در این شبکهها استفاده میشود، شاهد رشد نمایی زمان آموزش این شبکهها هستیم که باعث میشود شبکههای عصبی پیشخور عمیق چندان کاربردی نباشند. اوایل سال 2000 میلادی تلاش شد تا مشکلات اساسی این شبکهها برطرف شود و امکان آموزش یک شبکه عصبی پیشخور عمیق (DFF) به شکل کارآمدتری انجام شود. امروزه شبکههای عصبی پیشخور عمیق، پایه و اساس سامانههای یادگیری ماشین مدرن را شکل میدهند و نتایجی در حد شبکههای عصبی پیشخور را ارائه میکنند، و حتی در اغلب موارد نتایج بهتری نسبت به آنها ارائه میکنند.
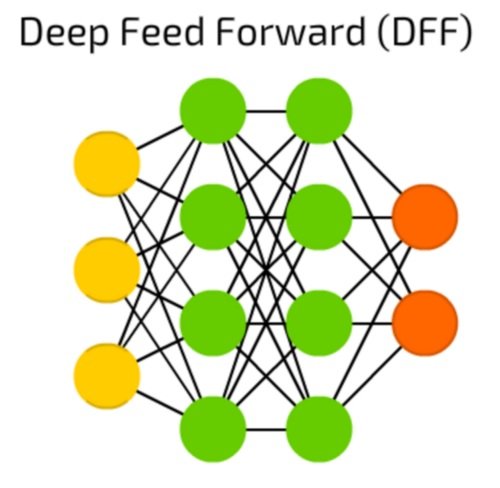
شکل 4
شبکههای عصبی بازگشتی
شبکههای عصبی بازگشتی (Recurrent Neural Networks) مفهوم جدیدی بهنام سلولهای بازگشتی (Recurrent Cells) را به دنیای هوش مصنوعی و شبکههای عصبی وارد کردند (شکل 5). اولین شبکه عصبی بازگشتی که شبکه جردن نام داشت بر مبنای این معماری کار میکرد که هر یک از سلولهای پنهان، ورودی و خروجی خود را با بر مبنای یک یا چند مرحله تکرار و با تاخیر ثابت دریافت/ارسال میکردند. صرفنظر از این موضوع، شبکه جردن عملکردی مشابه با شبکههای عصبی پیشخور رایج داشت. با اینحال، تغییرات مختلفی نظیر هدایت حالت به گرههای ورودی، تاخیر متغیرها و موارد این چنینی در شبکههای عصبی بازگشتی اعمال شد، اما در حالت کلی معماری و عملکرد آنها خط سیر مشخصی دارد. این نوع شبکههای عصبی زمانی استفاده میشوند که زمینه (Context) مهم باشد. در این حالت هنگامی که تصمیمگیریها بر مبنای تکرارهای قبلی یا نمونهها اتخاذ شود، روی نمونههای کنونی تاثیرگذار میشوند. رایجترین مثالی که در ارتباط با زمینهها میتوان به آن اشاره کرد متن است. در متن یک کلمه را میتوان تنها در زمینه کلمه یا جمله پیشین تحلیل کرد. امروزه، چنین رویکردی در ارتباط با شناسایی هرزنامهها از ایمیلهای عادی توسط ارائهدهندگان خدمات ایمیلی استفاده میشود.

