


جی پاریخ مدیر بخش مهندسی و زیرساخت فیسبوک میگوید: «در حال حاضر، هوش مصنوعی به بخشهایی از فیسبوک مانند Facebook Newsfeed قدرت مضاعفی بخشیده است.» وی اعتقاد دارد: «هوش مصنوعی به ما کمک کرده است تبلیغات بهتری به کار بگیریم و در نتیجه سایتهایی امنتر برای افرادی بسازیم که روزانه از فیسبوک استفاده میکنند.»
مطلب پیشنهادی

نورم جوپی مهندس بخش سختافزارهای برجسته گوگل نیز در این زمینه میگوید: «یادگیری ماشینی فرآیند ساخت برنامههای کاربردی هوشمند را دگرگون کرده است و به توسعهدهندهها یاد میدهد چگونه این برنامهها را بسازند، بهطوری که مزیتهای متعددی برای مشتریان داشته باشند. ما از دیدن این امکانات در زندگی روزمره هیجانزده هستیم.»
بخش قابل توجهی از قدرت محاسباتی مورد نیاز برای اجرای فرآیندهای یادگیری ماشینی در سرورها و مراکز داده صرف اجرای سرویسهای مختلف روی بسترهای کلاود میشود. در نتیجه، سازندگان و ارائهدهندگان کلاود، فناوریها و تکنیکهای شتابدهنده سختافزاری را طراحی و تهیه کردند که بهطور مشترک در سیستمهای محاسباتی با کارایی بالا (HPC) به کار گرفته شده و رویکردی برای استفاده از یادگیری ماشینی در اکوسیستمهای محاسباتی ابرمقیاس محسوب میشود.
در این صنعت شرکتهای زیادی با یکدیگر به رقابت میپردازند، اما شاید بتوان از بزرگانی مانند گوگل، فیسبوک و آیبیام بهعنوان بازیگران اصلی میدان نام برد که جنگ واقعی نیز میان همینها است. این سه شرکت بر سر ورود به بازار مراکز داده با یکدیگر رقابت شدیدی دارند و البته در این میان دیگر شرکتهای ارائهدهنده خدمات و پلتفرمهای کلاودی و شرکتهای سازنده پردازنده مانند اینتل و انویدیا نیز بیکار ننشستهاند.
سختافزار TPU گوگل
شبکههای عصبی کامپیوترهای جدیدی هستند که با تقلید از فرآیندهای یادگیری مغز انسان سعی دارند چالشهای جدید را حل کنند؛ فرآیندهایی که به قدرتهای محاسباتی بسیار بالایی نیاز دارند. بههمین دلیل، بازیگران اصلی صنعت محاسباتی بهسوی سیستمها و سرورهایی با پردازندههایی فراتر از پردازندههای سنتی و رایج حرکت کردند و بهدنبال ساخت سیستمهایی هستند که بتوانند نقش شتابدهنده را ایفا کنند. یکی از این شتابدهندهها که در اواسط سال ۲۰۱۶ معرفی شد، چیپست جدید شرکت گوگل بود.
این شرکت از TPU (سرنام Tensor Processing Unit) رونمایی کرد که یک چیپست ASIC برای پلتفرم TensorFlow است. TensorFlow یک کتابخانه منبع باز یادگیری ماشینی است که توسط خود گوگل توسعه داده شده است. ASIC (سرنام Application Specific Integrated Circuits) نیز اصطلاحاً یک نوع چیپست است که میتواند برای کاربردهای خاصی سفارشیسازی شود. برای نمونه، اخیراً در سیستمهای بیتکوین از انواع چیپستهای ASIC استفاده شده است. گوگل با استفاده از چیپست TPU توانسته است تعداد عملیات بیشتری را در ثانیه روی یک سیلیکون فشردهسازی یا اصطلاحاً اجرا کند. (شکل ۱)

شکل ۱- چیپست TPU شرکت گوگل که روی یک بورد و بههمراه هارددیسک مجتمعسازی شده است و روی رکهای مرکز داده سوار میشود.
