


در بخش اول مقاله «چگونه میتوانیم در عمل از یادگیری ماشین استفاده کنیم؟» دیدید که در ابتدا یکسری دادهها را جمعآوری کردیم، دادههای بهدستآمده را در سه مرحله مقدماتی و ساده به الگوریتم ژنریک خود تحویل دادیم و در نهایت تابعی ایجاد کردیم که قادر بود پیشبینی قیمت همه خانههای موجود در یک منطقه را ارائه کند. اما سه مرحله این الگوریتم را به شرح زیر پیادهسازی میکنیم:
مرحله اول
در این مرحله همه وزنها را برابر با مقدار یک تعیین میکنیم.
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# a little pinch of this
price += num_of_bedrooms * 1.0
# and a big pinch of that
price += sqft * 1.0
# maybe a handful of this
price += neighborhood * 1.0
# and finally, just a little extra salt for good measure
price += 1.0
return price
مرحله دوم
در این مرحله دادههای مربوط به خانههای به فروش رفته را در اختیار تابع قرار میدهیم و پیشبینی انجام شده را با قیمت واقعی خانهها ارزیابی میکنیم تا از صحت درستی تابع و انحراف معیار تابع و قیمتی که بهعنوان پیشبینی ارائه کرده، اطلاع پیدا کنیم. برای مثال، اگر قیمت یکخانه برابر 250 هزار دلار است، اما مدل قیمت آن را 178 هزار دلار برآورد کرده، شما در اینجا خطایی به میزان 72 هزار دلار دارید. اکنون باید مربع انحراف را برای همه خانههای مجموعه آموزشی جمع کنید. (به عبارت سادهتر باید میزان خطای به وجود آمده را برای هر خانهای که در مجموعه دادهای وجود دارد به توان 2 رسانده و مقادیر را با یکدیگر جمع کنید.) اگر 500 خانه در مجموعه دادهای شما وجود دارد، در این حالت مربع خطا برای همه خانهها برابر با 86,123,373 دلار خواهد بود. این مقدار بیانگر کارکرد اشتباه تابع شما در این الگوریتم است. (شکل 1)
حالا باید مجموع بهدستآمده را بر 500 تقسیم کنید تا میانگین مربعهای خطا برای هر خانه به دست آید. مقدار میانگین بهدستآمده هزینه (Cost) تابع شما خواهد بود. حال اگر بتوانیم وزنها را بهگونهای تغییر دهیم که این هزینهها به صفر متمایل شود، عملکرد تابع دقیق خواهد بود. به عبارت دقیقتر، تابع در زمینه محاسبه قیمت خانه در شرایط مختلف بر مبنای دادههای ورودی عملکردی درست خواهد داشت. پس باید وزنها را به شکلی تغییر دهیم تا هزینه به کمترین حد خود برسد.
مرحله سوم
اکنون باید یکبار دیگر مرحله دوم را با ترکیبی از وزنهای مختلف تکرار کرده و در ادامه سعی کنیم ترکیبی را انتخاب کنیم تا مقدار هزینه تابع را به صفر نزدیک کند. اگر در انجام این کار موفق شویم، به معنای آن خواهد بود که برای این مشکل توانستهایم راهحلی پیدا کنیم.
چند نکته کلیدی در ارتباط با روشی که به آن اشاره کردیم
برای آنکه با توانایی الگوریتمهای یادگیری ماشین بهتر آشنا شوید، اجازه دهید به چند نکته کلیدی اشاره کنیم:
• پژوهشهایی که در چهار دهه گذشته در ارتباط با هوش مصنوعی و در حوزههایی شبیه به زبانشناسی/ ترجمه انجام شده، بهوضوح نشان داده که الگوریتمهای یادگیری ماشین ژنریک که در تعامل با آزمایش ترکیبهای مختلفی از ارقام و اعداد هستند، زمانی که در ارتباط با یکسری دستورالعملهای خاص به کار گرفته شوند، کارآیی خیلی بهتری نسبت به عامل انسانی دارند. حتی الگوریتمهایی که از دستورالعمل خاصی تبعیت نمیکنند نیز در عمل نشان دادهاند که بهتر از یک کارشناس حرفهای قادر به پیشبینی هستند.
