







میکروسرویس، همانگونه که از نام آن مشخص است، اساسا به سرویسهای نرمافزاری مستقلی گفته میشود که کارکردهای تجاری خاصی را برای یک اپلیکیشن نرمافزاری تعریف میکنند. این سرویسها میتوانند به صورت مستقل از هم نگهداری و توزیع شوند. معماری میکروسرویسها بهطور طبیعی در سازمانهای بزرگی استفاده میشود که در آنها تیمهای توسعه مستقل از هم برای ارائه یک کارکرد تجاری کار میکنند یا اپلیکیشنها قرار است خدمات خاصی در اختیار یک حوزه تجاری قرار دهند. فرض کنید در حال توسعه یک سیستم پیچیده و سمت سرور هستید، در معماری سنتی تک لایه (Monolithic) کل سیستم به صورت یک نرمافزار یکپارچه پیادهسازی میشود. در حالی که در معماری میکروسرویس سیستم متشکل از یک هسته اصلی و تعدادی ماژول (سرویس) کوچک است که هر کدام از این مولفهها بهصورت کاملا مستقل توانایی استقرار دارند. هر یک از این سرویسها میتوانند توسط تیمهای جداگانهای با پلتفرم توسعه و زبان برنامهنویسی و بانک اطلاعاتی جداگانهای توسعه داده شوند. در چنین سیستمی تیمهای مهندسی باید منحصرا روی حوزههای تجاری خود تمرکز کنند و واحدهای تجاری باید تنها به سایر قسمتهای موجود در همان حوزه متصل شوند. با اینحال ترسیم این حد و مرزها کار چندان سادهای نیست. به همین دلیل الگوهایی برای این معماری تعریف شده است. بهطور مثال، Bounded Context یکی از این الگوها است که ما را در سازماندهی تیمهای مهندسی و حوزههای تجاری در سطح بالا کمک میکند.
همچنین الگوی دیگری بهنام تجمیع (Aggregate) وجود دارد که به ما کمک میکند تا دادههای خود را در سطح پایینتری سازماندهی کنیم. هنگام شکستن عملکرد تجاری به چندین کد منطقی کوچکتر، نیاز است در مورد نحوه همکاری دادههای برگشتی توسط هر سرویس فکر کنیم. این مسئولیت را نمیتوان بر عهده مصرف کننده گذاشت. الگوی تجمیع برای غلبه بر این مشکلات استفاده میشود.
تجمیع
تجمیع (Aggregate) یک الگوی طراحی است که توسط اریک ایوانز در کتابش تحت عنوان Domain-Driven Design معرفی شد. اگر چه این کتاب در اصل برای توضیح معماری میکروسرویسها یا سیستمهای توزیعی نوشته نشده، اما میتوان از آن به عنوان راهنمایی درباره این موضوعات کمک گرفت. یک تجمیع گروهی از بخشهای خودمختار را تعریف میکند که به عنوان یک واحد کوچک مستقل رفتار میکنند. هر نوع تغییر در هر کدام از این بخشها به عنوان یک تغییر در کل الگوی تجمیع در نظر گرفته میشود. هر الگوی تجمیع از بخشهای زیر تشکیل میشود:
- مرز یا کرانه (A boundary). برای متمایز کردن بخشهایی که متعلق به یک الگوی تجمیع هستند و بخشهایی که مستقل از آن هستند استفاده میشود.
- تعدادی موجودیت (A number of entities). این موجودیتها اشیا تجاری در یک گروه هستند.
- یک ریشه (A root). هر تجمیع یکی از موجودیتهای خود را در تعامل با دنیای خارج (مصرفکننده) قرار میدهد. اشیا خارج از تجمیع تنها میتوانند به ریشه تجمیع ارجاع داده شوند و نمیتوانند مستقیما به هیچ موجودیت دیگری درون تجمیع مراجعه کنند.
شکل 1 مولفههای یک الگوی تجمیع را نشان میدهد. خط ضخیم بیضی شکل مرز پیرامون تجمیع را نشان میدهد که مولفهها درون آن قرار دارند. همانگونه که در شکل مشاهده میکنید ریشه با تمامی موجودیتهای درون الگو در ارتباط است. ریشه تنها مولفهای است که امکان دسترسی به آن خارج از الگو فراهم است. به این ترتیب، تنها ریشه میتواند دسترسی به سایر بخشهای درون الگو را امکانپذیر کند.
