





برای دستیابی به راهکار Failover و دستیابی به افزونگی در صورت خرابی یا توقف عملکرد غیرعادی یک سیستم که از قبل در حال خدمترسانی بوده، مهندسان شبکه باید از قبل تمهیدات لازم را اتخاذ کرده باشند. بهطور معمول، Failover در قالب یک پایگاه داده آماده به کار، سیستمهای ذخیرهسازی، سرور، تجهیزات زیربنایی شبکه، لینکهای ارتباطی یا مولفههای سختافزاری تعریف میشود تا هر زمان که قطعه یا نرمافزاری از حرکت باز ایستاد، بهطور خودکار به مدار وارد شوند. نکته ظریفی که باید در این باره به آن دقت کنید این است که تمام تکنیکهای پشتیبانگیری، استوریجها یا سرورهایی که نقش کلیدی در یک سازمان دارند باید در برابر خرابی مصون باشند، زیرا Failover یکی از ارکان مهم در یک برنامه بازیابی پس از فاجعه است.
غلبه بر خرابی (Failover) چیست؟
اگر بخواهیم قیاس سادهای داشته باشیم، باید بگوییم که سیستم خودکار Failover در سرورها عملکردی مشابه سامانههای پایش ضربان قلب دارد. بهطوری که ابزارهای سختافزاری و نرمافزاری به سرورها متصل میشوند تا وضعیت آن را بهشکل دائمی زیر نظر بگیرند. در این حالت، مادامی که عملکرد سرور در شرایط پایدار قرار داشته باشد، سرور ثانویه در حالت آماده بهکار قرار میگیرد. با این حال، اگر سرور ثانویه تغییری در وضعیت سرور اصلی بهدلیل خرابی شناسایی کند، به مدار وارد شده و عملیات سرور اولیه را بر عهده میگیرد. در ادامه، به مدیر شبکه یا مرکز داده هشدار میدهد که سرور اصلی مشکلی دارد یا باید دومرتبه آنرا برخط (آنلاین) کنند. برخی سیستمها مبتنی بر پیکربندی دستی هستند، به این صورت که تنها هنگام شناسایی مشکل، هشداری برای مدیر مرکز داده ارسال میکنند و در ادامه از او درخواست میکنند تا تغییر وضعیت سرور را بهشکل دستی انجام دهد.
در معماری فوق، اگر از فناوریهای مجازیساز سرور یا شبکه بهجای سرورهای فیزیکی استفاده کنید، شرایط متفاوت خواهد بود. در فرآیند مجازیسازی سرور یا شبکه، یک نرمافزار مبتنی بر میزبان روی سرور فیزیکی نصب و اجرا میشود و سرورهای مجازی را در قالب ماشینهای مجازی در اختیار کلاینتها قرار میدهد. در معماری فوق، فرآیند Failover میتواند مستقل از مولفههای سختافزار فیزیکی مثل سرورها انجام شود و الگوریتمهای هوشمند مورد استفاده توسط نرمافزارها توانایی مدیریت و نظارت بر مشکل خرابیها را بر عهده دارند.
Failover به چه صورتی کار میکند؟
مکانیزم غلبه بر خرابی را میتوان بهشکل فعال-فعال (Active-Active)، فعال-غیرفعال (Active-Passive) یا فعال-آماده (Active-Standby) پیادهسازی کرد تا به بالاترین سطح از دسترسپذیری رسید. هر یک از تکنیکهای فوق به روش مختلفی مکانیزم غلبه بر خرابی را پیادهسازی میکنند، در حالت فعال-فعال، حداقل دو گره که بهطور فعال و همزمان یک نوع سرویس را اجرا میکنند، یک خوشه فعال-فعال با دسترسپذیری بالا را تعریف میکنند. معماری خوشه فعال-فعال به این صورت کار میکند که بارهای کاری را در تمام گرهها بهشکل یکنواخت توزیع میکند و اجازه نمیدهد یک گره بیش از ظرفیت مجاز بار کاری دریافت کند. این تقسیم مساوی ضمن آنکه عملکرد را بهبود میبخشد، مانع از آن میشود تا گرهای بیشازاندازه مشغول شود یا گره دیگری در برخی از زمانها بیکار باشد. در این حالت، بهدلیل اینکه گرههای بیشتری در دسترس قرار میگیرند، توان عملیاتی و زمان پاسخدهی بهبود پیدا میکند. برای اطمینان از عملکرد یکپارچه خوشه دسترسپذیری بالا (High Availability) و دستیابی به افزونگی، پیکربندی و تنظیمات گرهها باید یکسان باشد.
در معماری خوشه فعال- غیرفعال، حداقل دو گره نیاز داریم، اما همه آنها در وضعیت فعال قرار ندارند. در یک سیستم با دو گره هنگامی که اولین گره فعال میشود، گره دوم در وضعیت غیرفعال یا در حالت آمادهبهکار بهعنوان سرور Failover قرار میگیرد. در این حالت در صورتی که فعالیت سرور اصلی متوقف شود، سرور دوم که در حالت غیرفعال یا آمادهبهکار قرار دارد، وارد عمل میشود. با این حال، اگر سرور اصلی با مشکلی روبهرو نشود، کلاینتها منابع مورد نیاز خود را از سرور فعال دریافت خواهند کرد.
