









پردازش کلان داده چیست؟
تجزیه، تحلیل و پردازش کلان داده به یکی از مهمترین روندهای تحقیقاتی تبدیل شده و فرصتهای شغلی خوبی برای توسعهدهندگان آشنا به تکنیکهای پردازش کلان داده فراهم کردهاند. یک دانشمند علم داده یا برنامهنویس مسلط به پردازش کلان داده میتواند از مجموعه ابزارهای تخصصی در این زمینه برای تحلیل زبان (Language Analysis)، پیشنهاد فایلهای ویدئویی (Recommending Videos) یا پیشنهاد محصولات جدید با توجه به دادههای بازاریابی یا دادههای جمعآوری شده از مشتریان استفاده کند. بهطور کلی، هنگامی که درباره تکنیکهای پردازش کلان داده در علم داده صحبت میکنیم، در اصل به تکنیکهایی اشاره داریم که در حوزه خاصی بهنام علم داده در مقیاس وسیع (large Scale Data Science) استفاده میشوند.
مهمترین ابزارهای پردازش کلان داده
با رشد انفجاری اطلاعات و افزایش دادههایی که روزانه توسط منابع مختلف تولید میشوند با پدیده کلان داده (Big Data) روبرو هستیم. بنابراین، باید از ابزارهای مناسب برای ثبت، نگهداری و تحلیل این حجم عظیم از دادهها استفاده کنیم. پیشرفت دستگاههای محاسباتی و پیدایش فناوریهایی مثل رایانش ابری (Cloud Computing) دسترسی به این دادهها و پردازش آنها را سادهتر از قبل کرده است. هرچند هنوز هم برای جمعآوری و تحلیل درست دادهها باید مدت زمان زیادی صرف شود. به همین جهت ضروری است با روش تحلیل کلان داده و مباحث مرتبط با آن آشنا باشیم و بدانیم چگونه باید از تکنیک شبکهای کردن و ارتباط گرهها برای این منظور استفاده کرد. یکی از مهمترین مدلهای ذخیرهسازی توزیع شده دادهها و پردازش کلان داده مدل نگاشتکاهش (MapReduce) است. مدل MapReduce، روشی بهینه برای مدیریت و پردازش کلان داده است که اجازه میدهد ابتدا دادهها را با استفاده از یک صفت (Attribute)، فیلتر یا دستهبندی خاص نگاشت کرد و با استفاده از یک مکانیزم تبدیل (Transformation) یا تجمیع (Aggregation)، دادههای نگاشت شده را پردازش کرد.
تحلیل کلان داده و ساختار شبکه اجتماعی
کلان دادهها رویکردی است که روشهای تجزیه و تحلیل، استخراج سیستماتیک اطلاعات و محاسبه روی حجم عظیمی از دادهها را ممکن میکند. در بیشتر موارد نمیتوان با نرمافزارهای کاربردی پردازش داده سنتی کلان دادهها را پردازش کرد، زیرا اگر این حجم از دادهها به ساختار جدولی تبدیل شوند، ستونها (فیلدها) و سطرهای (رکوردها) زیادی خواهیم داشت. مهمترین چالشهای پیرامون تحلیل کلان داده به ترتیب دریافت دادهها (capturing data)، ذخیره دادهها (data storage)، تجزیه و تحلیل دادهها (data analysis)، جستوجو (search)، اشتراکگذاری (sharing)، انتقال (transfer)، مصورسازی (Visualization)، اجرای پرسوجو (querying)، بهروزرسانی (updating) و مسائل حریم خصوصی (information privacy) است.
در ابتدا کلان داده، پیرامون سه مفهوم کلیدی حجم، تنوع و سرعت متمرکز بود. به این معنا که روشهای تحلیل کلان داده باید بتوانند حجم زیادی از اطلاعات که تنوع زیادی دارند را در زمان مناسب و سرعت زیاد پردازش کند، با اینحال، امروزه مفاهیم کلیدی این حوزه از رقم چهلودو مورد نیز فراتر رفتهاند. همین موضوع باعث شده تا فرایند نمونهگیری (Sampling) سخت شود.
