



یادگیری تقویتی چیست؟
یادگیری ماشین، به علم طراحی ماشینهایی اشاره دارد که از طریق دادهها یا نمونه دادههایی که به آنها تحویل داده میشود و بر مبنای تجربیات قبلی، بدون آنکه همه اقدامات از طریق برنامهنویسی صریح به آنها آموزش داده شود قادر به انجام خودکار وظایف محوله هستند. الگوریتمهای یادگیری ماشین به سه گروه اصلی با ناظر، بدون ناظر و تقویتی تقسیم میشوند.
یادگیری تقویتی، علم تصمیمگیری است و به نوع خاصی از فرآیند یادگیری بهینه در یک محیط با هدف بهدست آوردن حداکثر پاداش اشاره دارد. این رفتار بهینه مبتنی بر تعامل با محیط و مشاهدات محیطی است، شبیه به کودکانی که در حال کاوش در جهان اطراف خود و یادگیری کارهایی هستند که به آنها در رسیدن به هدفشان کمک میکند.
در غیاب سرپرست، یادگیرنده (مدل) باید بهطور مستقل بهدنبال کشف اقداماتی باشد تا بتواند حداکثر پاداش را دریافت کند. این فرآیند کشف، رویکردی شبیه به آزمون و خطا دارد. نوع دریافت پاداش به کیفیت اقدامات انجامشده بستگی دارد که ممکن است بهشکل آنی پرداخت شود یا با تاخیر همراه شود که نشان میدهد مدل باید تلاش بیشتری برای بهبود کیفیت کارهای خود کند. از آنجایی که مدلهای مبتنی بر یادگیری تقویتی میتوانند بدون وجود سرپرست یا ناظر کارهایی انجام دهند که بهشکل عادی قابل رویت نباشند، یادگیری تقویتی یک پارادایم بسیار قدرتمند در دنیای هوش مصنوعی است. ریچارد گروس (Richard Gross) در کتاب «روانشناسی: دانش ذهن و رفتار»، یادگیری را فرآیند کسب یا اصلاح دانش، رفتار، مهارت، ارزش یا عملکرد تعریف میکند. بر مبنای تعریف فوق، باید بگوییم یادگیری تقویتی زیرشاخه مهمی از یادگیری ماشین است که در آن یک عامل (Agent) میآموزد چگونه در محیط با انجام اقدامات و دیدن نتایج آنها رفتار کند. بهطور کلی، از یادگیری تقویتی برای حل مسائل مبتنی بر پاداش استفاده میشود. در یادگیری تقویتی، عامل با آزمونوخطا میآموزد و سعی میکند با انجام برخی اقدامات در محیط بیشترین پاداش را کسب کند.
الگوریتمهای مورد استفاده در یادگیری ماشین به سه گروه اصلی یادگیری تحت نظارت، بدون نظارت و تقویتی تقسیم میشوند. یادگیری نظارتی مبتنی بر بازخورد برای نشان دادن درست یا غلط بودن یک پیشبینی است، در حالی که یادگیری بدون نظارت مستلزم عدم پاسخگویی است؛ الگوریتم صرفا سعی میکند دادهها را بر اساس ساختار مستتر در آنها طبقهبندی کند. یادگیری تقویتی شبیه یادگیری تحت نظارت است که بازخورد دریافت میکند، اما این موضوع برای هر ورودی یا حالتی صدق نمیکند. در حالت کلی، مدلهای هوشمند بهگونهای توسعه پیدا میکنند که بهطور خودکار عملکرد یا رفتار خود را بهبود بخشند. در شکل ۱ تفاوت سه مدل یادگیری ماشین و تفاوتهای عملکردی هر مدل را مشاهده میکنید.
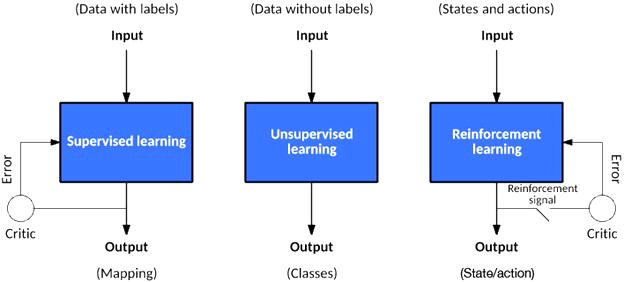
شکل 1
در یادگیری نظارتشده، یک مجموعه داده با برچسبهای مطلوب در اختیار مدل قرار میگیرد؛ به طوریکه یک تابع میتواند میزان خطا در در مورد یک پیشبینی را محاسبه کند. نظارت زمانی اتفاق میافتد که یک پیشبینی انجام شود و یک خطا (واقعی در مقابل مطلوب) برای تغییر عملکرد و یادگیری نگاشت شود.