شبیه به حالت خوشه فعال-فعال، در معماری خوشه فعال-آمادهبهکار، هر دو سرور باید تنظیمات یکسان داشته باشند تا اگر سرور یا مولفههای دیگری مثل روتر وارد حالت غلبه بر خرابی شدند، کاربران متوجه این تغییر نشوند. در یک خوشه فعال-آمادهبهکار درست است که گره آمادهبهکار همیشه روشن است، اما میزان استفاده واقعی از آن نزدیک به صفر است، زیرا تنها در صورتی مورد استفاده قرار میگیرد که سرور اصلی با مشکل جدی روبهرو شود.
در یک خوشه فعال-فعال، میزان استفاده از هر دو گره 50-50 است. همانگونه که اشاره شد، در معماری فوق هر گره بهتنهایی میتواند کل بار را دریافت کرده و به مدیریت آن بپردازد. نقطه ضعف معماری فوق این است که اگر یک گره در معماری فعال-فعال بیش از نیمی از بارکاری را بر عهده بگیرد، در صورت خرابی، عملکرد به میزان قابل توجهی کاهش پیدا میکند، زیرا گره دیگر ضمن انجام کارهای خود مجبور است وظایف گره دیگر را نیز انجام دهد.
تاخیر در ارائه خدمات در هنگام خرابی با پیکربندی فعال-فعال مبتنی بر دسترسپذیری بالا تقریبا صفر است، زیرا هر دو مسیر فعال هستند و سرورها دائما در حال خدمترسانی هستند. با یک پیکربندی فعال-غیرفعال، زمان وقفه بالقوه ممکن است طولانی شود، زیرا سیستم باید از یک گره به گره دیگر سوئیچ کند که نیازمند صرف زمان است. حال اگر عملیات فوق بهشیوه دستی انجام شود، این تاخیر بیشتر هم میشود.
خوشه Failover چیست؟
یکی از مباحث مهمی که هنگام پیادهسازی مکانیزمهای غلبه بر خرابی باید به آن دقت کنید، «خوشه Failover» است. خوشه فوق، مجموعهای از سرورها است که سه معیار «آستانه تحمل خطا» (Fault Tolerance)، «دسترسپذیری پیوسته» (Continuous Availability) یا «دسترسی بالا» (High Availability) را ارائه میدهند. یک شبکه مبتنی بر خوشه Failover ممکن است از ماشینهای مجازی، سختافزار فیزیکی یا ترکیب هر دو حالت، برای غلبه بر خرابیها استفاده کند. در چنین شرایطی، اگر یکی از سرورهای خوشه Failover از کار افتد، شبکه بهطور خودکار فرآیند Failover را آغاز میکند. مزیتی که روش فوق دارد این است که فرآیند هدایت بارهای کاری گره ازکارافتاده به گره دیگری در خوشه در کمترین زمان ممکن انجام میشود تا تاخیر قابل توجهی در ارائه خدمات بهوجود نیاید.
بهطور معمول، خوشههای Failover با هدف دسترسپذیری بالا یا دسترسپذیری مستمر مورد استفاده قرار میگیرند، هرچند بیشتر مهندسان شبکه از خوشههای Failover با هدف دستیابی به آستانه تحمل خطا استفاده میکنند. خوشههای دسترسپذیری مستمر هنگامی که سرورهای اصلی یا اولیه از کار میافتند، وقفه را از بین میبرند و به کاربران نهایی اجازه میدهند بدون مشکل از برنامهها و سرویسها استفاده کنند. درست است که خوشههای دسترسپذیری بالا، وقفه کوتاهی در دسترسی به سرویسها بهوجود میآورند، اما در مقابل زمان بازیابی پس از فاجعه را بهلطف بازیابی خودکار کوتاه کرده و مانع از آن میشوند تا دادهها از دست بروند. فرآیند بازیابی در خوشههای با دسترسپذیری بالا را میتوان با استفاده از ابزارهای مدیریت خوشه Failover که بهعنوان بخشی از راهکارهای خوشه Failover در دسترس قرار دارند، خودکارسازی کرد.