به کارگیری کلان داده در دنیای کسبوکار
در دنیای امروز حجم عظیم اطلاعات، جنبههای مختلف زندگی انسانها را تحت تاثیر قرار داده و نقش مهمی در تصمیمگیریها دارد. کلان دادهها با ارایه مجموعه بزرگی از اطلاعات و ویژگیهای مرتبط با آنها مزایای زیادی برای کسبوکارها دارند.
از ویژگیهای شاخص کلان دادهها باید به حجم بالا، تنوع در ساختار، سرعت تولید دادهها و تغییرپذیری آنها در طول زمان اشاره کرد. دسترسی به کلان دادهها میتواند نقش مهمی در شناخت رفتار مخاطب، برنامهریزی کمپینهای تبلیغاتی، تصمیمگیری درباره مسیر بازاریابی، پیادهسازی استراتژیهای بازاریابی الکترونیکی، استراتژیهای تولید محتوا و تصمیمات خرد و کلان داشته باشد. بنابراین، باید بگوییم استفاده از کلان دادهها، فرآیند بازاریابی و فروش را بهبود میبخشد، زیرا میتوان از استراتژیهای بازاریابی بهینهتر و شخصیسازی شده استفاده کرد. همراستا بودن محصولات یا خدمات یک سازمان با نیازهای روز مشتریان و بازار و شخصیسازی محتوای تولید شده بر اساس رفتار مخاطب، علاوه بر جلب توجه مخاطبان و افزایش مشتریان میتواند نقش مهمی در رضایتبخشی مشتریان داشته باشد.
کلان داده در مقابل هوش تجاری
در حالی که برخی از کاربران تصور میکنند این دو فناوری با یکدیگر یکسان هستند، اما در واقعت اینگونه نیست، زیرا هر یک از این فناوریها مفاهیم و کاربردهای خاص خود را دارند. هوش تجاری از ابزارهای ریاضی کاربردی و آمار توصیفی با دادههایی با تراکم اطلاعات بالا برای اندازهگیری موارد، تشخیص روندها و مدلسازی استفاده میکند. در نقطه مقابل کلان دادهها از تجزیه و تحلیل ریاضی، بهینهسازی، آمار و مفاهیم استنباطی برای کشف قوانین (روشهای همبستگی، روابط غیرخطی و روابط علت و معلولی) مجموعه زیادی از دادهها استفاده میکند. به این ترتیب با استفاده از روابط و وابستگیها، امکان پیشبینی رفتار پدیدهها امکانپذیر میشود.
تحلیل کلان داده و تحلیل شبکههای اجتماعی
در دنیای کلان دادهها شبکه و شبکهسازی مبتنی بر روشهای ریاضی قابل درک و تجزیه و تحلیل، روشی برای نشان دادن اطلاعات است. شبکهها متشکل از گروهی از گرهها (Nodes) هستند که توسط پیوند (Link) یا یال (Edge) به هم متصل میشوند و میتوانند نشاندهنده هدایت جهتدار از یک گره به گره دیگر یا بدون جهت (دوطرفه) باشند. از این منظر یک شبکه همانند یک گراف (Graph) قابل بررسی است. صفحات وب نمونههایی از شبکههای جهتدار هستند که صفحات یک گره و ابرپیوند (Hyperlink) یک یال را توصیف میکنند.
امروزه سازمانهای بزرگ از شبکهها برای یافتن دقیق اجتماعات استفاده میکنند. این گرهها راسهایی دارند که بهشکل گروهی متصل هستند، اما ارتباط کمی با گروههای دیگر دارند. رویکرد فوق شبیه به افرادی است که در شبکههای اجتماعی با علایق مشابه حضور دارند یا دانشمندانی را نشان میدهد که در یک زمینه علمی به فعالیت اشتغال دارند یا با یکدیگر همکاری میکنند. موضوع مورد توجه در این بین متغیرهای مربوط به این داده است که باید مطالعه شوند. این کار ممکن است به بهبود دقت در شناسایی جوامع و خوشهها (Clusters) کمک کند. با گسترش شبکههای اجتماعی مبحث کلان داده نزد متخصصان داده (Data Scientist) بیش از هر زمان دیگری مورد توجه قرار گرفته است.