در یادگیری بدون نظارت، یک مجموعه داده که شامل خروجی مطلوب نیست در اختیار داریم؛ از اینرو، هیچ راهی برای نظارت بر عملکرد وجود ندارد. به همین دلیل، تابع تلاش میکند مجموعه دادهها را به کلاسها تقسیم کند تا هر کلاس شامل بخشی از مجموعه داده با ویژگیهای مشترک باشد.
در یادگیری تقویتی، الگوریتم سعی میکند مجموعه اقدامات قابل انجام روی حالتها/وضعیتها (States) را برای دستیابی به یک حالت هدف بیاموزد. در پارادایم فوق، عامل یادگیری پس از ارزیابی هر اقدام، بازخوردی در قالب پاداش یا جریمه دریافت میکند. بر مبنای این تعریف باید بگوییم یادگیری تقویتی چارچوبی کلی برای یادگیری مسائلی است که نیازمند تصمیمگیریهای متوالی هستند و راهکاری برای پیادهسازی یک چارچوب مبتنی بر ریاضیات برای حل مسائل است. بهطور مثال، برای یافتن یک خطمشی خوب میتوان از روشهای مبتنی بر ارزش مثل یادگیری کیفی استفاده کرد تا هماهنگی یک اقدام با یک وضعیت معین بررسی شود. از طرف دیگر میتوان با اعمال روشهای مبتنی بر خطمشی، بهشکل مستقیم و بدون توجه به میزان هماهنگی اقدام و وضعیت، اعمالی را که میتوان در وضعیتهای مختلف انجام داد شناسایی کرد. نکته مهمی که باید به آن اشاره کنیم این است که روش مبتنی بر پاداش و تنبیه الهامگرفته از رویکردهای آموزشی و ترتیبی انسانی است که در آن بازخورد لزوما برای همه اقدامات ارائه نمیشود و تنها زمانی پاداش داده میشود که ضروری باشد یا کار بزرگی انجام شده باشد.
اکنون بیایید هر مدل را بررسی کنیم و رویکردها و الگوریتمهای کلیدی آنها را بررسی کنیم.
مطلب پیشنهادی
 یادگیری از آفلاین به آنلاین
یادگیری از آفلاین به آنلاین
مطلب پیشنهادی
الگوریتمهای یادگیری تقویتی بر چه مبنایی کار میکنند؟
به احتمال زیاد تجربه انجام بازیهای ویدئویی مثل ندای وظیفه (Call of duty)، بتلفیلد یا نمونههای مشابه را دارید. در زمان انجام بازی، کارهای تکراری را انجام میدهید، بهطور مثال، وضعیت را بررسی میکنید، تصمیمگیری میکنید و کاری را انجام میدهید و در انتها کارهایی که انجام دادهاید را ارزیابی میکنید که آیا تصمیمات درستی اتخاذ کردهاید یا خیر.
این فرآیند تکرارشونده به شما کمک میکند بر مبنای کارهایی که انجام دادهاید، تجربه کسب کنید و متوجه شوید چه اقداماتی را خوب و چه اقداماتی را بد انجام دادهاید. این رویکرد به شما کمک میکند بهتدریج در انجام بازی عملکرد بهتری پیدا کنید. این فرآیند تکرارشونده کارها محدود به انجام بازیهای ویدئویی نیست و ما در بیشتر فعالیتهای روزمره از الگوی یکسانی استفاده میکنیم. این روند درست همان کاری است که در یادگیری تقویتی برای آموزش ماشینها استفاده میشود و عامل (Agent) با آزمونوخطا یاد میگیرد و با انجام دادن برخی اقدامات در محیط اطرافش تلاش میکند به حداکثر پاداش برسد.
فرض کنید فروشگاهی داریم و کارمندی استخدام میکنیم. این کارمند میتواند کارهای مختلفی مثل تماس با مشتریان و افزایش نرخ فروش در مقابل دریافت کمیسیون را انجام دهد. حال تصور کنید این کارمند برای فروشگاه فرضی ما نقش یک عامل (Agent) را دارد. این عامل در شرکت کار میکند؛ با این توصیف، شرکت را باید بهعنوان محیط تصور کنیم.