نورم جوپی مهندس بخش سختافزارهای برجسته گوگل در وبلاگ این شرکت میگوید: «بیش از یک سال است که توانستیم TPU را درون یک مرکز داده گوگل اجرا کنیم و یادگیری ماشینی برای ما بهاندازه بهبود کارایی در هر وات بازدهی داشته است.» نورم یادآوری میکند این نتیجه با رشد فناوری در حدود هفت سال آینده برابری میکند و البته این سرعت رشد نزدیک به سه برابر قانون مور است. چیپستهای TPU روی بردهایی پیادهسازی شدند که با هارددیسکها نیز مجتمع شده و بهصورت یک اسلات روی رکهای مراکز داده نصب میشوند. (شکل ۲)

شکل ۲- یک رک سفارشیسازی شده بر اساس چیپستهای TPU برای یادگیری ماشینی.
گوگل از زیرساخت TPU برای قدرتمندسازی AlphaGo استفاده میکند؛ برنامهای که توانسته است در لیگ بازیهای Go فردی مانند Lee Sedol را شکست بدهد که نفر اول رتبه جهانی این بازی است. Go یک بازی سخت و پیچیده فکری است که معمولاً انسانها در مقابله با کامپیوترها پیروز هستند و البته در چند سال اخیر رقابت نفسگیری با یکدیگر داشتهاند. بازی Go همانند بازی شطرنج و دیگر بازیهای مبتنی بر تخته، در میان انسانها قدمت بسیار بالایی دارد و چندین هزار سال است که بازی میشود. اما کامپیوترها در چند سال اخیر شروع به بازی Go کردند و در این مدت کم به مدد هوش مصنوعی توانستند رقبای سرسختی برای انسانها شوند و اکنون گوگل با استفاده از TPU و یادگیری ماشینی توانسته نفر اول لیگ جهانی Go را هم شکست بدهد. TPU به نرمافزار AlphaGo کمک کرد تعداد محاسبات و چالشهای سختتری را پردازش و حل کند و در نتیجه روشهای بیشتری برای بازی در اختیار داشته باشد.
جوپی در وبلاگ گوگل مینویسد: «هدف ما این است که به رهبر بازار در حوزه یادگیری ماشینی تبدیل شویم و نوآوریهای قابل دسترسی برای مشتریان خودمان بسازیم. ساختن و تعبیه تعداد زیادی TPU در یک پشته زیرساختی و سختافزاری به ما اجازه میدهد شرکت گوگل را به قدرتی برسانیم که بتواند هرگونه نرمافزاری مانند TensorFlow و Cloud Machine Learning را با استفاده از ظرفیتهای شتابدهندگی پیشرفتهای توسعه دهد.»
قدرتمندسازی زیرساخت هوش مصنوعی فیسبوک با Big Sur
آزمایشگاه هوش مصنوعی فیسبوک از یک GPU برای شتاببخشی به پردازشهای عظیم اطلاعات و افزایش قدرت محاسباتی سیستمهای یادگیری ماشینی خود استفاده میکند. پاریخ میگوید: «ما سرمایهگذاری بسیار زیادی روی هوش مصنوعی در این زمینه داشتیم.» Big Sur یک سیستم مبتنی بر پلتفرم شتابدهنده محاسباتی تسلای انویدیا است که از هشت هسته پردازشی GPU با توان مصرف انرژی حداکثری ۳۰۰ واتی برای هر هسته سود میبرد و از انعطافپذیری بالایی در پیکربندی براساس کانکشنهای PCI-e مختلف برخوردار است. سیستم Big Sur میتواند روی یک سختافزار رک منبع باز و انعطافپذیر سوار شود و بهراحتی در مراکز داده و سیستمهای نیازمند پردازشهای محاسباتی یادگیری ماشینی و هوش مصنوعی نصب و راهاندازی شود. (شکل ۳)

شکل ۳- سختافزار رک منبع باز Big Sur فیسبوک برای محاسبات هوش مصنوعی در مقیاسهای بسیار بزرگ.
