









سرآغاز شکلگیری شبکه BERT
مدل BERT سرنام Bidirectional Encoder Representations from Transformers، یک مدل زبانی عمیق (Deep Language Model) مبتنی بر معماری ترنسفورمر (Transformers) است که در سال 2018 توسط تیم هوش مصنوعی گوگل توسعه داده شد. برت قادر است برای یک واژه یا جمله، یک بردار ویژگی با اندازه ثابت تولید کند که قابل استفاده در وظایف پردازش زبان طبیعی، مانند تشخیص احساسات، ترجمه ماشینی و پاسخ به سوالات باشد. مهمترین ویژگی مدل برت این است که یک مدل زبانی دوطرفه است، به این معنی که برای پیشبینی هر کلمه در جمله، به تمام کلمات قبل و بعد از آن مراجعه میکند و از اطلاعات موجود در آنها استفاده میکند. این ویژگی باعث میشود که مدل برت برای تمام وظایف پردازش زبان طبیعی، از جمله تشخیص احساسات، ترجمه ماشینی و پاسخ به پرسشها کارآمد باشد.
مدل برت چگونه کار میکند؟
این مدل در واقع ترکیبی از دو رویکرد مختلف بهنامهای مدل زبانی آموزش بدون نظارت (Unsupervised Language Model) و یادگیری چند وظیفگی همزمان (Simultaneous Multi-Task Learning ) است.
در رویکرد مدل زبانی آموزش بدون نظارت، شبکه با استفاده از کلاندادهها و بدون برچسبگذاری دادهها، روند یادگیری زبان طبیعی را آغاز میکند. در این مرحله، شبکه میتواند بدون ناظر یاد بگیرد که هر کلمه در یک جمله چه معنایی دارد و چگونه با کلمات دیگر در جمله ارتباط دارد. در رویکرد یادگیری همزمان، شبکه بهصورت همزمان برای چند وظیفه مختلف آموزش داده میشود که از آن جمله باید به تشخیص ترتیب جملات، پرسش و پاسخ، تشخیص نوع جمله و تشخیص موجودیتها اشاره کرد. با این کار، شبکه میتواند بهترین ویژگیهای مربوط به هر کدام از این وظایف را یاد بگیرد و این ویژگیها را با هم ترکیب کند تا بتواند وظایف دیگری را انجام دهد.
مدل برت با ترکیب این دو رویکرد و در اختیار داشتن حجم گستردهای از دادهها و توانایی انجام چند کار بهطور همزمان قادر است به دقیقترین شکل ممکن وظایف محوله را انجام دهد. همین مسئله باعث شده تا برت به یکی از بهترین و قدرتمندترین مدلهای پردازش زبان طبیعی تبدیل شود.
در حقیقت مدل BERT در دو اندازه متفاوت آموزش داده میشود که برت پایه (BERTBASE ) و برت بزرگ (BERTLARGE) نام دارند (شکل 1).
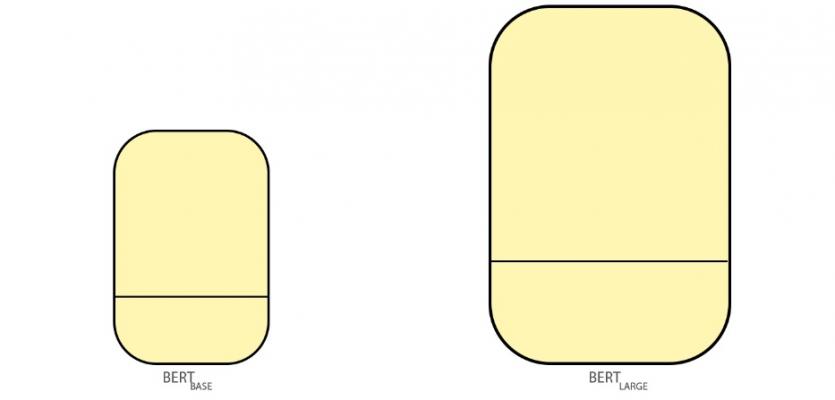
شکل 1
مدل برت در واقع دستهای از انکودرهای مدل ترنسفورمر
(Transformer Model) است که آموزش دیدهاند. هر دو مدل برت شامل لایههای انکودر است. بهطور مثال، مدل برت پایه 12 لایه انکودر و مدل بزرگتر 24 لایه انکودر دارد. مدل پایه در مجموع 110 میلیون پارامتر و مدل بزرگ 345 میلیون پارامتر دارد که آموزش هر یک از آنها به چهار روز زمان نیاز دارد (بهشرطی که تجهیزات سختافزاری قدرتمندی داشته باشید). مدل پایه 768 و مدل بزرگتر 1024 گره پنهان در لایه شبکه پیشخور خود دارند و تعداد لایههای توجه در اولی 12 و در دومی 16 عدد است (شکل 2).
