









بیشبرازش در زمان اجرای مدل، میتواند باعث عملکرد نامناسب مدل در پیشبینی دادههای جدید شود. برای جلوگیری از بیش برازش، میتوان از روشهایی مانند استفاده از دادههای ارزیابی (validation data)، استفاده از روشهای کاهش اندازه مدل، محدود کردن پارامترهای مدل، استفاده از روشهای مناسب برای انتخاب فراپارامترها و یا استفاده از روشهایی مانند Dropout در شبکههای عصبی استفاده کرد.
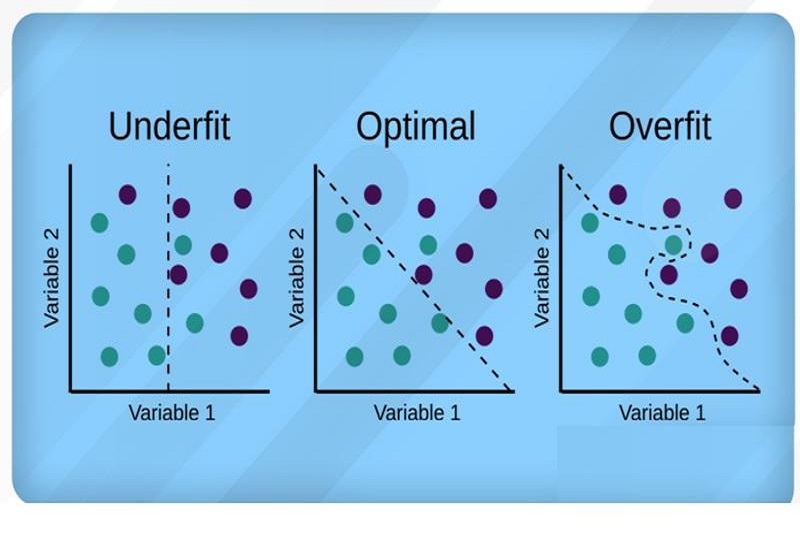
دلایل ایجاد بیشبرازش (Overfitting)
از مهمترین و اصلیترین عواملی که باعث بروز مشکل بیشبرازش (Overfitting) میشوند به موارد زیر باید اشاره کرد:
- تعداد پارامترهای بیش از حد: اگر تعداد پارامترهای مدل بیشتر از تعداد دادههای آموزشی باشد، مدل به ساختار دادههای آموزش به شدت عادت میکند و عملکرد ضعیفی در پیشبینی دادههای جدید دارد.
- انتخاب نادرست فراپارامترها: فراپارامترها مانند نرخ یادگیری، تعداد لایهها و تعداد سلولهای عصبی میتوانند در کنترل بیشبرازش و عدم/کم برازش (Underfitting) مدل موثر باشند. انتخاب نادرست فراپارامترها باعث میشوند مدل به دادههای آموزشی بسیار عادت کند و برای دادههای جدید نتواند به خوبی پاسخ دهد.
- کمبود دادههای آموزش: اگر تعداد دادههای آموزش کم باشد، مدل به دادههای آموزشی عادت کرده و قادر نیست به خوبی به دادههای جدید پاسخ دهد.
- دادههای دارای نویز: اگر دادههای آموزشی شامل دادههای بی کیفیت (پالایش نشده) باشند، مدل به این اغتشاش در دادهها عادت میکند، ارتباطات اشتباه را یاد میگیرد و برای دادههای جدید قابلیت تعمیم ندارد.
- عدم عمومیت مدل: اگر مدل برای مسئله خاصی طراحی شده و برای دادههای جدید عملکرد بسیار بدی داشته باشد، میتوان گفت که مدل دارای عدم عمومیت است و برای مسئله یادگیری مورد نظر قابل استفاده نیست.
راهحلهای مقابله با بیشبرازش
راهکارهای مختلفی برای غلبه بر مشکل بیشبرازش وجود دارند که از مهمترین آنها به موارد زیر باید اشاره کرد:
1. استفاده از دادههای ارزیابی (validation data)
دادههای ارزیابی به عنوان یک مجموعه جداگانه از دادههای آموزشی و تست استفاده میشوند. مدل با استفاده از دادههای آموزشی، آموزش داده میشود، اما با استفاده از دادههای ارزیابی، عملکرد مدل روی دادههای جدید بررسی میشود. اگر عملکرد مدل بر روی دادههای ارزیابی بهتر از دادههای آموزشی باشد، بیشبرازش روی دادههای آموزش وجود دارد.
