



در پرونده ویژه شماره 205 ماهنامه شبکه به بررسی سرویسهای پردازش ابری پرداختیم. تنوع در سرویسها (از سختافزار بهعنوان سرویس گرفته تا نرمافزارهای آماده به سرویسدهی) بیانگر این واقعیت است که پردازش ابری به یک صنعت بزرگ و حیاتی بدل شده است. با این حال، تمام سرویسهای ابری برای پیادهسازی به مراکز داده (دیتاسنتر) نیازمند هستند که این خود عامل بزرگ مصرف انرژی به شمار میرود. نکته جالب توجه اینکه در حال حاضر، حداقل 7درصد تولید الکتریسیته جهان در مراکز داده به مصرف میرسد. انتظار میرود با رونق یافتن هر چه بیشتر صنعت پردازش ابری در سالهای آینده، سهم مراکز داده از تولید الکتریسیته جهانی از میزان فعلی نیز فراتر رود.
آغاز ماجرا
در ماه ژانویه سالجاری میلادی، یعنی حدود شش ماه قبل، پژوهشگران کمپانی IBM مقالهای را در کنفرانس HiPEAC در منچستر منتشر کردند که یافتههای آنان را درخصوص معماری کامپیوتر تقسیمبندی شده شرح داده است. این پژوهش بخشی از پروژه dReDBox است که توسط اتحادیه اروپا تامین مالی شده است. پروژه dReDBox که نام آن کوتاه شده یک عبارت انگلیسی به معنای «مرکز داده تقسیمبندی در یک باکس» است، خود بخشی از برنامهای با عنوان چشمانداز 2020 است که با یک بودجه 80 میلیارد یورویی، در تلاش است اتحادیه اروپا را در پژوهش و نوآوری پیشرو کند.
تقسیمبندی سرور به معنای آن است که سرورها به اجزای پردازشی و حافظه کاری تقسیم شوند که این اجزا بر حسب نیاز به هر ورکلود (workload) تخصیص داده میشوند. در حال حاضر، سرورها واحد سازنده مراکز داده هستند و هیچ ورکلودی نمیتواند منابعی بیشتر از آنچه را که به یک سرور اختصاص دادهشده، استفاده کند. (مگر اینکه یک سرور جدید به آن داده شود.) همچنین سرورها بهسادگی نمیتوانند منابعشان را با یکدیگر به اشتراک بگذارند. به گفته دکتر آندرا ریِل، پژوهشگر کمپانی IBM، «برنامههایی که در مراکز داده تعبیه میشوند، معمولاً یک عدم تناسب بزرگ در میزان استفاده از منابع دارند. برخی برنامهها نیاز فراوانی به پردازنده و درعینحال نیاز کمی به حافظه دارند، و از سوی دیگر برخی برنامهها حافظهای به میزان چهار برابر بیشتر از پردازنده مصرف میکنند.»
اگر این موضوع که تخصیص منابع در مقیاس سرور انجام میشود و عدم تناسب برنامهها در مصرف منابع را کنار هم قرار دهیم، نتیجهاش این میشود که بسیاری از سرورها پردازنده یا حافظه بلااستفاده خواهند داشت و این به معنای هدررفتن منابع است. آمار و ارقام نشان میدهد، 16درصد از توان پردازشی و 30درصد از حافظه به اینصورت هدر میرود. لازم به ذکر است، وقتی یک سرور روشن میشود، همه بخشهای آن برق مصرف میکنند.
اما چه میشد اگر یک مرکز کنترل نرمافزاری داشتیم که به هر سرور همان میزان پردازنده یا حافظه تخصیص دهد که ورکلود مستقر روی آن نیاز دارد؟ و این آغاز ماجرای تقسیمبندی سرورها است.
مطلب پیشنهادی