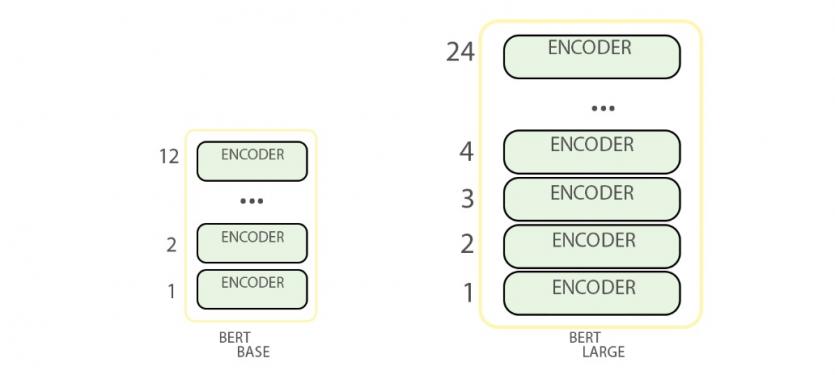
شکل 2
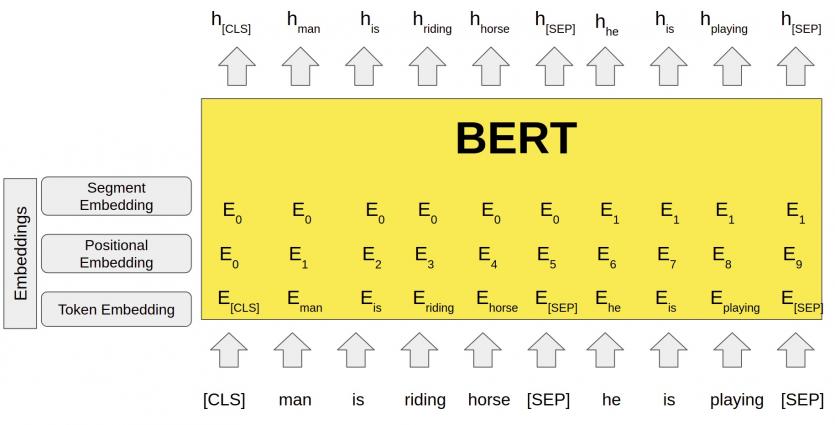
در مدل فوق، اولین توکن ورودی با یک توکن خاص کهCLS نام دارد در اختیار مدل قرار میگیرد که شباهت زیادی به انکودر معماری ترنسفورمر دارد. به بیان دقیقتر، دنبالهای از کلمات بهعنوان ورودی در اختیار مدل قرار میگیرند. اینها در طول لایههای انکودر حرکت میکنند. هر لایه انکودر یک لایه Self-Attention و یک لایه شبکه پیشخور دارد که ورودیها از آنها عبور میکنند و سپس به لایه انکودر بعدی وارد میشوند (شکل 3).
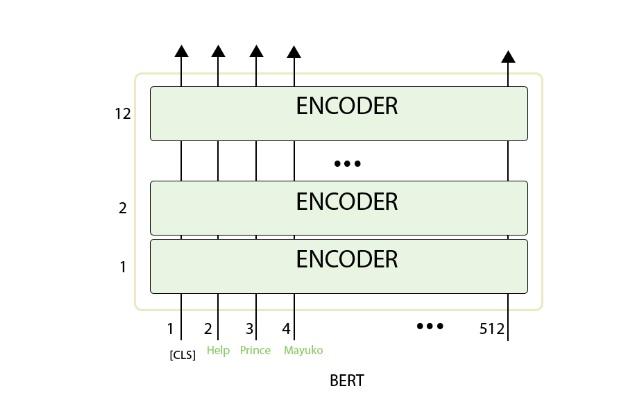
شکل 3
هر بردار موقعیت، گرههای لایه پنهان را در خروجی نشان میدهد. بهطور مثال، در مدل برت پایه اندازه لایه پنهان 768 است، بنابراین در خروجی بردارهایی به اندازه 768 خواهیم داشت. در مسئله طبقهبندی فقط بردار خروجی اول مهم است که ورودی آن همان توکن CLS است (شکل 4). این بردار خروجی در مسئله طبقهبندی بهعنوان ورودی به لایه طبقهبندی وارد میشود تا بتواند در خروجی نتیجه را نشان دهد (شکل 5).