فیسبوک سرورهای جدید خود را بر این اساس بهینهسازی کرده است تا دما و حرارت بالایی را تحمل کنند و از سوی دیگر مصرف انرژی را بهینه کنند.. این بهینهسازیها به فیسبوک اجازه میدهد، سرورهای جدید و سیستم شتابدهنده محاسباتی Big Sur را در مراکز داده سنتی و فعلی در کنار دیگر سرورها و تجهیزات زیرساختی استفاده و اجرا کند. کارایی بالا و تأخیر پایین سیستم Big Sur به فیسبوک اجازه میدهد اطلاعات بیشتری را در یک ثانیه پردازش کند و در نتیجه شبکههای عصبی در زمانهای بسیار کمتری بتوانند آموزش ببینند. پاریخ در این زمینه میگوید: «این یک بهبود قابل توجه در کارایی مراکز داده و یادگیری ماشینی است. ما میتوانیم هزاران ماشین اینچنینی را در طول یک ماه نصب و مستقر کنیم. همچنین، میتوانیم این فناوری را در محصولات دیگر پیادهسازی کنیم.»
تمرکز اینتل روی FPGA
در جبهه سختافزار، بهنظر میرسد شرکت انویدیا بیشترین سود را از تمرکز روی یادگیری ماشینی در صنعت مراکز داده میبرد. زیرا مرتباً پردازندههای محاسباتی گرافیکی (GPU) بهبودیافته را به بازیگران اصلی ابرمقیاس میفروشد. اما انویدیا تنها سازنده پردازندههای محاسباتی یادگیری ماشینی نیست و اینتل نیز دوست دارد در این بازی بزرگ نقش داشته باشد. اینتل اخیراً نمونههایی از یک ماژول تراشهای را تست و رونمایی میکند که ترکیبی از چیپستهای سنتی و مدارهای مجتمع دیجیتالی برنامهپذیر (FPGA) است؛ نیمههادیهایی که قابلیت برنامهپذیری مجدد برای انجام کارهای خاص و سفارشی را دارند. چیپستهای FPGA همانند چیپستهای ASIC هستند و به کاربران اجازه میدهند قدرتهای محاسباتی را برای برنامههای کاربردی و بار ترافیکی خاص بهبود و تقویت کنند. اما FPGA قابلیت برنامهپذیری مجدد برای کارهای جدید را هم دارند و یک گام پیشرفتهتر از ASIC هستند.
اینتل تمرکزش را روی چیپستهای FPGA گذاشته است تا بتواند نسل جدیدی از محصولات برای بارکاری و کارهای خاص و سفارشیسازی شده در صنعت مرکز داده بسازد. اینتل در سال ۲۰۱۵ نزدیک به ۱۶ میلیارد دلار برای خرید شرکت Altera هزینه کرد. Altera بازیگر بزرگ و اصلی در استفاده از چیپستهای FPGA و دیگر تجهیزات دیجیتالی برنامهپذیر (PLD) درون سیستمهای خودکار صنعتی است.
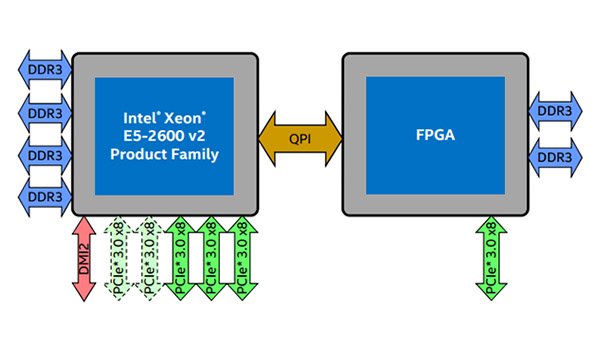
شکل ۴- معماری پردازندههای جدید اینتل برای یادگیری ماشینی متشکل از پردازندههای سنتی و پردازندههای برنامهپذیر FPGA.