گروهها و اطلاعات گرهها
شناخت جوامع درون شبکه، ساختار آنها را روشن میکند و در عمل مزایای زیادی دارد. بهطور مثال، افرادی که عضو گروههای شبکه اجتماعی خاصی هستند، علایق مشابه دارند، بنابراین توصیهها یا پیشنهادات یکسانی میتوان برای آنها در نظر گرفت، بهطوری که با اعمال خطمشی صحیح در مورد هر یک از آنها امکان ارایه اطلاعات هدفمند برای آنها وجود دارد.
بهطور معمول، روشهای فعلی شناسایی جوامع درون مجموعه دادهها یا با استفاده از روشهای آماری با تکیه بر برنامههای کامپیوتری یا مبتنی بر مدل، بهشکل الگوریتمی قابل انجام است. یکی از این روشها، مدل بلوک تصادفی (stochastic block model) است.
در مدل فوق، مفروض است که گرههای درون جامعه هنگام تعامل با گرههای دیگر رفتار یکسانی دارند. بهطور مثال، اگر افراد A و B به یک جامعه تعلق داشته باشند، هنگام برقراری ارتباط با هر شخص دیگری مثل C، رفتار مشابهی دارند. اینکار چه سودی دارد؟ شناخت جوامع درون شبکهها، ساختار آنها را روشن میکند و مزایای عملی مانند توصیههای بهتر در جستوجوی وب یا ارایه تبلیغات هوشمند را به همراه دارد. به همین دلیل در دنیای امروز تحلیل کلان داده و ساختار شبکه اهمیت زیادی دارد.
در ساختار یک شبکه یا گراف، گرهها دارای خصوصیاتی هستند که میتوانند به تعیین ساختارهای جامعه در دادهها کمک کنند. بهطور مثال، کاربران شبکههای اجتماعی، مشخصات کاربری خود را به گرهها متصل میکنند. در شبکههای علمی مثل Research Gate مقالات علمی ذکر شده حاوی اطلاعات نویسنده، کلمات کلیدی و خلاصه مقالات است. به این ترتیب هر گره شامل اطلاعاتی از نویسنده و مقاله علمی است.
به این نکته دقت کنید که این نوع اطلاعات و متغیرها، همراه با یالهای گرافها، از طریق دو رابطه متفاوت نشان داده شده در شکل 1 اجازه میدهند وجود جوامع یا گروههای مرتبط را بهتر استنباط کنیم.
در شبکههای واقعی، گرهها حاوی ویژگیهایی هستند که میتوانند به مشخص کردن ساختارهای جامعه در دادهها کمک کنند. به عنوان مثال، شبکههای اجتماعی نمایههای کاربری را به گرهها متصل میکنند و مقالات علمی ذکر شده حاوی اطلاعات نویسنده، کلمات کلیدی و چکیدهها هستند. دکتر فنگ استادیار آمار دانشگاه کلمبیا در مقاله خود تحت عنوان «A needle in a haystack – the future of big data» به این نکته اشاره دارد که این نوع نمایش اطلاعات و یالها، بهتر میتوانند وجود جوامع را از طریق دو رابطه متفاوت نشان دهند. در شکل1، دو رابطه متفاوت بین اطلاعات گره X، اطلاعات جامعه c و ماتریس تعدیل کننده A را مشاهده میکنید.