شکل 5
حافظه کوتاهمدت بلند
حافظه کوتاهمدت بلند (Long/Short Term Memory) نوع جدیدی از سلول حافظه را معرفی میکند (شکل 6). این سلول میتواند دادهها را هنگامی که شکاف زمانی وجود دارد پردازش کند. شبکه عصبی پیشخور میتواند متن را با به خاطر سپردن ده کلمه قبلی پردازش کند. با اینحال، شبکههای مبتنی بر حافظه کوتاهمدت/بلندمدت قادر هستند قابهای ویدیویی را با به خاطر سپردن حالتی که در قابهای قبلتر اتفاق افتاده پردازش کنند. این مدل شبکهها بهطور گستردهای در ارتباط با بازشناسی گفتار و بازشناسی رفتار استفاده میشوند. سلولهای حافظه متشکل از یک جفت عنصری هستند که به آنها دروازه گفته میشود. این عناصر قابلیت بازگشتی دارند و چگونگی به یاد آوردن و فراموش کردن اطلاعات را کنترل میکنند. برای درک بهتر موضوع به شکل 7 دقت کنید. ایکسهای موجود در نمودار، دروازه هستند و وزن و گاهی اوقات تابع فعالساز دارند. بهطور مثال، ایکسها تصمیم میگیرند که دادهها به جلو هدایت شوند یا خیر، حافظه را پاک کنند یا خیر و کارهای این چنینی را انجام دهند. دروازه ورودی، تصمیم میگیرد که چه میزان اطلاعات از آخرین نمونه در حافظه نگهداری شود. دروازه خروجی نرخ دادههای انتقال داده شده به لایه بعد را تنظیم میکند، در حالی که دروازه فراموشی، نرخ خارج شدن دادهها از حافظه را کنترل میکند.
شکل 6
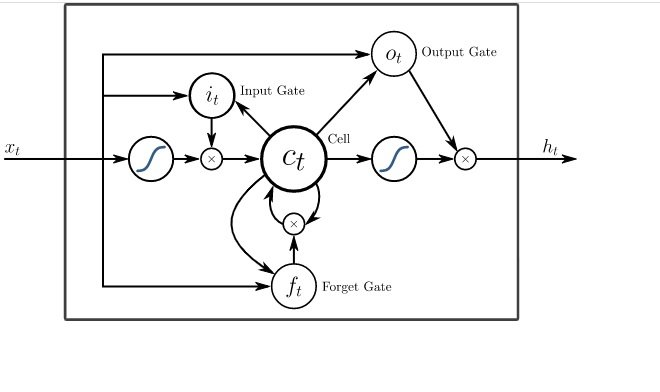
شکل 7
شبکه عصبی واحد بازگشتی دروازهای
واحد بازگشتی دروازهای (Gated Recurrent Unit) نوع خاصی از شبکههای LSTM با دروازهها و بازه زمانی متفاوت است (شکل 8). این نوع از شبکههای عصبی عملکرد نسبتا سادهای دارند. امروزه این مدل شبکههای عصبی بازگشتی بیشتر در موتور متن به گفتار و ترکیب صدا استفاده میشوند. برخی متخصصان هوش مصنوعی بر این باور هستند که شبکه عصبی واحد بازگشتی دروازهای اندکی متفاوت از حافظه کوتاهمدت/بلندمدت هستند، زیرا تمامی دروازههای شبکه LSTM در یک دروازه که به آن دروازه بهروزسانی گفته میشود ترکیب میشوند و دروازه بازشناسی (Rest) در نزدیکی گره ورودی قرار دارد. علاوه بر این شبکههای GRU نسبت به LSTM از منابع کمتری استفاده میکنند، اما عملکرد یکسانی با LSTM دارند.
شکل 8
شبکه عصبی خودرمزگذار
شبکههای عصبی خودرمزگذار (Auto Encoder) برای دستهبندی، خوشهبندی و فشردهسازی ویژگیها استفاده میشوند (شکل 9). هنگامی که یک شبکه عصبی پیشخور برای طبقهبندی آموزش داده میشود باید نمونههای ایکس و وای طبقه به عنوان خوراک دادهای در اختیار شبکه قرار گیرد تا یکی از سلولهای وای فعال شوند. در اصطلاح رایج به این نمونه معماری، یادگیری تحت نظارت میگویند. با توجه به ساختار و معماری این شبکهها، در آنها تعداد لایههای پنهان کمتر از تعداد سلولهای ورودی هستند و تعداد سلولهای خروجی برابر با سلولهای ورودی هستند. در نتیجه این امکان فراهم است تا شبکههای عصبی خود رمزگذار را به گونهای آموزش داد تا خروجی را تا حد امکان به ورودی نزدیکتر کنند و با تعمیم دادهها به دنبال الگوهای رایج بگردند. بنابراین این امکان فراهم است تا شبکه عصبی خودرمزگذار را بر مبنای رویکرد یادگیری بدون نظارت نیز استفاده کرد.