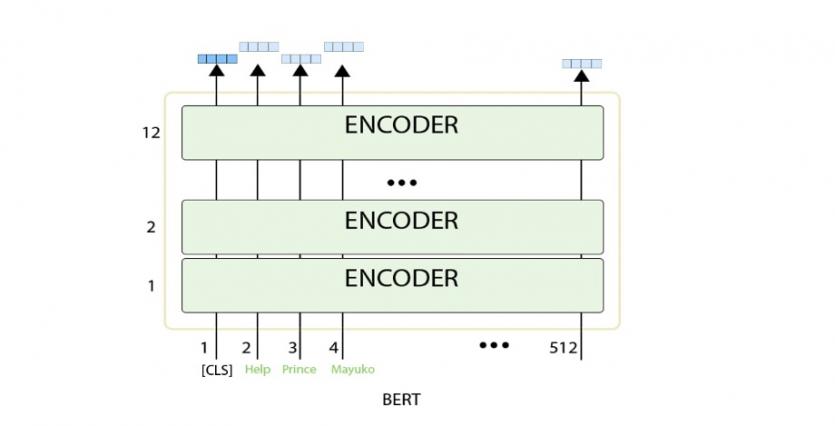
شکل 4
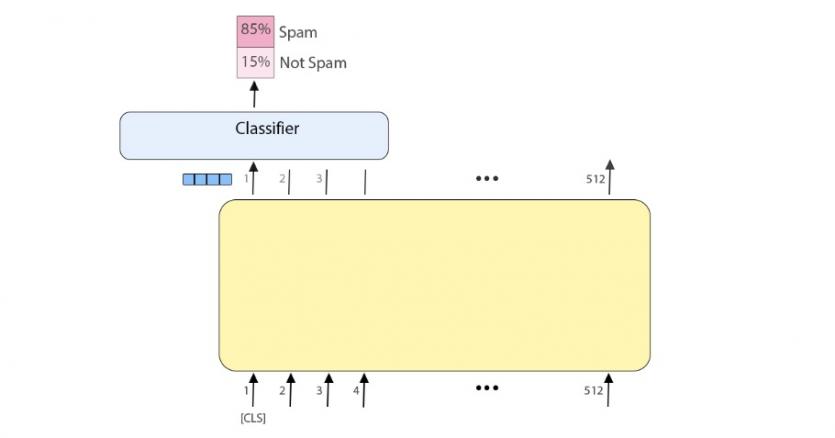
شکل 5
آموزش مدل برت
مدل برت بر مبنای رویکرد بدون ناظر و یادگیری انتقالی آموزش داده میشود. در این رویکرد، مدل با استفاده از مجموعه داده بزرگی که از منابع مختلفی مثل وب جمعآوری شده است، بدون نیاز به برچسبهای دقیق آموزش میبیند. در مرحله اول، برای آموزش مدل، هر جمله به چند قطعه کوچکتر تقسیم میشود. سپس، برای هر قطعه، یک بردار ویژگی ایجاد میشود که شامل تمام کلمات و موقعیت آنها در جمله است. در مرحله بعد، با استفاده از شبکههای ترنسفورمر برای هر ویژگی، بردار جدیدی بهنام مدل زبانی نقابدار (Masked Language Model) ایجاد میشود. در این مرحله، برای برخی از کلمات در هر پاراگراف از مترادفها یا نمادهای ویژه استفاده میشود و سپس مدل سعی میکند که با توجه به کلمات دیگر در همان جمله، کلمات جایگزین را پیشبینی کند. در مرحله آخر، با استفاده از رویکرد مدل زبانی نقابدار، مدل برای تمام جملات و نوشتارهای جدید، بردار ویژگی جدیدی ایجاد میکند. سپس، با استفاده از این بردارهای ویژگی، مدل با محوریت رویکرد یادگیری انتقالی، برای وظایف دیگری مانند تشخیص موجودیتها و پرسش و پاسخ آموزش داده میشود.