شکل 1
تحلیل مجانبی (Asymptotic analysis)
با توجه به اینکه ساختار ماتریسهای A و X و بردار c مشخص نیست، متخصصان داده به کمک دادهها، این بخشها را تخمین میزنند. بهطور مثال، فرایند محاسبه و تحلیل کلان داده میتواند بر مبنای ماتریس شبکه (Network Matrix)، ماتریس اتصالات (Connections Matrix) یا یالها و ماتریس خصوصیات گرهها (Nodal Properties) باشد. در بیشتر موارد خصوصیات گرهها بهنام ماتریس وابستگی (Covariates) توصیف میشود. ماتریس وابستگی (Covariate) هنگامی استفاده میشود که یک متغیر خارج از حیطه ارتباط بین متغیرها، معرفی میشود تا ارتباط بین متغیرهای اصلی نمایانتر شود. با استفاده از روشهای تکراری (Iterative approach)، گروهها یا جامعهها (Communities) شناخته و تشخیص داده میشوند. همانگونه که اشاره شد، جامعهها، گرههایی هستند که با یکدیگر یک گروه را تشکیل میدهند و شباهت زیادی به یکدیگر دارند. روشهای دیگر انجام محاسبات در این زمینه تابع درستنمایی (Likelihood-based) است که به نقاط اولیه حساس است.
بهکارگیری مدل شبکه برای شناخت جامعه
در این بخش به معرفی یک مثال در حوزه تحلیل کلان داده میپردازیم. در این مثال مدارس آمریکا و شبکه تعاملی (Interaction Network) میان دانش آموزان مورد بررسی قرار گرفته است. به این معنی که خصوصیات دانشآموزان تحلیل و شرایط تعامل بین آنها تجزیه و تحلیل میشود. به این ترتیب میتوانیم گروههای همسان بین دانشآموزان را مشخص کنیم. در این مثال به مسئله دانشآموزان میپردازیم. در این قسمت، ویژگیهای هر گره، بیش از یک متغیر بوده و مسئله به صورت چندمتغیره خواهد بود.
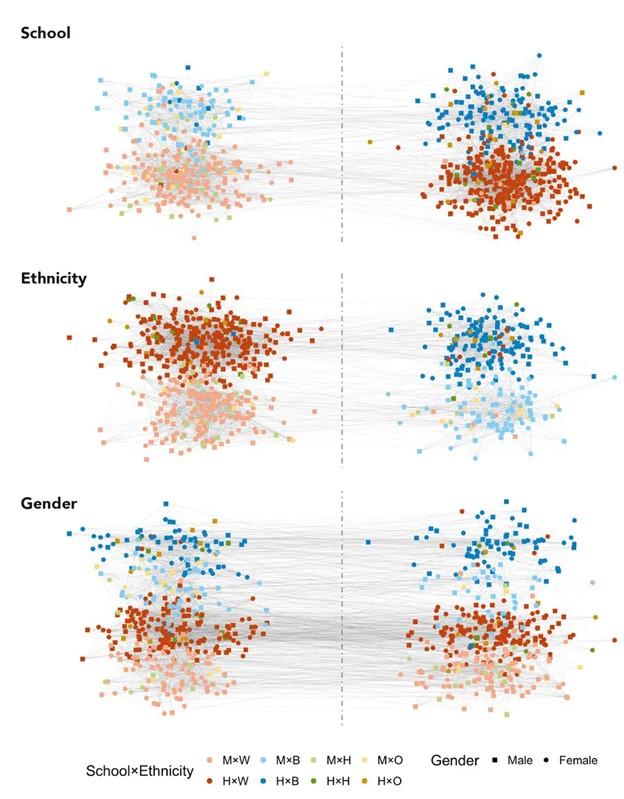
شکل 2
در این مثال از شبکه تعامل در دبیرستان ایالات متحده استفاده شده است. اطلاعات مربوط در این مثال از مطالعه ملی روی 795 دانشآموز بین 9 تا 12 سال در دبیرستان و بین هفت تا هشت سال در دبستان انجام شده است. دانشآموزان این مجموعه دارای چند ویژگی مثل نمره (Grade)، جنسیت (Gender)، قومیت (Ethnicity) و تعداد دوستان (حداکثر ده اسم) هستند. در جوامعی مانند این مثال، اطلاعات گرهها مانند سن یا قومیت اغلب میتوانند یک حقیقت زمینهای (Ground Truth) برای شناخت جامعه در اختیار ما قرار دهند. به این ترتیب براساس این واقعیت، انتظار داریم افرادی که همنژاد، هم جنس یا در یک مقطع تحصیلی هستند، بیشتر با یکدیگر به تعامل بپردازند. در شکل2، دو جامعه براساس رده تحصیلی و متغیر (School) نشان داده شدهاند. همانگونه که مشاهده میکنید گروه دبستان در سمت چپ و گروه دبیرستان در سمت راست تعریف شدهاند. بیشترین تعامل درون هر یک از جوامع اتفاق داده و ارتبط بین این دو جامعه طبق شبکه ترسیم شده، ضعیف است.