عامل در یک حالت/وضعیت (State) قرار دارد. هر مرتبه که عملیاتی در محیط انجام میشود، وضعیت عامل تغییر میکند و به وضعیت جدیدی وارد میشود. از اینرو، هر کار انجامشده پاداش یا تنبیهی برای عامل خواهد داشت. بهطور مثال، اگر کارمند مطابق با برنامهریزی، یک روز کاملا موفق در فروش داشته باشد کارمزد دریافت میکند و اگر کارهای اشتباهی انجام دهد و فروش مطابق با انتظار پیش نرود کارمزدی دریافت نمیکند. در مثال مذکور، عامل بهطور مداوم در حال یادگیری است تا بهترین خدمات را ارائه کند. در طول فرایند فوق عامل درباره کارها و اقدامات نکاتی میآموزد که به پاداش منتهی میشوند و رفتهرفته عملکردش بهتر میشود تا به یک هدف نهایی برسد.
اکنون اجازه دهید از مثال فوق در ارتباط با یادگیری تقویتی استفاده کنیم. در یادگیری تقویتی، یک عامل در یک محیط وجود دارد و میتواند کارهایی انجام دهد؛ درست مانند ما انسانها. هر اقدامی که انجام میدهد نتیجهای برای او بههمراه دارد. عامل در تلاش است تا پاداشهای دریافتی خود را بهحداکثر برساند. نتیجه هر اقدام یک پاداش مثبت یا یک پاداش منفی یا همان تنبیه است. به مرور زمان، عامل از این نتایج نکاتی را میآموزد تا کارهای خود را بهشکل مطلوبتری انجام دهد؛ از اینرو، میتوان گفت یادگیری تقویتی یادگیری مبتنی بر بازخورد است. در دنیای هوش مصنوعی عامل هوشمند نهاد خودکاری است که توسط حسگرهای خود اطلاعات محیطی را دریافت میکند و از طریق محرکها اقداماتی انجام میدهد و فعالیتهای خود را در مسیر کسب اهداف هدایت میکند. عاملهای هوشمند از طریق یادگیری یا دانش دریافتی برای دستیابی به اهداف استفاده میکنند. این عاملها ممکن است ساده یا پیچیده باشند. دقت کنید پژوهشگران باید قبل از پیادهسازی عامل یادگیری تقویتی عمیق، درباره موضوعات مهمی مثل رویکردهای مختلف یادگیری تقویتی، ایده پاداش دادن و واژه عمیق در یادگیری تقویتی عمیق اطلاعات کاملی داشته باشند تا بتوانند مدل دقیقی را طراحی کرده و توسعه دهند. مفهوم مهم در پارادایم یادگیری تقویتی این است که عامل در محیط در فرآیند تعامل با آن و دریافت پاداش برای اقدامات خود، فرآیند یادگیری را کامل میکند. ریشه شکلگیری یادگیری تقویتی بر مبنای تعامل بشر با محیط و یادگیری بر اساس تجربیات خود استوار شده است. فرض کنید، هیچ شناختی از شعله آتش ندارید و به آن نزدیک میشوید. شعله آتش گرم است، این امر مثبت تلقی میشود و شما احساس مثبتی پیدا میکنید، اکنون میدانید که آتش چیز مثبتی است. در ادامه سعی میکنید آتش را لمس کنید و دست شما میسوزد. اکنون متوجه شدهاید که آتش چیز مثبتی است، اما زمانی که در فاصله مناسب از آن قرار بگیرید، قادر به دریافت گرمای آن هستید و نزدیک شدن بیشازاندازه به آن باعث سوختن میشود. این روشی است که طی آن، انسانها از طریق تعامل با محیط نکاتی میآموزند. یادگیری تقویتی یک رویکرد پردازشی است که بر اساس آن، عامل با انجام کارها یا به عبارت دقیقتر، اَعمال، میآموزد.