روشهای استفاده از مدل برت
مدل برت بهدلیل قابلیتهای بسیار بالایی که در پردازش زبان طبیعی دارد، در انجام انواع مختلفی از وظایف مرتبط با پردازش زبان طبیعی مورد استفاده قرار میگیرد. برخی از روشهای استفاده از مدل برت بهشرح زیر هستند:
- تشخیص موجودیتها: مدل برت قادر است بهخوبی نام اشخاص، محلها و شرکتها را در جملات تشخیص دهد.
- پرسش و پاسخ: میتوان از مدل برت برای پاسخگویی به پرسشهایی استفاده کرد که پاسخ دقیقی برای آنها وجود دارد. در این روش، مدل با دریافت یک پرسش بهصورت خودکار بهترین پاسخ را پیدا میکند. این همان تکنیکی است که چت جیپیتی از آن استفاده میکند.
- تشخیص احساسات: با استفاده از مدل برت میتوان بهخوبی احساسات مثبت و منفی متنها را تشخیص داد.
- خلاصهسازی متن: با استفاده از مدل برت میتوان متنهای طولانی را خلاصهسازی کرد و مهمترین اطلاعات را استخراج کرد.
- ترجمه ماشینی: مدل برت برای ترجمه ماشینی نیز استفاده میشود و با توجه به قابلیتهای بالایی که در فهم زبان و ترجمههای دقیقتر دارد مورد استفاده قرار میگیرد. امروزه، ابزارهایی مثل گوگل ترنسلیت و بینگ مایکروسافت از این ویژگی برای ترجمه متون به زبانهای مختلف استفاده میکنند.
- پردازش زبان طبیعی در بازیابی اطلاعات: با استفاده از مدل برت میتوان بهترین صفحات وب را برای پاسخ به پرسشهای کاربران پیدا کرد.
تنظیم دقیق (Fine-tuning) در مدل برت
تنظیم دقیق در مدل برت، به معنی آموزش مجدد این مدل برای انجام وظیفهای خاص با استفاده از دادههای برچسبدار است. در این روش، ابتدا مدل برت بدون برچسب آموزش داده میشود و در قسمت تنظیم دقیق با استفاده از دادههای برچسبدار، برای انجام وظیفهای خاص دوباره آموزش داده میشود. وظایف خاص میتوانند تشخیص احساسات، تشخیص موجودیتها یا پرسش و پاسخ و تعامل با کاربران باشند. در ادامه، برای آموزش دوباره مدل از الگوریتمهای بهینهسازی مانند Adam استفاده میشود و پارامترهای مدل با استفاده از دادههای برچسبدار بهروزرسانی میشوند. همچنین، برای جلوگیری از برازش بیشازحد (overfitting) از تکنیکهایی مانند Dropout و L2 regularization استفاده میشود.
استخراج ویژگی (Feature Extraction) در مدل BER
استخراج ویژگی در مدل برت، به معنی استفاده از بخشهایی از مدل است که از قبل آموزش دیدهاند، بدون آنکه نیازی به اجرای دوباره تنظیم دقیق (Fine-tuning) برای استخراج ویژگیها از متون ضروری باشد. در این روش، مدل برت با دادههای برچسبدار آموزش داده نمیشود و بهجای آن، از بخشهای ازپیشآموزشدیده برای استخراج ویژگیها از متنها استفاده میشود.
برای استخراج ویژگی، ابتدا متنها به قطعات کوچکتر تقسیم میشوند و سپس با استفاده از بخشهایی از مدل برت که پیشآموزش دیدهاند، برای هر بردار ویژگی جدیدی ایجاد میشود. این بردارهای ویژگی معمولا برای وظایفی مانند تحلیل احساسات، تشخیص موجودیتها و خلاصهسازی متن استفاده میشوند. مزیت اصلی استخراج ویژگی در مدل برت، عدم نیاز به آموزش دوباره مدل برای هر وظیفه خاص است. این روش بهعنوان یک روش سریع و موثر در زمینه پردازش زبان طبیعی در سیستمهایی که نیاز به پردازش بسیار زیادی از اطلاعات دارند، مانند موتورهای جستوجو و سیستمهای پردازش زبان طبیعی، استفاده میشود.