شکل 9
شبکه خودرمزگذار متغیر
شبکه عصبی خود رمزگذار متغیر (Variational Auto Encoder) در مقایسه با شبکه عصبی خود رمزگذار، احتمالات را به جای ویژگیها فشرده میکند (شکل 10). در شرایطی که تفاوت جزیی میان این دو شبکه عصبی وجود دارد، اما هر یک از آنها برای کاربرد خاصی در نظر گرفته شدهاند. شبکه عصبی خودرمزگذار به دنبال پاسخ برای این پرسش است که چگونه میتوان دادهها را تعمیم داد؟ در حالی که شبکه خود رمزگذار متغیر به دنبال پاسخی برای این پرسش است که ارتباط میان دو رویداد چقدر زیاد است (بهطور مثال، ارتباط میان ابر و باران) و باید خطا را میان دو رویداد توزیع کرد یا آنها بهطور کامل مستقل از یکدیگر هستند.
شکل 10
شبکه خود رمزگذار دینوزینگ
در شرایطی که شبکههای خودرمزگذار قادر به حل بسیاری از مشکلات هستند، گاهی اوقات این شبکهها به جای شناسایی بهترین ویژگی، تنها روی دادههای ورودی سازگار با یکدیگر متمرکز میشوند (شکل 11). شبکه عصبی خود رمزگذاری دینوزینگ (Deniising AutoEncoder) برای حل این مشکل مقداری نویز (اغتشاش) به سلول ورودی اضافه میکند. در این حالت شبکه باید برای ارائه خروجی، کار بیشتری انجام دهد تا بتواند ویژگیهای متداولتر بیشتری را پیدا کند که در نهایت خروجی دقیقتری آماده شود.
شکل 11
شبکه عصبی خود رمزگذار اسپارس
شبکه عصبی خود رمزگذار اسپارس (Sparse AutoEncoder) گونه پیشرفتهتری از شبکههای عصبی مصنوعی خود رمزگذار است که میتواند برخی از الگوهای گروهی مستتر در دادهها را آشکار کند (شکل 12). ساختار شبکه عصبی خود رمزگذار اسپارس شباهت زیادی به شبکه عصبی خود رمزگذار دینوزینگ دارد. در شبکههای خودرمزگذار اسپارس تعداد لایههای پنهان بیشتر از تعداد سلولهای لایه ورودی و خروجی است.
شکل 12
زنجیره مارکو
زنجیرههای مارکو یکی از قدیمیترین مباحث دنیای گرافها هستند که در آنها هر یال دربرگیرنده احتمالی است (شکل 13). در گذشته از زنجیرههای مارکو برای ساخت متن استفاده میشد، بهطور مثال بعد از واژه Hello، با احتمال 0.0053 درصد کلمه Dear و با احتمال 0.03551 درصد کلمه You ظاهر میشد. امروزه از تکنیک مارکو در موبایلها و با هدف پیشبینی متن استفاده میشود. زنجیرههای مارکو، شبکههای عصبی کلاسیک نیستند و میتوانند برای طبقهبندی بر پایه احتمالات (فیلترهای بیزی)، خوشهبندی (برخی از انواع) و ماشین حالت متناهی استفاده شوند.

شکل 13
شبکه عصبی هاپفیلد
شبکههای هاپفیلد (Hopfield Networks) روی مجموعه محدودی از نمونهها آموزش میبینند و بنابراین به یک نمونه شناخته شده با نمونه مشابهی پاسخ میدهند (شکل 14). قبل از آموزش، هر سلول به عنوان یک سلول ورودی در طول آموزش به عنوان یک سلول پنهان و در هنگام استفاده به عنوان یک سلول خروجی در نظر گرفته میشود. یک شبکه هاپفیلد سعی میکند نمونههای آموزش دیده بسازد. شبکههای عصبی هاپفیلد در تعامل با دینوزینگ و بازگردانی ورودیها استفاده میشوند. اگر به این شبکهها نیمی از یک تصویر یا توالی ارائه شود قادر است نمونه کامل را باز میگرداند.