• تابعی که در بالا آن را پیادهسازی کردید، در حالت کلی غیرهوشمند (Dumb) است. توابعی که در عمل ممکن است فاکتورهایی همچون مساحت خانه و تعداد اتاقخوابها را برای ارائه یک تخمین به کار ببرند، هیچگاه نمیدانند که معنای تعداد اتاقها یا فوت مربع چیست. تنها مزیتی که چنین توابعی دارند در این است که قادر هستند ترکیبهای مختلفی از ارقام را بهعنوان وزنهای مدل آزمایش کنند تا بتوانند پاسخ درستی را ارائه کنند.
• تجربه نشان دادن داده که حتی توسعهدهندگان چنین توابعی نیز بهدرستی نمیدانند که چرا یک مجموعه خاص از وزنها قادر هستند نتایج درستی را ارائه کنند. به عبارت دقیقتر، توسعهدهنده به شما اعلام میدارد تابعی طراحی کرده که نحوه کار آن را بهدرستی نمیتواند تشریح کند، اما در عمل میتواند ثابت کند که این تابع بهدرستی کار خواهد کرد. اتفاقی که نزدیک به دو سال پیش برای متخصصان الگوریتم هوشمند گوگل رخ داد. تابع آنها در آزمایش نتایج درستی را ارائه میکرد اما پژوهشگران این شرکت از درک عملکرد و توضیح روشی که الگوریتم به کار گرفته عاجز بودند. (البته این مسئله در ارتباط با شبکه عمیق عصبی بود.)
یک فرضیه دیگر
تصور کنید که ما بهجای آنکه پارامترهایی همچون مساحت خانه و تعداد اتاقخوابها را به تابع تحویل دهیم، تنها یکسری ارقام را بهعنوان ورودی در اختیار تابع قرار دهیم. اعدادی که تنها بیانگر پیکسلهایی هستند که درون یک تصویر قرار دارند. تصویری که یک دوربین نصبشده مداربسته بالای یک ماشین تهیه کرده است. در این حالت تابع فوق باید در خروجی خود بهجای آنکه به برآورد پیشبینی قیمت بپردازد، برآوردی در ارتباط با میزان زاویه چرخش فرمان ماشین ارائه کند. به عبارت دقیقتر، ما به تابعی نیاز داریم که از طریق آن یک ماشین خودران قادر باشد به تنهایی هدایت را بر عهده بگیرد. اگر سعی کنیم بر مبنای سناریویی که در پاراگراف قبل به آن اشاره داشتیم، ترکیبهای موجود در گام سوم را آزمایش کنیم، به امید آنکه به ترکیبی برسیم که نتیجه مدنظر ما را ارائه کند، شانس کمی برای موفقیت خواهیم داشت. به دلیل اینکه در عمل با یک پروسه زمانبر و طاقتفرسا روبهرو خواهیم شد. در چنین شرایطی پژوهشگران برای حل مسائلی اینچنینی سعی میکنند از روشهایی که هوشمندی بیشتری دارند استفاده کنند. رویکردی که به آنها اجازه میدهد به فرایند پیدا کردن مقادیر صحیحی که بتوان برای وزنها از آنها استفاده کرد شتاب بیشتری ببخشد. بهکارگیری چنین راهکاری به آنها اجازه میدهد دیگر نیازی نداشته باشند ترکیبهای مختلفی از وزنها را آزمایش کنند. اما چطور میتوان به چنین راهکاری دست پیدا کرد؟
راهکاری هوشمندانه برای پیدا کردن وزن مناسب
اجازه دهید در نخستین مرحله معادله سادهای را بنویسیم. معادلهای که به بیان ساده در نظر دارد تابع هزینه را که در مرحله دوم طراحی کردیم، تشریح کند. (شکل 2)
 شکل 2. این تابع هزینه است.
شکل 2. این تابع هزینه است.
اکنون باید معادله نوشتهشده را از طریق یکسری المانهای ریاضی که در اصلاح به آن Jargon میگویند، بازنویسی کرده تا صورت یادگیری ماشین به خود پیدا کند (شکل 3).
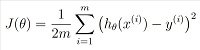 شکل 3. تتا نشاندهنده وزن جاری است. جی تتا هزینه وزنها است.
شکل 3. تتا نشاندهنده وزن جاری است. جی تتا هزینه وزنها است.
در رابطه فوق تتا نشاندهنده وزنهای فعالی است که در الگوریتم به کار گرفتهشده و جیتتا تابع هزینه است که به ازای آن ترکیبی از وزنها به دست میآید. (شکل 4)
 شکل 4. گراف تابع هزینه شما باید شبیه نمودار فوق باشد. محور عمودی بیانگر هزینه است.