در اینجا از تکنیک نقابزنی/ماسکگذاری (Masking) نیز استفاده میشود که به معنی مخفی کردن بخشی از ورودیها در فرایند پیشآموزش است. در این روش، برای هر جمله ورودی، بخشی از کلمات بهصورت تصادفی مخفی میشوند و مدل سعی میکند کلمات مخفیشده را با توجه به سایر کلمات ورودی پیشبینی کند.
بهطور دقیقتر، در تکنیک ماسکگذاری، برای هر جمله ورودی، 15 درصد از کلمات بهصورت تصادفی مخفی میشوند. سپس، در مرحله پیشآموزش، مدل سعی میکند برای هر کلمه مخفیشده، کلمه متناظر را پیشبینی کند. بهعنوان مثال، در جمله «من به دانشگاه رفتم و کتابهایم را با خودم بردم»، کلمه «رفتم» در این تکنیک بهصورت تصادفی مخفی میشود و مدل سعی میکند کلمه متناظر با آن یعنی «به» را پیشبینی کند. تکنیک ماسکگذاری در مدل بهدلیل اینکه مدل در پیشآموزش با کلماتی که مخفی شدهاند برخورد داشته است، به بهبود عملکرد مدل در وظایف پردازش زبان طبیعی کمک میکند. همچنین، این تکنیک باعث میشود مدل برای فهم بهتر جملات، به ترتیب کلمات و ارتباط بین آنها دقت کند.
ویژگیهای کلیدی مدل برت
مدل برت بهدلیل ویژگیهای کلیدی که دارد مورد توجه مهندسان یادگیری ماشین و پردازش زبان طبیعی قرار دارد. از جمله این ویژگیها به موارد زیر باید اشاره کرد:
- مبتنی بر معماری ترنسفورمر است: مدل برت بر مبنای معماری ترنسفورمر طراحی شده است که یک شبکه عصبی پیشرفته برای پردازش زبان طبیعی است و امکان پردازش همزمان دو جهت دنباله کلمات را دارد.
- پیشآموزش با مجموعه داده بزرگ: مدل برت با استفاده از مجموعه داده بزرگی که شامل متون مختلف و فاقد برچسبگذاری است، پیشآموزش داده شده است. این پیشآموزش به مدل برت امکان فهم بهتر مفهوم کلمات و جملات را میدهد.
- قابلیت تشخیص موجودیتها: مدل برت در وظایف تشخیص موجودیتها مانند شخص، سازمان، محصول، مکان و غیره بسیار قوی عمل میکند.
- قابلیت تحلیل احساسات: مدل برت راهکاری بسیار قدرتمند برای تحلیل احساسات متون دارد و حتا قادر است احساسات مثبت، منفی و خنثا را در یک جمله تشخیص دهد.
- محاسبه جملات مشابه: مدل برت با استفاده از تکنیکهایی مانند توجه چندسر (Multi-Head Attention)، امکان محاسبه شباهت بین دو جمله یا پاسخ به پرسشهای متنی را دارد.
- قابلیت تفسیر: مدل برت امکان تفسیر نتایجی را که خود تولید میکند دارد و میتواند بهدلیل وزندهی به کلمات، نزدیکترین مکالمه به زبان طبیعی را با انسانها برقرار کند.
- از دیگر ویژگیهای مدل برت میتوان به آموزش با استفاده از روش مدل زبانی ماسکزدهشده (Masked Language Model) اشاره کرد. در این روش، برای آموزش مدل، برخی از کلمات در جملات با کلمات دیگر جایگزین میشوند و مدل باید بتواند کلمات جایگزین را شناسایی کند. این روش آموزش، باعث میشود که مدل برت بتواند بهتر درک کند که کلمات در چه زمینههایی با هم مرتبط هستند که نقش موثری در پاسخدهی دقیقتر به پرسشها و ترجمه ماشینی دارد. در حال حاضر، مدل برت یکی از محبوبترین و کارآمدترین مدلهای زبانی در حوزه پردازش زبان طبیعی است و توسط بسیاری از شرکتها و سازمانها برای حل مسائل پردازش زبان طبیعی استفاده میشود. با توجه به این ویژگیها، مدل برت بهعنوان یکی از بهترین مدلهای پردازش زبان طبیعی محسوب میشود که در بسیاری از وظایف مانند تحلیل احساسات، تشخیص موجودیتها، پرسش و پاسخ و خلاصهسازی متن، عملکرد بسیار خوبی دارد.