در روش استفاده از دادههای ارزیابی (validation data)، مجموعهای از دادهها به صورت جداگانه از دادههای آموزش و تست، مشخص میشوند. مدل با استفاده از دادههای آموزشی، آموزش داده میشود و در هر دوره (batch)، عملکرد مدل بر روی دادههای ارزیابی نیز محاسبه میشود. با این کار، مدل دارای دانشی در مورد دادههای جدید خواهد شد و اگر بیشبرازش روی دادههای آموزشی وجود داشته باشد، این موضوع در عملکرد مدل بر روی دادههای ارزیابی قابل تشخیص خواهد بود.
با استفاده از دادههای ارزیابی، میتوان به راحتی از بیشبرازش جلوگیری کرد. در صورتی که عملکرد مدل بر روی دادههای آموزش به خوبی است، اما عملکرد مدل بر روی دادههای ارزیابی خوب نباشد، میتوان برای پیشگیری از بیشبرازش از روشهای متنوعی مانند استفاده از Dropout، کاهش تعداد لایهها و سلولهای عصبی یا انتخاب فراپارامترهای مناسب استفاده کرد.
استفاده از دادههای ارزیابی، به عنوان یکی از مهمترین راههای مقابله با بیشبرازش شناخته شده است و در بسیاری از مدلهای یادگیری عمیق در حوزه هوش مصنوعی و یادگیری ماشین استفاده میشود.
2. استفاده از روشهای کاهش اندازه مدل
برای کاهش تعداد پارامترهای مدل، میتوان از روشهایی مانند کوچک کردن تعداد لایهها، کاهش تعداد سلولهای عصبی یا استفاده از روشهای خاصی مانند هرس کردن (pruning) استفاده کرد.
3. محدود کردن پارامترهای مدل
محدود کردن پارامترهای مدل به مقادیر خاصی مانند محدود کردن وزنها به بازههای خاص میتواند به کاهش بیشبرازش کمک کند. یکی از روشهای مقابله با بیشبرازش، محدود کردن پارامترهای مدل به مقادیر خاصی است. محدود کردن پارامترهای مدل به مقادیر خاص میتواند به کاهش بیشبرازش کمک کند.
یکی از روشهای محدود کردن پارامترهای مدل، محدود کردن وزنهای مدل به بازههای خاص است. به عنوان مثال، به جای استفاده از وزنهایی با اعداد بزرگ، میتوان از وزنهایی با مقادیر کوچکتر استفاده کرد. این روش محدودیت به وزنهایی که متعلق به همان بازه مشخص شده هستند اختصاص پیدا میکند و به این ترتیب، تعداد پارامترهای مدل را کاهش میدهد.
روش دیگری برای محدود کردن پارامترهای مدل، استفاده از روشهایی مانند weight decay است. در این روش، یک جریمه به پارامترهای مدل اعمال میشود که باعث کاهش اندازه پارامترها و کاهش بیشبرازش میشود.
همچنین، میتوان از روشهای هرس کردن استفاده کرد. در این روش، پارامترهای مدلی که بیشترین تأثیر را در عملکرد مدل ندارند، حذف میشوند. این روش به کاهش تعداد پارامترهای مدل و بهبود کیفیت مدل در حین آموزش کمک میکند. در کل، محدود کردن پارامترهای مدل یک روش مهم در مقابله با بیشبرازش است که میتواند به بهبود عملکرد مدل در پیشبینی دادههای جدید کمک کند.
4. استفاده از Dropout
یک روش است که در شبکههای عصبی برای کاهش بیشبرازش استفاده میشود. در این روش، برخی از سلولهای عصبی به صورت تصادفی حذف میشوند تا شبکه برای تطبیق با دادههای جدید آماده شود.
Dropout یکی از روشهای مهم برای مقابله با بیشبرازش در شبکههای عصبی است. در این روش، برخی از نورونهای شبکه به صورت تصادفی در هر دوره حذف میشوند. این روش باعث میشود که شبکه نتواند وابستگی بیش از حد به یک گروه خاص از نورونها پیدا کند و به جای آن، با استفاده از تمام نورونهای موجود در لایههای مختلف، ویژگیهای داده را استخراج کند.