روجن اسکیلرن مدیر بخش Cloud Service Provider Business اینتل در این زمینه میگوید: «ما باور داریم FPGA یک استراتژی بزرگ است. ما بههمراه بسیاری از سازندگان OEM و مشتریان خود در حال توسعه FPGA هستیم و بهزودی پیادهسازی و ساخت رسمی آنها را در رودمپ (roadmap) خود میآوریم.» بهطور ویژه، تمرکز اینتل روی گروه Super 7 از ارائهدهندگان خدمات کلاود است که نوآوریهایی در حوزه زیرساختهای ابرمقیاس پدید میآورند. Super 7 متشکل از شرکتهای آمازون، فیسبوک، گوگل، مایکروسافت، علیبابا، بایدو و تنسنت است. اینتل برنامهریزی کرده است تا سال ۲۰۲۰، بیش از ۳۰ درصد ارائهدهندگان خدمات کلاود از نودهای شتابدهنده مبتنی بر چیپستهای FPGA استفاده کنند. (شکل ۴)
حیله آیبیام: تسخیر بازار با واتسون
آبی بزرگ از روش دیگری میخواهد وارد دنیای هوش مصنوعی و یادگیری ماشینی شود. آیبیام این روزها بیشتر روی مفهوم «محاسبات شناختی» (cognitive computing) مانور میدهد و میخواهد مشتریان و کاربران بزرگ و گسترده را با ابرکامپیوتر واتسون خود هدف قرار دهد. واتسون از سال ۲۰۱۱ و پس از شکست دادن رقبای معروف انسانی خود در بازی Jeopardy بر سر زبانها افتاد. آیبیام سال به سال و گام به گام واتسون را به مهارتها و الگوریتمهای هوش مصنوعی و یادگیری ماشینی بیشتری مجهز کرد و سعی داشت هوش مصنوعی را به سمت و سوی چالشهای کنونی بازار هدایت کند تا از این طریق بتواند نشان بدهد ابرکامپیوتر واتسون چگونه مشکلات روزمره کاربران را حل میکند. در واقع، آیبیام مسیر متفاوتی از شرکتهای دیگر برای حضور در عرصه میدان رقابتی یادگیری ماشینی انتخاب کرده است. (شکل ۵)

شکل ۵- تصویری از ابرکامپیوتر واتسون آیبیام که توانایی تحلیل اطلاعات بسیار شگفتانگیزی دارد.
واتسون متشکل از مجموعه بسیار زیادی الگوریتم و نرمافزار پیادهسازی و اجرا شده روی سرورهای Power 750 است. واتسون یاد گرفته است چگونه با استفاده از اطلاعات خام، خود را برنامهریزی و دستورالعمل صادر کند. آیبیام میگوید واتسون یک ابزار بسیار قدرتمند برای شرکتهایی است که میخواهند از کلانداده سود ببرند.
استیون آبرامز مهندس برجسته مرکز تحقیقاتی توماس واتسون آیبیام میگوید: «ما شاهد رشد عظیمی از اطلاعات بودیم. اطلاعاتی که هیچ ساختاری نداشتند. تا به امروز، بسیار سخت بوده که اطلاعات را مهار و مدیریت کنیم و بفهمیم در اطراف این اطلاعات چه خبر است و چه کاری میشود انجام داد.» استیون در رویداد
DataCenterDynamics Enterprise نیویورک که اواسط سال ۲۰۱۶ میلادی برگزار شد، به همه حاضران نشان داد واتسون چگونه میتواند یک برنامه کاربردی خاص بسازد و مشتریان چگونه میتوانند با کمک واتسون نرمافزارهای خاص خود را بسازند. آیبیام میتواند تعاملهای بسیار درگیرانه و مشترک با کاربران حرفهای و بسیار بزرگ خود داشته باشد. این شرکت با کمک آیبیام و Cloud APIS (رابط برنامهنویسی برنامههای کاربردی) میتواند مدلهای مد نظر مشتریان را اجرا کند. امروزه شاهدیم که واتسون در بیمارستانها حضور پیدا میکند و یک زن سرطانی را بهبود میدهد. بعد وارد صنایع غذایی و آشپزی میشود. همین طور از بازار بورس و ساخت فیلمهای علمی تخیلی سر در میآورد.