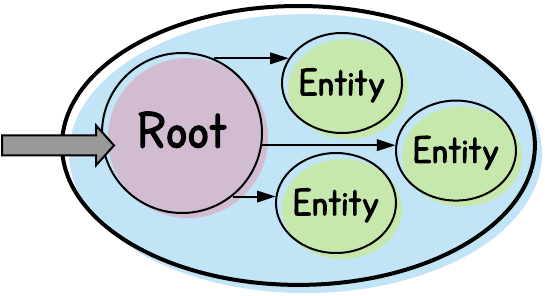
ریشههای تجمیع
به نوعی اینگونه میتوان گفت که ریشهها پل ارتباطی الگوی تجمیع با دنیای خارج از آن هستند. بنابراین برای تشخیص اینکه کدام قسمت باید ریشه باشد ما باید واجد شرایطترین گزینه را انتخاب کنیم. خوشبختانه این انتخاب معمولا مشخص است. خیلی از الگوهای تجمیع یک موجودیت اصلی دارند که بخشهای دیگر به آن وصل میشوند. اجازه دهید نمودار شکل 1 را کمی ساده و اصلاح شدهتر بررسی کنیم. : مثال ما یک تجمیع کاربری (User Aggregate) است (شکل 2).

همانگونه که مشاهده میکنید تجمیع ما و موجودیت ریشه هر دو User نامگذاری شدهاند. موجودیتUser احتمالا شامل مشخصههایی از قبیل نام و نام خانوادگی، جنسيت و تاریخ تولد و سایر فیلدهای قابل سنجش است. سایر موجودیتهایی که در اینجا شرح داده شدهاند، نمایانگر ارتباطات یک-به-چند بین یک User و اطلاعات تماسش ایمیل (آدرس)، Phone (عدد) و Address (پستی) است. علاوه بر تصویر سادهای که ترسیم کردیم، ممکن است موجودیتهای دیگری نیز در تجمیع ما وجود داشته باشد (بهطور مثال، موجودیتهایی که برتری یک کاربر را نشان میدهند). در مثال فوق شناسایی و تشخیص موجودیت User که ریشه تجمیع است واضح است. در این مثال موجودیت User شامل اطلاعات اصلی در مورد کاربران است. علاوه بر این، User موجودیتی است که سایر موجودیتهای تجمیع در تعامل با آن هستند. بهطور مثال، اگر یک Phone حذف شود، تجمیع بدون مشکل حضور خواهد داشت. User تنها موجودیتی در تجمیع است که مستقیما از خارج قابل آدرسدهی است. ما میتوانیم با استفاده از ReST یک مسیر شبیه به کد زیر ایجاد کنیم:
/users/{user-identifier}
اما انجام اینکار به صورت زیر امکانپذیر نیست.
/users/phones/{phone-identifier}
سایر تجمیعها میتوانند ارجاعات به موجودیت User را ذخيره کنند. بهطور مثال، یک تجمیع بهنام Order میتواند شناسه User که هر Order را آغاز کرده ذخيره کند. به همین دلیل به هر User باید یک شناسه عمومی یا سراسری منحصر به فرد اختصاص داده شود.
اشیا مقداری
در مقابل، سایر موجودیتها تنها به شناسههای محلی نیاز دارند، یعنی شناسههایی که یک تجمیع توسط آن میتواند موجودیتهای خود را تفکیک کند. بهطور مثال، یک Phone مربوط به User میتواند به عنوان 1, 2 و 3 شناسایی شود، به این دلیل که Phone خارج از خود تجمیع معنایی ندارد. هیچ تجمیع دیگری برای Phone 2 درخواست ارسال نمیکند، اما ممکن است Phone 2 از موجودیت User به صورت b4664e12–2b5b-47c8-b349–41e81848758f بازیابی شود. با این حال حتا همین فراخوانی ساده نیز باید در یک محدوده کوچک انجام شود. سایر تجمیعها هرگز نباید دائما به شماره تلفن کاربر مراجعه کنند. با برگشت به مثال ReST، ما میتوانیم ارجاع به یک شماره تلفن را به صورت زیر انجام دهیم:
/users/{user-identifier}/phones/{phone-identifier}
با اینحال، خیلی از این موجودیتهای پشتیبان اشیا مقداری هستند، یعنی اشیایی که هویتشان به جای آنکه منطبق با ارجاع مشخص شود، بر مبنای مقدار آنها مشخص میشود. Email را در نظر بگیرید. ممکن است ما تصمیم بگیریم برای هر آدرس ایمیل یک شناسه عددی در نظر بگیریم، اما در عمل خود me@myaddress.com میتواند به عنوان شناسه این موجودیت در نظر گرفته شود. اگر این رشته تغییر کند، آنگاه به یک آدرس ایمیل کاملا جدید تبدیل میشود. همین موضوع در مورد Phone نیز صادق است که از ارقام بدون فرمت تشکیل شده و هویت شماره تلفن را شکل میدهد. یک بار دیگر به مثال ReST خود بازمیگردیم. ما میتوانیم برای موجودیتهای اطلاعات تماس خود تمامی شناسهها را کنار بگذاریم و تنها به عنوان یک گروه به آنها دسترسی داشته باشیم. چیزی شبیه به دستور زیر.
/users/{user-identifier}/phones
توجه داشته باشید که هیچ پاسخ کلی در اینجا وجود ندارد. همه چیز به این موضوع بستگی دارد که ما قصد داریم چگونه با موجودیتها رفتار کنیم.