تقسیمبندی پردازش و حافظه
پروژه dReDBox در تلاش است ماژولهای پردازنده و حافظه موسوم به Brick را در معماری سرورها استفاده کند. Brick در لغت به معنای آجر است که در این پروژه نیز ماژولهای پردازنده و حافظه همانند آجرهای ساختمان مرکز داده هستند. بریکها با لینکهای پرسرعت به یکدیگر متصل میشوند؛ بنابراین میتوان هر تعداد بریک پردازنده را به هر تعداد بریک حافظه که مورد نیاز است، متصل کرد. در واقع این رویکرد بهخوبی مفهوم معماری ماژولار را نمایان میکند. با صرفنظر از جزییات پیادهسازی، با این رویکرد میتوان به هر ورکلود به میزانی که توان پردازشی و حافظه نیاز دارد، بریک اختصاص داد و بنابراین هدر رفت منابع به صفر میرسد. همچنین در صورت پایان کار ورکلود، منابع آزاد شده و برای سایر ورکلودها قابل تخصیص میشود.
البته دو نوع بریک دیگر نیز در این سیستم تعبیهشده است: بریکهای شتابدهنده که از نوع GPU یا FPGA هستند و برای برنامههای از نوع یادگیری ماشین که مقدار زیادی پردازش موازی دارند، سرعت کار را افزایش میدهند. بریک آخر نیز کنترلر است که همه بریکهای دیگر را کنترل میکند. معماری dReDBox در شکل(1) نمایش دادهشده است. در این شکل، بلوکهای A، B، C، D و E به ترتیب بریک پردازنده، حافظه، شتابدهنده، کنترلر داخلی و کنترلر خارجی هستند.
یک مزیت معماری ماژولار، امکان ارتقای آسان است. اپراتور بهسادگی میتواند بریکهای پردازشی موجود را با نمونه بهتر جایگزین کند یا اینکه بریکهای حافظه موجود را با بریک با حجم بیشتر جایگزین کند. در اینصورت دیگر نیازی به دور انداختن یک سرور نیست. یک جزء کلیدی در این معماری فناوری ارتباطی بین بریکها است. بدیهی است اگر ارتباط مناسب بین بریکها برقرار نشود، کارایی مجموعه کاهش مییابد و اهداف پروژه تامین نخواهد شد؛ بنابراین طراحی لینکهای پرسرعت و با تاخیر کم مورد توجه بوده که در بخش بعدی نحوه دستیابی به آن بررسی خواهد شد.
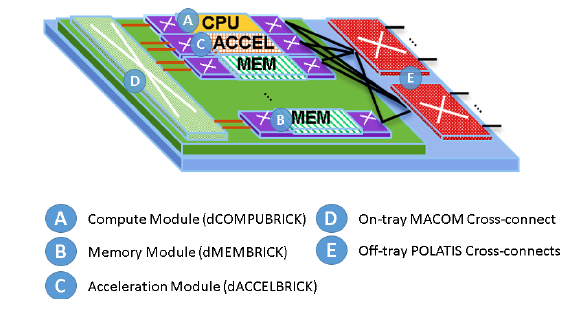
شکل 1
معماری با تاخیر کم
در طراحی و ساخت نمونه اولیه، طراحان پروژه یک ماتریس سوییچ الکتریکی در نظر گرفتهاند که ارتباط میان بریکهای درون یک طبقه (tray) از رک را برقرار میکند. یک ماتریس سوییچ نوری نیز برای ارتباط بین بریکهای دو طبقه مختلف تعبیهشده است. بر خلاف عرف معمول، این سوییچها بهصورت راهیابی مداری (circuit switched) کار میکنند، به این معنا که پس از پیکربندی، یک ارتباط اختصاصی بین دو بریک برقرار میشود. یادآوری میشود در یک شبکه راهیابی بستهای مثل اترنت، مسیر مجزایی برای هیچ جریانی وجود ندارد و آدرس بستهها ملاک قرار میگیرد. در نقطه مقابل، شبکه تلفن ثابت یک نمونه از شبکههای راهیابی مداری است که در آن یک ارتباط اختصاصی بین دو طرف تماس برقرار میشود. به همین دلیل کیفیت ارتباط تلفنی تنها در صورت خرابی تجهیزات شبکه دچار افت میشود.