آبرامز میگوید: «ما واتسون را طوری ساختیم تا شرکتهایی که نمیتوانند بهطور معمول از کسب و کار آیبیام استفاده کنند، از فناوریهای واتسون سود ببرند. ما بهسمتی حرکت میکنیم که فناوری را همانند یک مدل سلف سرویس ارائه بدهیم. ما بهطور جدی روی توسعهدهندهها تمرکز کردیم و به مردم کمک میکنیم از ۰ تا 100 را در کمترین زمان ممکن بروند.»

شکل ۶- نشست بررسی محاسبات شناختی واتسون در رویداد DataCenterDynamics Enterprise.
در پنل واتسون در رویداد DataCenterDynamics Enterprise، مشتریان مختلف توضیح دادند که چگونه توانستند با استفاده از واتسون اپلیکیشنهای خود را بسازند. برای نمونه:
• PurpleForge واتسون را طوری آموزش داده است تا به مهندسان خود پاسخهای سریعی بدهد و بتواند سؤالات بخش پشتیبانی را جواب دهد. واتسون تمام دفترچه راهنماها و جزییات متنی در دسترس را مطالعه کرده و با استفاده از آنها توانسته است یک دانش( یک شاخه علمی) را وارد یک پایگاه داده کند. این پایگاه داده میتواند به سؤالات در کمترین زمان به زبان طبیعی محاورهای انسان پاسخ دهد. برایان هارلی رییس و مدیرعامل PurpleForge میگوید: «واتسون اجازه داد کارهایی انجام بدهیم که هرگز تصور نمیکردیم در دنیای امروزی امکانپذیر باشند.»
• SparkCognition یک استارتآپ در حوزه امنیت اطلاعات است و از واتسون برای جمعآوری بانکهای اطلاعاتی آسیبپذیریها و فهرستسازی استفاده کرده است. در گام بعدی، از واتسون و این بانکهای اطلاعاتی برای ارائه مشاورههای بیدرنگ به متخصصان امنیتی سود میبرد. استوارت گیلن مدیر بخش توسعه کسب و کار این استارتآپ میگوید: «ما از واتسون برای شتاببخشی به ارائه راهکارهای مبتنی بر زمان برای جلوگیری از تهدیدات استفاده کردیم.»
• Equals 3 Media به بازارهای دیجیتالی اجازه میدهد از تحلیلهای کلانداده برای اصلاح تبلیغات و آگهیهای خود در جهت نیازهای کاربران و منافع خود استفاده کنند. Equals 3 از قابلیت «بینش شخصیت» (personality insights) واتسون برای جستوجو در شبکههای اجتماعی، دادهکاوی، استخراج اطلاعات و نشانههای مفید مورد نیاز آگهیدهندهها سود برد. برای نمونه، واتسون میتواند با استفاده از بینش شخصیت در بازار خودرو، از روی خودروی هر کاربر به علایق و برخی ویژگیهای شخصیتیش پی ببرد. مثلاً یک فرد علاقهمند به خودروهای با کارایی و سرعت بالا، شخصیتی ماجراجویانه دارد و کاربر دیگری با علاقهمندی به خودروهای امن و مطمئن، ممکن است شخصیتی مهربانانه و مادرانه داشته باشد.
بینش شخصیت یکی از جنبههای جذاب و کاربردی یادگیری ماشینی است که میتواند سطح کاربران، علایق و شخصیتهای آنها را برملا کند. واتسون همانند شبحی در آسمان است که همهچیز را میداند.