چگونه تجمیعها را تعریف کنیم
تعریف درست و مناسب تجمیعها کمک میکند با مدلهای داده سنتی که در آن مرزهای بین موجودیتهای اصلی و غیر اصلی به درستی مشخص نبود خداحافظی کرده و موجودیتهایی که نیازمند تغییر هستند را در یک گروه قرار دهیم. برای تعریف تجمیعها چند رویکرد وجود دارد، با اینحال تمامی آنها در یکسری فرآیندهای پایه یکسان هستند:
کار را با شناسایی موجودیتهای اصلی سیستم آغاز کنید
آغاز کار به ترکیبی از دانش تجاری و عقل سلیم نیاز دارد. ما کار را با شناسایی موجودیتهای سطح بالا که بخشهای اساسی حوزه تجاری ما هستند شروع میکنیم. شاید برایتان عجیب باشد، اما در سیستم ما شماره تلفنها موجودیتهای اساسی نیستند، اما کاربران (یا هر چیزی که سازمان ما آنها را نامگذاری کرده) موجودیت مهم و اساسی هستند. مثالهای دیگر در این زمینه شامل موارد زیر هستند:
- سفارشات
- محصولات (به احتمال زیاد سازمان ما موجودیتهایی را تعریف خواهد کرد که بیانگر محصولی است که ما ارائه میکنیم. بهطور مثال، اتومبیل، کتاب، آلبوم موسیقی و غیره)
- دفتر کل
- فهرست کالاها
اگر در تشخیص این موضوع که آیا یک موجودیت به اندازه کافی سطح بالا است که به عنوان یک تجمیع ارائه شود دچار تردید هستید، از خودتان بپرسید آیا این موجودیت یک هویت سراسری را تشریح میکند یا خیر. بعد از این که موجودیتهای کلیدی سیستم را شناسایی کردیم، باید نامزدهای احتمالی برای موجودیت ریشه تجمیع و سایر موجودیتهایی که به میزان زیادی با موجودیت ریشه در ارتباط هستند را پیدا کنیم. برای انجام این کار باید به نکات زیر دقت کنید:
بدون قسمت ریشه سایر قسمتها عموما آبجکتهایی خواهند بود که معنایی ندارند.
- همانگونه که در حال شناسایی موجودیتهای متعلق به یک تجمیع هستیم، باید به دنبال عناصر ثابت (قواعدی که بر تعامل بین موجودیتهای مختلف کنترل و نظارت میکند) باشیم. باید تلاش کنیم تمامی موجودیتها با یک عنصر ثابت در تجمیع یکسان در تعامل باشند.
- بعضی تجمیعها ممکن است واضح به نظر برسند و بهطور طبیعی شکل بگیرند (بهطور مثال، User معمولا در این دسته قرار میگیرد)، در حالی که در مورد برخی دیگر ممکن است کار به همین سادگی نباشد. اجازه دهید برای مثال دو نمونه سفارشات (Orders) و موارد سفارش (Order Items) را در نظر بگیریم. سفارشات نشانگر مجموع خریدی است که یک مشتری به صورت آنلاین انجام داده است. یک سفارش از مواردی سفارش تشکیل شده که هر کدام نشانگر یک محصول مشخص است که به عنوان بخشی از سفارش در نظر گرفته میشود. بدون شک باید سفارشات را به عنوان تجمیع در نظر بگیریم. همچنین باید هر سفارش ثبت شده را ردیابی کرده و از آن کوئری بگیریم تا بتوانيم مولفههای آنرا بررسی کنیم. تکلیف موارد سفارش (Order Items) چه میشود؟ آیا باید یک Order Item را هم به عنوان تجمیع در نظر بگیریم؟ بسته به نوع طراحی یک Order Item ممکن است شامل تعدادی از موجودیتها باشد که در یک گروه قرار گرفتهاند. متقابلا، یک سفارش (Order) ممکن است عناصر ثابتی داشته باشد که مرتبط با موارد سفارش هستند. شاید لازم باشد هر بار که یک مورد سفارش اضافه میشود قیمت کل یک سفارش نیز مجدد محاسبه شود یا ممکن است محدودیتی برای تعداد یا نوع کالاهای خریداری شده اعمال شود. در چنین شرایطی سفارش باید یک تجمیع باشد که موارد سفارش را در بر میگیرد.
هیچ دستورالعمل جادویی برای تعریف تجمیعها وجود ندارد. تعریف این تجمیعها نوع کسبوکار بستگی دارد. اغلب قبل از این که تجمیعهای ریشته را شناسایی کنیم، موارد مختلف را بررسی کرده و پس از ارزیابی دقیق تجمیعها را تعریف میکنیم. در این مطلب سعی کردیم بهطور اجمالی خوانندگان را با مفهوم لزوم بهکارگیری الگوی تجمیع در معماری مایکروسرویس آشنا کنیم. برای اطلاع بیشتر در این زمینه به آدرس
https://medium.com/better-programming/why-your-microservices-architecture-needs-aggregates-342b16dd9b6d
مراجعه کنید.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.
مطالب مرتبط






















نظر شما چیست؟