شکل 14
ماشین بولتزمن
ماشین بولتزمن (Boltzmann Machines) به دلیل اینکه برخی از سلولها به عنوان ورودی علامتگذاری شده و پنهان میمانند، شباهت زیادی به شبکههای هاپفیلد دارند (شکل 15). سلولهای ورودی زمانیکه سلولهای پنهان حالت خود را بهروزرسانی میکنند تبدیل به سلولهای خروجی میشوند.
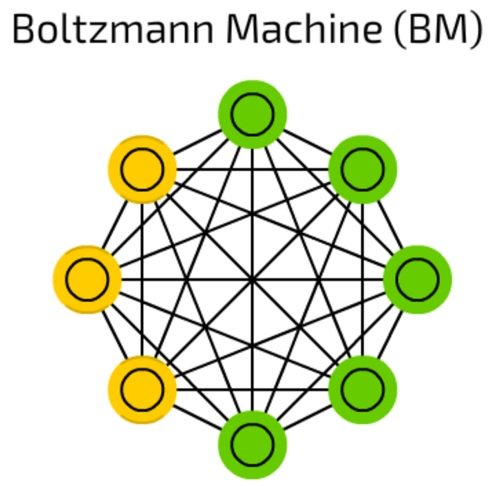
شکل 15
ماشین بولتزمن محدود
ماشین بولتزمن محدود (Restricted Boltzmann Machine) به لحاظ معماری شباهت زیادی به ماشین بولتزمن دارد، اما به دلیل محدود بودن تنها امکان آموزش آن با استفاده از رویکرد پسانتشار تنها به عنوان پیشخور فراهم است، زیرا دادههای ارسال شده پسانتشار یکبار به لایه ورودی برگشت داده میشوند (شکل 16).
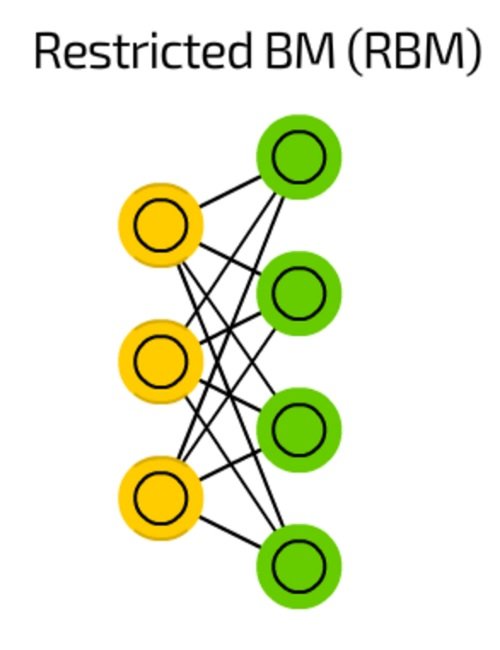
شکل 16
شبکه باور عمیق
شبکه باور عمیق (Deep Belief Network) نشان داده شده در شکل هفده، پشتهای از ماشینهای بولتزمن است که توسط متغیر خودرمزگذار احاطه شدهاند (شکل 17). آنها را میتوان به شکل زنجیره به یکدیگر متصل کرد و برای تولید دادهها بر مبنای یک الگوی یاد گرفته شده از آنها استفاده کرد.