شکل 4. گراف تابع هزینه شما باید شبیه نمودار فوق باشد. محور عمودی بیانگر هزینه است.
معادله فوق میزان خطای تابع تخمین قیمت را به ازای مجموعه وزنهایی که برای مدل در نظر گرفتهشده نشان میدهد. برای دقیقتر شدن معادله بهرسم نموداری نیاز داریم تا هزینه را برای همه مقادیر ممکن از وزنها و با توجه به در نظر گرفتن فاکتورهایی همچون تعداد اتاقخوابهای خانه و اندازه خانه به ما نشان دهد. در نموداری که به دست خواهیم آورد، محور عمودی مقدار Cost را نشان میدهد. (شکل 5)
 شکل 5.
شکل 5.
نقطه آبی که در انتها قرار دارد، بیانگر کمترین هزینه است. حال اگر تابع هزینه را با مقدار وزنهای یک ارزیابی کنیم، از روی نمودار میتوان اینگونه برداشت کرد که تابع هزینه ما توانسته به مقدار اشتباه کمینه دست پیدا کند. در نتیجه هر چه مقدار هزینه بهدستآمده از حل معادله فوق در مکانهای بالاتری از این نمودار قرار گیرد، نشان میدهد تابع خطای بیشتری دارد و در نتیجه باید به دنبال پیدا کردن وزنهایی باشیم که مقدار تابع هزینه را برای هر یک از وزنها در پایینترین نقطه نمودار نشان دهد. در چنین شرایطی میتوانیم ادعا کنیم جواب درست را به دست آوردهایم. پس باید به دنبال وزنهای مدل به شکلی باشیم که نقاط در پایینترین سطح از نمودار قرار گرفته و هر زمان تغییری در وزنها به وجود آمد، حرکت پیوسته تابع هزینه به سمت پایین نمودار باشد. با این راهکار به دست آوردن مقدار کمینه درست برای تابع هزینه دیگر به آزمایش ترکیبهای مختلفی از وزنها نیازی نخواهد داشت و در نتیجه تنها از طریق اعمال چند تغییر کوچک در وزنها میتوانیم به ترکیب موردنظر دست پیدا کنیم. فارغالتحصیلان رشته ریاضی بهخوبی میدانند که اگر از تابعی مشتق گرفته شود، شیب نمودار آن تابع در نقاط دلخواه به دست خواهد آمد. به زبان ساده، مشتق یک تابع به ما نشان میدهد از هر نقطه از نمودار چطور میتوان به پایینترین نقطه آن دسترسی پیدا کرد. در نتیجه اگر بتوانیم مشتق جزئی تابع هزینه را برای هر یک از وزنهای مدل ارزیابی کنیم و نتیجه بهدستآمده را از هر یک از وزنها کم کنیم، قادر خواهیم بود تابع موردنیاز خود را یک گام به کمینه شدن نزدیک کنیم. کمینه شدن به معنای رسیدن به پایین نقطه نمودار است. ما قادر هستیم این فرایند را تا زمانی که مقدار کمینه تابع و بهترین ترکیب از وزنها را برای مدل خود به دست آوریم، تکرار کنیم.
روشی که به آن اشاره کردیم، سادهترین تشریح از رویکرد Batch Gradient Descent است. رویکردی که برای به دست آوردن بهترین ترکیب از وزنهای توابع امروزه استفاده میشود. توجه داشته باشید، کتابخانههای یادگیری ماشین که امروزه در اختیار شما قرار دارند بر مبنای الگویی که در بالا به آن اشاره شد، کار میکنند. در نتیجه توابع موجود در این کتابخانهها میتوانند همه این کارها را به شکل خودکار انجام دهند، بدون آنکه شما نیازی داشته باشید خود را درگیر پیادهسازی جزئیات بسیار ریز کنید.