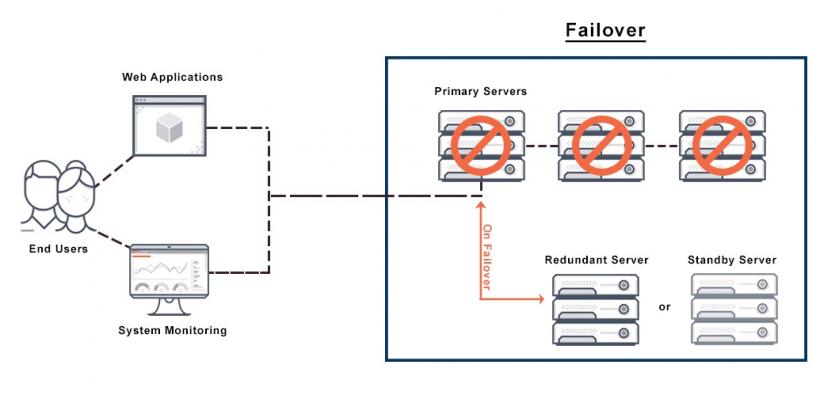
بهطور کلی، یک خوشه متشکل از دو یا چند گره یا سرور است که از طریق کابلهای شبکه و راهحلهای نرمافزاری به یکدیگر متصل هستند. لازم به توضیح است که فناوریهای خوشهبندی اضافی مثل پردازش موازی یا همزمان، متعادلکننده بار و راهحلهای ذخیرهسازی ابرمحور در برخی از پیادهسازیهای Failover مورد استفاده قرار میگیرند. در مجموع باید بگوییم که Failover با هدف پایداری یک ارتباط اینترنتی با تکیه بر اصل افزونگی تجهیزات در شرایطی که ممکن است خرابی مانع دسترسی به تجهیزات و سرویسها شود، مورد استفاده قرار میگیرد.
Application Server Failover چیست؟
سرورهای برنامه، سرورهایی هستند که برنامههای کاربردی را اجرا میکنند. بهبیان دیگر، راهکار سرور برنامه یک استراتژی غلبه بر خرابی برای محافظت از سرورها است. سرورهای برنامه، نامهای دامنه منحصربهفردی دارند و در شرایط ایدهآل باید روی سرورهای مختلف پیادهسازی شوند. بهطور معمول یک خوشه Failover کارآمد مبتنی بر راهحلهای متعادلساز و سرورهای برنامه است.
آزمون Failover چیست؟
آزمون Failover ظرفیت سیستم هنگام خرابی سرور در تخصیص منابع کافی در زمان بازیابی دوباره را بررسی میکند. بهبیان دقیقتر، آزمون غلبه بر خرابی، قابلیت خوشهها در نظارت و رسیدگی به مشکلات سرورها را بررسی میکند. این آزمون مشخص میکند آیا خوشههای Failover در صورت بروز مشکلاتی همچون خرابی سرورها، روترها، استوریجها و غیره، توانایی لازم در مدیریت منابع اضافی و انتقال عملیات به سیستمهای پشتیبان را دارند یا خیر. بهطور مثال، آزمون فوق، توانایی سیستم در زمینه مدیریت و تامین انرژی موردنیاز یک پردازنده مرکزی اضافی یا چند سرور پس از رسیدن به آستانه عملکرد مشخص را ارزیابی میکند. هنگامیکه مولفهای خراب میشود، آستانه تحمل خطا در وضعیت ناپایدار قرار میگیرد که ممکن است مشکلات دیگری مثل از دست رفتن دادهها را بهوجود آورد. بهطور کلی، آزمون Failover با هدف ارزیابی انعطافپذیری و امنیت مورد استفاده قرار میگیرد.
Failover and Failback چیست؟
در دنیای شبکههای کامپیوتری، Failover به فرآیند انتقال عملیات از طریق یک ابزار واسط پشتیبان اشاره دارد. بهطور مثال، در مورد مراکز داده بزرگ، سایت پشتیبان Failover یک مرکز داده کامل متشکل از تجهیزات سختافزاری و شبکه آمادهبهکار است که اغلب در منطقهای دورتر از سایت اصلی قرار دارد و هنگام بروز مشکل و در زمان بازیابی پس از فاجعه مورد استفاده قرار میگیرد. در چنین مراکزی، راهحل Failover شامل مجموعه ابزارها یا سرویسهایی است که بر روند انتقال عملیات به مکان جدید مورد استفاده قرار میگیرد.
عملیات Failback شامل بازگشت شرایط به حالت اولیه پس از دوره تعمیر و نگهداری است. بهطور معمول، طراحان سیستمها قابلیت Failover را در سیستمها، سرورها یا شبکههایی پیادهسازی میکنند که باید قابلیت اطمینان بالایی داشته باشند و اصل دسترسپذیری بالا و دسترسپذیری مستمر را تضمین کنند. بهلطف استفاده از راهحلهای مجازیسازی که وابستگی به سختافزارها را کم میکنند، راهکارهایFailover با اختلال کم یا بدون اختلال در سرویسها، تداوم عملیات تجاری را تضمین میکنند.
کلام آخر
دادهها نیروی محرکه کسبوکارها هستند؛ از اینرو، مهم است که یک استراتژی قدرتمند بازیابی پس از فاجعه داشته باشید. بهویژه در این مقطع زمانی که تهدیدات ناشی از حملههای سایبری و کارکنان دورکار روزبهروز در حال افزایش است. هدف اصلی Failover متوقف کردن یا کاهش شکست شبکهها و سیستمها است. اگر زیرساخت شبکه بهدرستی پیکربندی شده باشد، Failover و Failback یک مکانیزم یکپارچه محافظتی در برابر بیشتر اختلالها ارائه میکند.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.


















نظر شما چیست؟