کاربرد اصلی مدل BERT چیست
کاربرد اصلی مدل برت در زمینه پردازش زبان طبیعی است، زیرا بهترین نتیجه را ارائه میدهد. بهطور مثال، در بحث تشخیص موجودیتها، مدل برت میتواند موجودیتهایی مانند نام افراد، شرکتها، مکانها، ساختمانها و غیره را به بهترین شکل تشخیص دهد. همچنین، در پرسش و پاسخ متنی، مدل برت میتواند به پرسشهای مختلف پاسخ دهد و بر مبنای اصل استنتاج پرسشهای مرتبط با پرسش اصلی کاربر را به او پیشنهاد دهد. در خلاصهسازی متن، این مدل میتواند یک متن طولانی را به یک خلاصه کوتاه تبدیل کند. همچنین، در ترجمه ماشینی نیز بسیار قوی عمل میکند و میتواند متون را به روشی دقیق و خوانا به زبان دیگری ترجمه کند.
مدل برت با چه مدلهای دیگری در پردازش زبان طبیعی قابل مقایسه است؟
امروزه، بحث داغی در محافل علمی پیرامون مقایسه مدل برت با دیگر مدلهای پردازش زبان طبیعی در جریان است و برخی بر این باور هستند که این مدل عملکرد بهتری نسبت به رقبا دارد. برخی از مدلهایی که با مدل برت قابل مقایسه هستند بهشرح زیر هستند:
- ELMo: مدل ELMo یکی از مدلهای کارآمد در حوزه پردازش زبان طبیعی است که در سال 2018 میلادی معرفی شد. بررسیهای انجامشده نشان میدهد که مدل برت در بسیاری از وظایف پردازش زبان طبیعی از ELMo بهتر عمل میکند.
- GPT-2: مدل GPT-2 یکی دیگر از مدلهای حوزه پردازش زبان طبیعی است که در سال 2019 میلادی معرفی شد. در مقام مقایسه با مدل برت، GPT-2 در مورد وظایفی مثل تولید متن و ترجمه ماشینی، بهتر عمل میکند، اما در وظایفی مانند تحلیل احساسات و تشخیص موجودیتها، برت بهتر عمل میکند.
- Transformer-XL: مدل Transformer-XL نیز یکی دیگر از مدلهای شاخص در حوزه پردازش زبان طبیعی است که در سال 2019 میلادی معرفی شد. در مقایسه با مدل برت، Transformer-XL در مورد وظایفی مثل پرسش و پاسخ متنی، بهتر عمل میکند، اما در انجام وظایفی مانند تحلیل احساسات و تشخیص موجودیتها، باز هم عملکرد برت بهتر است.
کلام آخر
مدل برت در بسیاری از وظایف پردازش زبان طبیعی، از جمله تشخیص موجودیتها، تحلیل احساسات، پرسش و پاسخ متنی، خلاصهسازی متن و ترجمه ماشینی، عملکرد بسیار خوبی دارد و بهعنوان یکی از محبوبترین و پرکاربردترین مدلهای پردازش زبان طبیعی محسوب میشود. به اعتقاد بسیاری از کارشناسان، برت یک مدل زبانی قدرتمند است که نقطه عطفی در حوزه پردازش زبانهای طبیعی بهشمار میشود. مدل برت امکان استفاده از تکنیک یادگیری انتقالی (Transfer Learning) را در حوزه پردازش زبانهای طبیعی بهوجود آورده و در بسیاری از وظایف این حوزه عملکرد خوبی ارائه کرده است. بدون تردید برت در آینده نزدیک در انجام طیف گستردهای از کارها به ما کمک خوهد کرد.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.




















نظر شما چیست؟