به گفته دکتر ریل، نگرش راهیابی مداری با هدف ایجاد معماری با تاخیر کم همخوانی دارد: «راهیابی مداری در مقایسه با راهیابی بستهای این امکان را میدهد که با تاخیر بسیار کمتری درخواستهای دسترسی به حافظه را از بریکهای پردازنده به بریکهای حافظه برقرار کنید.» در همین راستا، دکتر ریل ادعا میکند، با یک سختافزار سطح پژوهشی (که هنوز بهینه نشده است) توانستهاند تاخیر انتها به انتهای زیر یک میکروثانیه را برای دسترسی به حافظه ریموت فراهم کنند. با یک پردازنده عملیاتی که با حداکثر سرعت کلاک کار میکند، تاخیرهای کمتر نیز امکانپذیر است. یک مزیت دیگر راهیابی مداری این است که شرایط برای نرمافزار همانند یک سرور عادی به نظر میرسد، که در آن CPU مستقیم به حافظه متصل است. دکتر ریل در همین رابطه میگوید: «ما از برخی افزونههای موجود سیستمعامل مانند پشتیبانی NUMA در لینوکس به منظور دسترسی غیریکسان به حافظه استفاده میکنیم تا برای برنامههایی که از تاخیر در دسترسی به حافظه آگاهی دارند، مقدار آن را تعیین کنیم. اما بقیه برنامهها که چنین آگاهی را ندارند، میتوانند فرض کنند که حافظه محلی است و نیازی به دانستن فاصله حافظه ندارند.»
با تفاسیر فوق، به نظر میرسد انتخاب راهیابی مداری برای این سیستم یک انتخاب هوشمندانه بوده است، با این حال باید در عمل کارایی را بررسی کرد. در بخش بعدی به نحوه ارزیابی سیستم dRedBox میپردازیم.
ارزیابی dRedBox در عمل
برای ارزیابی عملکرد سیستم در عمل، یک نمونه اولیه با بهرهگیری از سیستمرویچیپ (SoC) Xilinx Zynq Ultrascale+ مبتنی بر ARM ساختهشده است. بریکهای پردازنده، حافظه ناچیزی دارند اما بریکهای حافظه مقدار زیادی حافظه DDR4 دارند که به بریکهای پردازنده سرویس میدهند. شکل 2-سمت چپ یک بریک را نشان میدهد که روی یک طبقه (tray) از سیستم (شکل 2- سمت راست) قرار میگیرد. بریک نشان دادهشده در این شکل بر اساس معماری که در شکل(1) به تصویر کشیده شده، ساختهشده است.
نمونه اولیه در مقیاس کوچکی ساختهشده و تنها سهطبقه دارد. بااینحال، تیم dRedBox توانسته یک سری ورکلود واقعی پردازش ابری را روی همین نمونه کوچک اجرا کند و خروجی بگیرد. به گفته آنها، این سیستم میتواند از لحاظ کارایی با یک سرور معمول مطابقت کند، درحالیکه بین 25 تا 50 درصد منابع کمتری مصرف کند. آنها امیدوارند در انتهای پروژه بهجایی برسند که بتوانند عملکرد یک رک کامل را تست کنند. مسئله دیگر در ایجاد یک سیستم عملیاتی، سازگاری آن با زیرساخت موجود است. بنابراین، لایه کنترلی باید اینترفیسهای مناسبی داشته باشد. در این پروژه لایه کنترلی بهصورت یک سرور خارجی پیادهسازی شده و با REST API قابل مدیریت است. این اینترفیس میتواند بهصورت دستی یا بهصورت یکپارچه با نرمافزارهای سطح انتزاع بالا همچون اپناستک برای کار با ماشینهای مجازی یا کوبرنت برای کار با کانتینرها مورد استفاده قرار گیرد.

شکل 2
HPE و اینتل نیز وارد بازی شدهاند
تیم dRedBox تنها گروهی نیست که به تقسیمبندی سرورها برای افزایش کارایی روی آورده است. یک نمونه دیگر پروژه The Machine از کمپانی HPE است که با هدف ایجاد یک سیستم که بتواند یک فضای حافظه بسیار بزرگ را فراهم کند، ایجاد شد. فضای بزرگ حافظه برای اجرای برنامههای دادهکاوی ضروری است. این سیستم از بلوکهای پردازنده و حافظه مجزا بهره میبرد که در یکسری کلاستر جای گرفتهاند. ارتباط بین کلاسترها نیز از طریق یک فابریک حافظه برقرار میشود. در نمونه نمایشی که سال گذشته عرضه شد، HPE از لینکهای فیبر نوری برای اتصال 40 گره به یکدیگر با 160 ترابایت حافظه مشترک استفاده کرد. در همین زمان، شرکت اینتل پروژه خود موسوم به RSD (سرنام Rack Scale Design) را راهاندازی کرد که اهداف مشترکی با سایرین داشت. البته تمرکز اینتل روی جداسازی فضای ذخیرهسازی و سرورها بود، درحالیکه پروژههای IBM و HPE چنانچه ذکر شد، بر جداسازی پردازنده و حافظه کاری تمرکز کرده است. اینتل API مدیریتی خود را با نام Redfish طراحی کرده که عمدتا برای شناسایی منابع کاربرد دارد.

سخن آخر
با وجود تلاشهای فراوان چندین شرکت سازنده سختافزار در جهت ارائه یک معماری نوین برای مراکز داده موسوم به فناوری سرور تقسیمبندیشده، ورود این فناوری به بازار چشمانداز روشنی ندارد. بههرحال شرکتها در پذیرش یک فناوری جدید و متفاوت ازآنچه که در بازار عرضه میشود، محافظهکارانه رفتار میکنند. بهخصوص در بازار پردازش ابری که هزینه ریسک آن بسیار بالا است. شاید اگر شرکتهایی چون گوگل، آمازون یا فیسبوک که از مصرفکنندگان بزرگ بازار به شمار میروند، تمایلی به این فناوری جدید نشان دهند، میتوانیم انتظار ورود آن را به بازار داشته باشیم.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.























نظر شما چیست؟