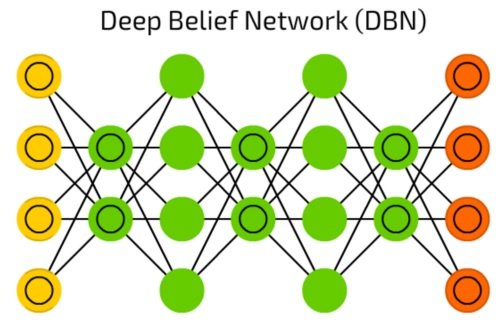
شکل 17
شبکه پیچشی عمیق
شبکه پیچشی عمیق (Deep Convolutional Network) دارای سلولهای پیچشی و هستههایی هستند که هر یک برای کاربرد خاصی در نظر گرفته میشوند (شکل 18). هستههای پیچشی دادههای ورودی را پردازش میکنند و سلولهای پیچشی با استفاده از توابع غیرخطی نظیر Max و کاهش ویژگیهای غیر ضروری فرآیند فوق را سادهتر میکنند. بهطور معمول، شبکههای عصبی پیچشی برای بازشناسی تصاویر استفاده میشوند. بهطوری که روی یک زیرمجموعه از تصاویر در ابعاد 20 در 20 عمل میکنند.
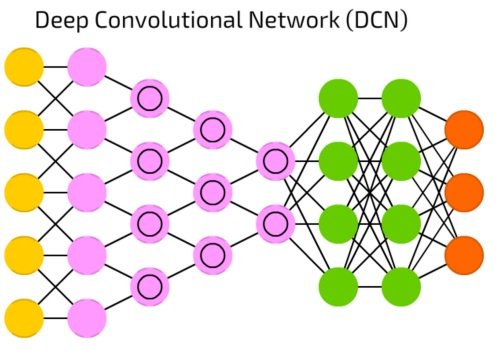
شکل 18
این پنجره ورودی، روی کل تصویر به شکل کرهکرهای و پیکسل به پیکسل حرکت میکند. در این حالت دادهها بر مبنای فشردهسازی ویژگیهای ورودی به گونهای به لایههای پیچشی هدایت میشوند که در نهایت حالتی شبیه به یک قیف را پدید میآورند. در این حالت اولین لایه گرادیان، دومین لایه خطوط و سومین لایه شکل را شناسایی میکنند. این فرآیند تا زمانی ادامه پیدا میکند که یک شی مشخص تشخیص داده شود.
شبکه دکانولوشن
شبکه دکانولوشن (Deconvolution Network) عملکردی برعکس شبکه پیچشی عمیق دارد (شکل 19). شبکه دکانولوشن برای تشخیص تصویری شبیه به گربه، اطلاعات را دریافت و برداری نظیر {dog: 0, lizard: 0, horse: 0, cat: 1} ایجاد میکند و در ادامه بر مبنای اطلاعات به دست آمده تصویر گربه را ترسیم میکند.
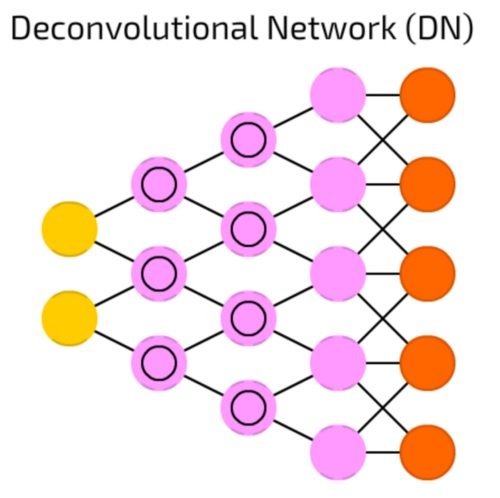
شکل 19
شبکه گرافیکی معکوس پیچشی عمیق
شبکه گرافیکی معکوس پیچشی عمیق (Deep Convolutional Inverse Graphics Network) نشان داده شده در شکل بیست، یک شبکه خودرمزگذار است که در آن شبکه پیچشی عمیق و شبکه دکانولوشن به جای آنکه به عنوان شبکههای مجزا کار کنند با هدف فاصلهگذاریهایی برای ورودی و خروجی شبکه استفاده میشوند (شکل 20). این مدل شبکه بیشتر برای پردازش تصویری که قبلا آموزشی در مورد آنها ندیدهاند استفاده میشوند. این شبکهها به دلیل سطوح انتزاعی که دارند قادر به حذف اشیا خاصی از تصاویر یا ترسیم دوباره تصاویر هستند و علاوه بر این توانایی جایگزینی اشیا درون تصویر را دارند. بهطور مثال به جای اسب یک گورخر را در تصویر جایگزین کنند. این مدل شبکهها در ارتباط با دیپفیک استفاده میشوند.