تفکیک دانشآموزان به دو جامعه بر مبنای نوع مقطع تحصیلی در تحلیل کلان داده
در این تحلیل از متغیرهای مختلفی استفاده شده است. گروه اول در سمت چپ و گروه دوم در سمت راست قرار گرفتهاند. البته بین این دو گروه تعاملاتی وجود دارد، اما تراکم آنها نسبت به درون گروه یا جامعهها کمتر است. متغیرهای استفاده شده در این تصویر به شرح زیر هستند:
- M: دانشآموز مقطع دبستان
- H: دانشاموز مقطع دبیرستان
- B: سیاهپوست (آفریقایی) – نژاد
- W: سفید پوست (اروپایی) – نژاد
- H: سرخپوست (آمریکای شمالی) – نژاد
- O: زرد پوست (آسیایی) – نژاد
- Male: مذکر با نمایش به صورت مربع توپر
- Female: مونث با نمایش به صورت دایره توپر
در ردیف Ethnicity نتیجه تفکیک شبکه به دو جامعه برحسب نژاد نشان داده شده است. در این بخش کلان داده و ساختار شبکه به خوبی مشاهده میشود. در تحلیل فوق زرد و سرخپوستان بین دو جامعه سفید و سیاه پوستان پخش هستند. میتوان نشان داد که به این ترتیب تعامل بین سفیدپوستان جدای از سیاهپوستان است و هر یک از این نژادها علاقمند به تعامل با همنژادهای خود هستند. در بخش آخر (Gender) تفکیک جامعه به دو گروه براساس جنسیت انجام شده که نشان میدهد صرف نظر از نژاد و مقطع تحصیلی، دختران تشکیل یک جامعه و پسران تشکیل جامعهای دیگر دادهاند.
کلام آخر
همانگونه که مشاهده کردید، بهکارگیری روشهای تحلیل کلان داده برای تجزیه و تحلیل شبکههای اجتماعی رویکردی است که بهشکل جدی در دستور کار شرکتهای خصوصی و نهادهای دولتی کشورهای مختلف قرار گرفته است. بر مبنای خصوصیاتی که گرهها و یالهای شبکه دارند، امکان تعیین یا تفکیک جوامع یا گروههای همسان وجود دارد. دکتر فنگ در مقاله خود به این نکته اشاره دارد که تشخیص الگوهای جامعه بر مبنای مجموعه دادهها با استفاده از شبکهسازی استاندارد (مانند مدل بلوک تصادفی) خروجی کاملا ضعیفی دارد که اغلب یافتههای غیر قابل اعتمادی را ارایه میکند. در حالی که بهکارگیری مدلهای آماری برای شناسایی جوامع در شبکههایی که بر مبنای دادههای شبکهای پدید آمدهاند و شامل ویژگیهای مختص به هر گره مثل علایق هستند در عمل نتایج دقیقی را ارایه میکنند. در بسیاری از رشتهها یا صنایع، مانند پزشکی یا انتخاب دارو بر مبنای دادههای ژنتیکی این رویکرد بهشکل قابل توجهی موثر است. حال اگر از خانواده وسیعتری از ویژگیهای گره یا تعداد بیشتری از آنها و در شبکههایی که دارای تراکم کم هستند از رویکردهای آماری استفاده شود، نتایج بهدست آمده نویدبخش خواهند بود.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.




















نظر شما چیست؟