با حذف برخی از نورونها، تعداد پارامترهای شبکه کاهش مییابد و این باعث کاهش بیشبرازش میشود. همچنین، با اعمال Dropout، شبکه به مقداری مشابه با یادگیری چندین شبکه کوچک با وزنهای مختلف آموزش داده میشود که این باعث عملکرد بهتر شبکه بر روی دادههای جدید میشود.
استفاده از Dropout به صورت یک لایه Dropout در شبکه انجام میشود، که باعث حذف تصادفی برخی از نورونها در هر دوره میشود. مقدار Dropout میتواند بین 0.1 تا 0.5 باشد و معمولاً برای شبکههای عمیق از مقادیر بزرگتری استفاده میشود.
در کل، استفاده از Dropout یک روش مهم در مقابله با بیشبرازش است که میتواند به بهبود عملکرد شبکه در پیشبینی دادههای جدید کمک کند.
5. انتخاب فراپارامترهای مناسب
انتخاب فراپارامترهای مناسب، شامل انتخاب مقدار مناسب برای نرخ یادگیری، تعداد لایهها و تعداد نرونها، میتواند به کاهش بیشبرازش کمک کند. فراپارامترها همان پارامترهایی هستند که باید قبل از آموزش مدل تعیین شوند و تنظیم آنها میتواند به بهبود عملکرد مدل کمک کند. در اینجا به برخی از هایپرپارامترهای مهم در شبکههای عصبی و روشهای انتخاب آنها میپردازیم:
- تعداد لایهها: تعداد لایهها در شبکه عصبی میتواند بر کیفیت و سرعت آموزش و بیشبرازش تأثیر بگذارد. برای مدلهای ساده، تعداد لایههای کم معمولا مناسب است و برای مدلهای پیچیدهتر، تعداد لایههای بیشتر ممکن است بهتر باشد.
- تعداد نورونها: تعداد نورونها در هر لایه نیز میتواند بر کیفیت و سرعت آموزش و بیشبرازش تأثیر بگذارد. برای مدلهای ساده، تعداد نورونهای کم معمولاً مناسب است و برای مدلهای پیچیدهتر، تعداد نورونهای بیشتر ممکن است بهتر باشد.
- مقدار Dropout: مقدار Dropout میتواند به کاهش بیشبرازش کمک کند. این مقدار باید به گونهای تنظیم شود که کمک کند به کاهش بیشبرازش، اما همزمان عملکرد مدل را بهبود بخشد.
- مقدار نرخ یادگیری (learning rate): مقدار learning rate نیز میتواند بر بهبود عملکرد مدل تأثیر بگذارد. این مقدار باید به گونهای تنظیم شود که مدل به سرعت و بهبود عملکرد مناسب دست پیدا کند.
- تعداد دورههای آموزش: تعداد دورههای آموزش نیز میتواند بر بهبود عملکرد مدل تأثیر بگذارد. باید به گونهای تنظیم شود که مدل به سرعت و بهبود عملکرد مناسب دست پیدا کند و به همین دلیل، باید به صورت تجربی تنظیم شود.
برای انتخاب فراپارامترهای مناسب، میتوان از روشهای مختلفی مانند Grid Search، Random Search و Bayesian Optimization استفاده کرد. در روش Grid Search، مقادیر مختلف فراپارامترها امتحان میشوند و بهترین مقدار برای هر هایپرپارامتر انتخاب میشود. در روش Random Search، مقادیر تصادفی برای هایپرپارامترها امتحان میشوند وبهترین مقدار برای هر هایپرپارامتر انتخاب میشود. در روش Bayesian Optimization با استفاده از تئوری بیزین، پارامترهای بهینه برای مدل پیدا میشوند.
در کل، انتخاب فراپارامترهای مناسب برای شبکه عصبی یک چالش مهم در آموزش مدل است. با استفاده از روشهای مناسب برای تنظیم هایپرپارامترها، میتوان به بهترین عملکرد مدل بر روی دادههای جدید دست یافت.