شکل 20
شبکه مولد تخاصمی
شبکههای مولد تخاصمی (Generative Adversarial Networks) یک شبکه دوگانه متشکل از مولد و (Generator) و متمایزکننده (Discriminator) هستند (شکل 21). این مدل شبکههای عصبی به شکل مستمر بهروزرسانی میشوند تا دو شبکه بتوانند تصویر واقعی تولید کنند.
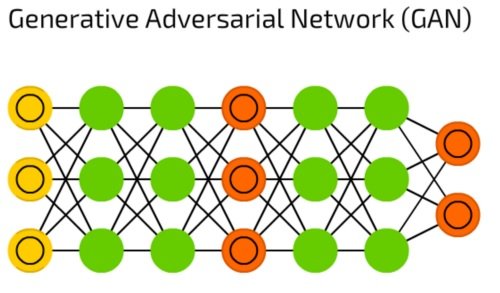
شکل 21
ماشین حالت سیال
ماشین حالت سیال (Liquid State Machine) یک شبکه عصبی اسپارس نیمهمتصل است که در آن توابع فعالساز با سطح آستانه مشخصی جایگزین شدهاند (شکل 22). در این شبکهها سلول، مقادیر را از نمونههای ترتیبی تجمیع میکند و خروجی را تنها زمانی ارائه میکند که مطابق با سطح آستانه تعیین شده باشد. در ادامه شمارنده خارجی را روی صفر قرار میدهد. ماشین حالت سیال با الهام از مغز انسان ساخته شدهاند و بهطور گسترده در بینایی ماشین و سامانههای بازشناسی گفتار استفاده میشوند، هرچند این شبکهها به کندی پیشرفت میکنند.
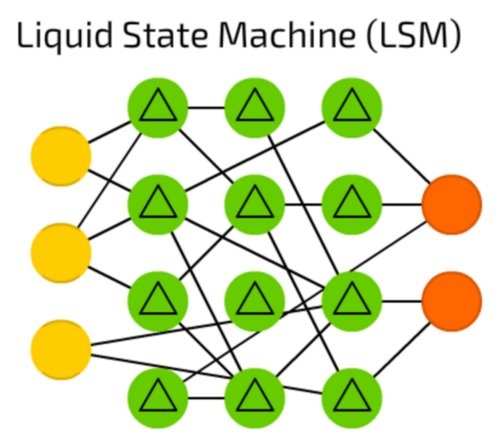
شکل 22
ماشین تورینگ عصبی
شبکههای عصبی شبیه به جعبه سیاه هستند. این شبکهها را میتوان آموزش داد، نتایج آنها را دریافت کرد و عملکرد آنها را بهبود بخشید، با اینحال به درستی مشخص نیست که آنها بر مبنای چه راهکاری تصمیمات خود را اتخاذ میکنند. ماشین تورینگ عصبی (Neural Turing Machine)
برای حل این مشکل طراحی شده است (شکل 23). ماشین تورینگ عصبی یک شبکه عصبی پیشخور با سلولهای حافظه استخراج شده است. برخی دانشمندان معتقد هستند که ماشین عصبی تورینگ نوعی انتزاع روی LSTM است. در این نوع از شبکههای عصبی، حافظه به وسیله محتوای آن ارجاع داده میشود و شبکه میتواند بسته به حالت فعلی از حافظه بخواند یا روی آن بنویسید.

شکل 23
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.























نظر شما چیست؟