مطلب پیشنهادی
 شغلی تضمین شده و آیندهدار در ابتدای قرن
شغلی تضمین شده و آیندهدار در ابتدای قرن
مطلب پیشنهادی
یادگیری تقویتی و یادگیری ماشین
اگر در نظر داشته باشیم بهشکل دقیقتری در مورد این مبحث صحبت کنیم، باید بگوییم که یادگیری تقویتی یکی از پارادایمهای مهم یادگیری است که در آن یک عامل میآموزد در یک محیط غیرقطعی (Uncertain) و پیچیده به هدف برسد. در یادگیری تقویتی مدلها با شرایطی همانند یک بازی ویدئویی روبهرو میشوند. کامپیوتر برای یافتن راهحلی برای مسئله از روش آزمونوخطا استفاده میکند. برای اینکه ماشین بتواند آنچه برنامهنویس میخواهد انجام دهد، پاداش یا مجازاتی برای اعمال او در نظر گرفته میشود. در این حالت، هدف ماشین بهدستآوردن حداکثر پاداشهای دریافتی است. اگرچه برنامهنویس خطمشیهایی (قواعد و دستورالعملهای بازی) را برای دریافت پاداش مشخص میکند، با اینحال، هیچ پیشنهادی به مدل درباره نحوه انجام بازی ارائه نمیکند. ماشین باید تشخیص دهد به چه ترتیبی از نتایجی که در هر اقدام بهدست میآورد برای دستیابی به هدف نهایی استفاده کند.
عامل، وضعیت و محیط
فرض کنید عاملی در حال یادگیری بازی ویدئویی مثل سوپرماریو از طریق کار روی مثالها است (شکل 2). مراحلی که یک مدل مبتنی بر یادگیری تقویتی باید پشت سر بگذارد تا در انجام این بازی به مهارت دست پیدا کند بهشرح زیر است:
- عامل، حالت S0 را از محیط دریافت میکند (در مثال مذکور، اولین فریم (حالت) از بازی سوپر ماریو (محیط) دریافت میشود).
- بر مبنای حالت S0، عامل عمل A0 را انجام میدهد که برابر با حرکت به سمت راست است.
- محیط به فریم یا همان حالت جدید S1 انتقال پیدا میکند.
- محیط پاداش R1 را به عامل میدهد.

شکل 2
این حلقه یادگیری تقویتی مبتنی بر یک فرآیند تکرارشونده از حالت، عمل و پاداش است. هدف عامل این است که پاداش تجمیعی مورد انتظار را به بالاترین حالت ممکن برساند.

فرضیه پاداش چیست؟
چرا هدف عامل بهحداکثررساندن پاداش تجمیعی است؟ به این دلیل که یادگیری تقویتی بر مبنای این تئوری توسعه پیدا کرده است. به همین دلیل است که در یادگیری تقویتی برای دستیابی به بهترین رفتار، باید پاداش تجمیعی حداکثری در نظر گرفته شود. پاداش تجمیعی در هر گام t را میتوان بر مبنای فرمول زیر نوشت:
Gt= Rt+1 + Rt+2 + …..
که برابر است با:

نکته ظریفی که باید در خصوص پاداشدهی به آن دقت کنید این است که فرآیند فوق بر مبنای محاسبات دنیای آمار است. پاداشی که زودتر داده شود (در ابتدای بازی)، احتمال وقوع آن بیشتر است؛ زیرا از پاداشهای بلندمدت آینده قابل پیشبینیتر هستند. برای درک بهتر جمله فوق به مثال زیر دقت کنید:
مثالی مفروض است که در آن عامل یک موش کوچک و رقیب آن گربه باشد. هدف این است که بیشترین میزان پنیر توسط موش خورده شود، قبل از آنکه گربه بتواند موش را بخورد. همانگونه که در شکل 3 مشخص است، احتمال خوردن پنیرهای نزدیک موش نسبت به پنیرهای نزدیک گربه بیشتر است (هرچه به گربه نزدیکتر شود، خطر آن نیز بیشتر است).

شکل 3
در یک توالی، پاداش نزدیک گربه حتا اگر بهلحاظ کمیت بزرگتر باشد (پنیرهای بیشتر)، بازهم تنزیل پیدا میکند؛ زیرا دستیابی به آنها سخت است و عامل مطمئن نیست قادر به خوردن آنها باشد. برای تنزیل پاداشها به روش زیر عمل میکنیم:
- یک نرخ تنزیل با عنوان گاما تعریف میکنیم که در بازه 0 و 1 قرار دارد. هر چه گاما بزرگتر شود، تنزیل کمتر است. در نتیجه، عامل یادگیرنده به پاداشهای بلندمدت اهمیت بیشتری میدهد. در نقطه مقابل، هرچه گاما کوچکتر باشد، تنزیل بیشتر است؛ به این معنا که عامل دقت بیشتری به پاداشهای کوتاهمدت میکند. پاداش مورد انتظار تجمیعی تنزیلدادهشده بر مبنای فرمول زیر محاسبه میشود.