6. جمعآوری بیشترین تعداد دادههای آموزش
جمعآوری بیشترین تعداد دادههای آموزش ممکن، میتواند به کاهش بیشبرازش کمک کند. جمعآوری بیشترین تعداد دادههای آموزش به معنای جمعآوری تعداد زیادی داده برای آموزش مدل است. با جمعآوری بیشترین تعداد دادههای آموزش، میتوان به بهبود عملکرد مدل بر روی دادههای جدید دست یافت. در جمعآوری دادههای آموزش، باید به چند نکته توجه کرد:
- تنوع دادهها: دادههایی که جمعآوری میشوند باید تنوع کافی داشته باشند تا مدل بتواند به خوبی از آنها یاد بگیرد. به عنوان مثال، برای آموزش یک مدل تشخیص تصویر، باید از تصاویر مختلف با اندازهها و شرایط مختلف استفاده کرد.
- کیفیت دادهها: دادههایی که جمعآوری میشوند باید کیفیت خوبی داشته باشند تا مدل بتواند به بهترین شکل از آنها یاد بگیرد. برای مثال، برای آموزش یک مدل پردازش زبان طبیعی، باید برای جمعآوری دادهها به دقت تایپ و علامتگذاری دادهها توجه کرد.
- حجم دادهها: حجم دادههای جمعآوری شده باید به اندازهای باشد که مدل بتواند به خوبی از آنها یاد بگیرد. برای مثال، برای آموزش یک مدل پردازش زبان طبیعی، باید حداقل چند هزار داده جمعآوری شود تا مدل بتواند به خوبی یاد بگیرد.
- تعداد دستهها: تعداد دستههای دادههای جمعآوری شده باید کافی باشد تا مدل بتواند به خوبی از آنها یاد بگیرد. به عنوان مثال، برای آموزش یک مدل تشخیص تصویر، باید از دستههای مختلف مثل تصاویر از حیوانات، صنایع دستی، آسمان شب و ... استفاده کرد.
در کل، جمعآوری بیشترین تعداد دادههای آموزش برای بهبود عملکرد مدل بسیار مهم است. با انتخاب دادههای مناسب و تنوع کافی، میتوان به بهترین عملکرد مدل بر روی دادههای جدید دست یافت. همچنین، بهتر است دادهها را پس از جمعآوری، تمرین و پاکسازی کنید تا دادههای نامناسب و پوچ در مدل شما تأثیر منفی نگذارند. همچنین، در صورتی که حجم دادههای جمعآوری شده کافی نیست، میتوانید از روشهای تولید داده مانند augmentation استفاده کنید تا تنوع بیشتری در دادههای آموزش به دست آورید.
7. توقف زودهنگام (Early Stopping)
توقف زودهنگام یکی از روشهایی است که در آموزش مدلهای یادگیری ماشین مورد استفاده قرار میگیرد. هدف از این روش، کاهش زمان و هزینه آموزش مدل و جلوگیری از بیشبرازش است. در این روش، آموزش مدل در صورتی که دقت آن بر روی دادههای ارزیابی بهبود نیابد، متوقف میشود.
برای استفاده از این روش، دادههای آموزش به دو بخش تقسیم میشود: بخش آموزش و بخش ارزیابی. در هر دور از آموزش، دقت مدل بر روی دادههای ارزیابی محاسبه میشود. اگر دقت مدل در دورهای متعدد از آموزش رو به کاهش باشد، به این معنی است که مدل دچار بیشبرازش شده است و لازم است که آموزش مدل متوقف شود.
در این روش، یک پارامتر جدید به نام صبر زمانی (patience) تعریف میشود که تعیین میکند چند دوره از آموزش باید صبر کرد تا دقت مدل دوباره بهبود پیدا کند. در صورتی که دقت مدل در یک دوره از آموزش به اندازه کافی بهبود نیافت، به این معنی است که مدل به حداکثر دقت خود رسیده است و آموزش متوقف میشود.
استفاده از توقف زودهنگام میتواند بهبودی در عملکرد مدل داشته باشد و همچنین زمان و هزینه آموزش را کاهش دهد. با این حال، باید به این نکته توجه کرد که استفاده از پارامتر صبر زمانی باید با دقت تنظیم شود تا بهبودی در عملکرد مدل به نحو احسن انجام شود. همچنین، اگر مدل دچار بیشبرازش نشده باشد، استفاده از این روش ممکن است باعث کاهش دقت مدل شود.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.



















نظر شما چیست؟