مدل تحویل کلاود
چه از واتسون استفاده شود یا هر سرویس محاسباتی دیگری واضح است که کلاود مدل اول و بلامنازع تحویل و ارائه خدمات یادگیری ماشینی به مشتریان است. گوگل، مایکروسافت، آمازون و وب سرویس همه در حال حاضر از خدمات مدیریتی کامل روی پلتفرمهای کلاود استفاده میکنند که اجازه قابلیتهای تحلیل اطلاعات و ساختن برنامههای کاربردی یا خدمات جدید را میدهد.
در نتیجه، استفاده از سختافزارهای پشتیبانی یادگیری ماشینی در مراکز داده ابرمقیاس به یک ضرورت و اولویت اول تبدیل شده است. این سختافزارها باید بتوانند مراکز داده را در سطح بسیار بالایی برای بهرهوریهای فوقالعاده و بار کاری بسیار حساس سفارشیسازی کنند. این خدمات نسبتاً جدید هستند و هنوز مشخص نیست اکوسیستم کلاود این خدمات را روی کلاودهای ثالث نگهداری میکند یا به سوی کاربران نهایی سوق میدهد. آنچه مسلم است، این خدمات جدید باعث تغییر آرایشی در اکوسیستم کلاود و شرکتهای ارائهدهنده خدمات محاسباتی روی کلاود میشود. اما برای صنعت مرکز داده، مزایای بهکارگیری یادگیری ماشینی تنها به سختافزار محدود نمیشود. گوگل از یادگیری ماشینی برای بهبود مصرف انرژی و بهرهوری سیستمها و خنککنندهها سود میبرد.
استفاده از سختافزارهای پشتیبانی یادگیری ماشینی در مراکز داده ابرمقیاس به یک ضرورت و اولویت اول تبدیل شده است.
جو کاوا معاون بخش عملیات مراکز داده گوگل میگوید: «ما از شبکههای عصبی برای رسیدن به مرزهای جدیدی از بهرهوری در سرورهای مراکز داده خود رسیدیم، حتی فراتر از آن چیزی که مهندسان ما در تجزیه و تحلیلهای خود بیان میکردند.» کاوا ادامه میدهد: «مراکز داده ما بسیار بزرگ و پیچیده هستند. تعداد بسیار زیاد پارامترها و عوامل عملیاتی باعث شدهاند افراد معمولی ابدا نتوانند درکی از چگونگی بهینهسازی یک مرکز داده گوگل داشته باشند. اما برای کامپیوترها این عوامل بیاهمیت و پیشپاافتاده هستند و بهسرعت میتوانند فهرستی از تنظیمات برای بهینهسازی مرکز داده به شما بدهند.»
کاو تأکید میکند: «ما در چند سال گذشته الگوریتمهایی را توسعه داده و آنها را براساس میلیاردها نقطه اطلاعاتی در سراسر مراکز داده گوگل در جهان آموزش دادیم. در حال حاضر، ما با استفاده از یادگیری ماشینی به تیمهای تجسم اطلاعات خود کمک میکنیم، بهطوری که تیم عملیات مرکز داده میداند چگونه باید سیستمهای تأسیسات و توزیع برق را نصب و راهاندازی کند تا حداکثر بهرهوری و بهینهسازی برای هر روز یک مرکز داده به دست بیاید.»
در آخرین موارد استفاده، شبکه عصبی توانایی پیشبینی بهرهوری مصرف انرژی مراکز داده گوگل با ۹۹.۶ درصد را داشتند. یادگیری ماشینی مجموعهای از توصیهها و تنظیمات کوچک را پیشنهاد میدهند که در نظر اول چندان مؤثر نیستند، ولی هنگامی که در سراسر یک مرکز داده و هزاران سرور و تجهیزات ذخیرهسازی مختلف اجرا شدند، به یک باره به صرفهجویی و بهرهوری عمدهای منجر میشوند.
==============================
شاید به این مقالات هم علاقمند باشید:








ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.
مطالب مرتبط






















نظر شما چیست؟