- برای سادگی، هر پاداش با گاما به توان گام زمانی، تنزیل داده میشود. با افزایش گام زمانی، گربه به موش نزدیکتر میشود، از اینرو، احتمال وقوع پاداشهای بعدی کم و کمتر میشود.
وظایف اپیزودیک یا استمرار (Episodic or Continuing tasks)
یک وظیفه، نمونهای از مسئله یادگیری تقویتی است. در یادگیری تقویتی دو نوع وظایف اپیزودیک و استمرار وجود دارد. در اینجا، اپیزود شامل یا متشکل از یک سری قطعات یا رویدادهایی است که بهطور ضعیف بههم متصل هستند.
در رویکرد وظایف اپیزودیک (Episodic tasks)، یک نقطه ابتدایی و انتهایی وجود دارد که باعث ساخت یک اپیزود یعنی فهرست حالتها، اعمال، پاداشها و حالتهای جدید میشود. بهطور مثال، در مثال ما (بازی سوپرماریو)، یک اپیزود با وارد شدن یک ماریو جدید آغاز میشود و هنگامی که ماریو کشته یا به پایان مرحله میرسد، کار تمام شده است.
در رویکرد وظایف مستمر، چنین وظایفی برای همیشه ادامه پیدا میکنند. در این شرایط، عامل باید یاد بگیرد که چگونه بهترین عمل را انتخاب کند و بهطور همزمان با محیط تعامل داشته باشد. یک مثال قابل ملموس در ارتباط با وظایف مستمر، عاملی است که وظیفه نظارت مستمر بر تغییرات سهام را دارد. برای این وظیفه، هیچ نقطه آغاز و پایانی وجود ندارد. عامل همواره به کار ادامه میدهد تا کارشناس تصمیم به متوقف کردن آن بگیرد.
اصطلاحات کاربردی یادگیری تقویتی
اگر علاقهمند هستید روی پارادایم یادگیری تقویتی تمرکز کنید، بهتر است با برخی از اصطلاحات مهم در این زمینه آشنا باشید. با توجه به اینکه تعداد اصطلاحات زیاد است، در ادامه به چند مورد مهم اشاره میکنیم:
- عامل (Agent): الگوریتم یا مدلی است که باید کارهایی را انجام دهد و با گذشت زمان از آنها بیاموزد.
- محیط (Environment): این واژه همانگونه که از نامش بر میآید، محیطی است که عامل با آن ارتباط برقرار میکند و کارهایی در آن محیط انجام میدهد.
- اقدام (Action): کاری است که عامل انجام میدهد. کنشها و واکنشهای عامل در یک محیط هستند.
- پاداش (Reward): نتیجه یک عمل است. هر عملی پاداشی دارد. پاداش میتواند مثبت یا منفی باشد.
- وضعیت (State): شرایط فعلی عامل در محیط را نشان میدهد. اعمالی که عامل انجام میدهد میتواند وضعیت آنرا تغییر دهد، مثل بازی سوپرماریو که به آن اشاره کردیم.
- خطمشی(Policy): استراتژی یا رفتاری است که کارها بر مبنای آن انجام میشود و عامل برای دستیابی به نتیجه موردنیاز باید انجام دهد.
- تابع ارزشی (Value Function): این تابع عامل را از حداکثر پاداشی که برای هر یک از وضعیتها در آینده دریافت میکند، مطلع میکند.
کلام آخر
یادگیری تقویتی بدون شک پیشرفتهترین پارادایم یادگیری ماشین و هوش مصنوعی است که ظرفیتهای زیادی برای تحولآفرینی در دنیای فناوری اطلاعات دارد. آمارها نشان میدهند، یادگیری تقویتی کارآمدترین راهکار برای القای مفهوم خلاقیت به ماشینها است، زیرا جستوجوی راههای جدید و نوآورانه برای انجام وظایف، نوعی خلاقیت است؛ از اینرو، باید بگوییم یادگیری تقویتی ممکن است فرآیند بعدی در توسعه هوش مصنوعی باشد.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.
مطالب مرتبط






















نظر شما چیست؟