توابعی که در فرایندهای یادگیری ماشین به کار گرفته میشوند
فارغالتحصیلان رشته هوش مصنوعی بهخوبی میدانند الگوریتم سه مرحلهای ذکر شده با عنوان رگرسیون خطی چند متغیره (Multivariate Linear Regression) شناخته شده است. الگوریتمی که با اتکا بر آن میتوان معادله خطی محاسبه کرده، معادله فوق را روی همه دادههای خانههای موجود تنظیم کرد و در نهایت معادله را آموزش داد. در نهایت، میتوان از معادله به دست آمده بهمنظور برآورد قیمت فروش خانههایی که جدید هستند و الگوریتم هیچ شناختی از آنها ندارد، استفاده کرد. همانگونه که ممکن است حدس زده باشید از این الگوریتم میتوان برای حل مسئله بدیهیتر نیز استفاده کرد. به عبارت سادهتر، نمونه ما واقعا جنبه کاربردی دارد. هرچند از چنین رویکردی برای حل مسائل ساده میتوان بهره برد و شاید برای حل مسائل پیچیده کارآیی لازم را نداشته باشد. به دلیل اینکه قیمت خانهها را نمیتوان تنها بر مبنای چند پارامتر تخمین زد و فاکتورهای مرتبط دیگری هم نیاز است. زمانی که فاکتورهای وابسته بهصورت مسئله اضافه شوند، دیگر مسئله با یک معادله خطی ساده قابلحل نخواهد بود. اما نگران نباشید. روشهای متعددی برای حل مسائل پیچیده وجود دارند که از آن جمله به شبکههای عصبی و SVM میتوان اشاره کرد. الگوریتمهایی که برای مدیریت دادههای غیرخطی میتوانند استفاده شوند. هرچند این امکان وجود دارد تا الگوریتمهای رگرسیون خطی را از طریق بهکارگیری راهکارهای هوشمندانهای برای تنظیم شدن با فاکتورهای وابسته به کار گرفت. اما در حالت کلی همه الگوریتمها به دنبال آن هستند تا بهترین ترکیب از وزنها را بهمنظور دستیابی به پاسخ دلخواه پیدا کنند. بهعنوان خوانندهای که با دنیای هوش مصنوعی آشنایی دارد، ممکن است این پرسش را مطرح کنید که ما چرا به موضوع Overfitting اشارهای نداشتیم. مفهومی که توصیفکننده این موضوع است که بخش عمدهای از الگوریتمهای یادگیری ماشین روی دادههای آموزشی تنظیمشده و فقط قادر هستند برای این دادهها جواب دقیقی را ارائه کرده و برای ارائه جواب برای دادههای متفرقه ضریب دقت آنها بهشدت کاهش پیدا میکند. برای حل مشکل Overfitting در مدلهای یادگیری ماشین ما به تکنیکهایی همچون Regularization و همچنین بهرهمندی از مجموعه دادههای Cross-Validation دسترسی داریم اما توصیف این روشها و مشکلات خارج از این نوشتار است.
کلام آخر
درحالیکه مفهوم اصلی مدلهای یادگیری ماشین ساده بوده، اما در مقابل برای آنکه به نتایج دلخواه و دقیقی دست پیدا کنید به تجربه و مهارت بالایی نیاز دارید. مهارتی که با تمرین مستمر به دست میآید. اگر دو بخش این مطلب را مطالعه کرده باشید، بهخوبی میدانید که الگوهای موجود در یادگیری ماشین این پتانسیل را دارند تا مسائل بهظاهر پیچیدهای را که جواب مشخصی برای آنها وجود ندارد، بهراحتی حل کنند. اما این الگوریتمها تنها زمانی که دادههای ورودی درستی را به دست آورند قادر هستند خروجی درستی را ارائه کنند. به بیان ساده، اگر مدلی برای پیشبینی قیمت خانه بنویسیم و در ادامه در نظر داشته باشیم بر مبنای دادهها نوع گلهای موجود در خانه را پیشبینی کنیم، به موفقیتی دست پیدا نخواهیم کرد، بهواسطه آنکه هیچگونه ارتباطی میان گلهای یکخانه و قیمت برآورد شده خانه وجود ندارد. در نتیجه تلاشهای مدل برای ارزیابی از آن جهت با شکست روبهرو خواهند شد که میان دادههای ورودی و خروجی موردنظر ما ارتباط مشخص و مفهومی وجود ندارد تا مسئله حل شود. پس باید به دنبال مدلسازی روابطی باشیم که به معنای واقعی کلمه وجود دارند. به بیان ساده، اگر بهعنوان یک انسان موفق نشوید میان دادههای ورودی و خروجی ارتباطی پیدا کنید، مدلهای یادگیری ماشین نیز موفق نخواهند بود. پس نگاه شما باید روی مسائلی باشد که انسانها قادر هستند آنها را حل کنند، مسائلی که کامپیوترها به شکل سریعتر و با دقت بیشتری قادر به حل آنها هستند. برآورد قیمت سهام یک شرکت از جمله این موارد است.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.






















نظر شما چیست؟