



چگونه موتور پیادهسازی و بهکارگیری کوئریها در GraphQL پیادهسازی میشود؟
- کاربردی، عمومی و انعطافپذیر بودن از جمله مزایای کلیدی و مهم واسطهای برنامهنویسی کاربردی (APIs) هستند و این دقیقا همان چیزی است که GraphQL سعی دارد در اختیار توسعهدهندگان قرار دهد. افزایش سطح عملکرد اصلیترین دلیلی است که باعث میشود یک توسعهدهنده شروع به نوشتن یک کد کاملا سفارشی با REST کند. GraphQL قصد دارد با ارائه یک راهحل منفرد و کامل تمام مراحل طراحی را به صورت ساده و بهینهشده ارائه کند.
GraphQL یک ویژگی است
- قبل از اینکه توضیح دهیم که چه عاملی باعث اهمیت یک GraphQL API میشود باید ابتدا کمی در مورد خود GraphQL توضیح دهیم. GraphQL یک فناوری با کاربرد چندگانه است که میتواند برای مصارف مختلف استفاده شود. قبل از هر چیز باید بدانید که GraphQL بهطور طبیعی یک ویژگی سه بخشی است: الگوی قواعد نوشتاری (schema syntax)، قواعد نوشتاری پرسوجو (query syntax) و یک مرجع اجرای پرس و جو.
الگوی قواعد نوشتاری: توصیف کننده دادهها و API شما
- الگو نشاندهنده این است که دادههای شما به چه شکلی (از نظر ویژگی و نوع) هستند و چگونه میتوان از آن کوئری گرفت. این موضوع شامل نام کوئری، پارامترها و نوع بازگشت میشود. بهطور مثال، یک اپلیکیشن انجام وظایف روزمره شامل فهرستی از وظایف قابل انجام است. اگر این اپلیکیشن تنها یک راه یک سویه برای خواندن این دادهها بهطور مثال بهدست آوردن فهرستی از وظایف روزانه از طریق شناسه فراهم کند، الگوی ما چیزی شبیه به قطعه کد زیر است.
// todo-schema.gql
type Todo {
title: String!
completed: Boolean!
list: List
}
type List {
title: String!
todos: [Todo] @relation
}
type Query {
getList(id: ID): List!
}
قواعد نوشتاری پرسوجو
- نشاندهنده این است که شما چگونه میتوانید دادهها را واکشی کنید. بعد از اینکه الگویی که مشخص میکند دادهها و کوئریهای چگونه خواهند بود را بهدست آوردید، دسترسی به دادهها از نقطه پایانی GraphQL کار بسیار راحتی است. اگر قصد به دست آوردن یک فهرست را دارید تنها کافی است آیتم getList را فراخوانی کنید و مشخص کنید فهرستی که قصد بازگرداندن آنرا دارید باید چه ویژگیهایی داشته باشد. قطعه کد زیر نحوه ساخت این آیتم (getList) را نشان میدهد.
query {
getList(“<some id>){
title
}
}
اگر میخواهید دادهها را به فهرست انجام وظایف روزانه اضافه کنید تنها کافی است یک قطعه کوچک از JSON را به آن اضافه کنید.
query {
getList(“<some id>”){
title
todos {
title
completed
}
}
}
الحاق چگونه رخ میدهد؟ ما هنوز مشخص نکردهایم که این پرسوجو چگونه دادههای دریافت شده از منبع داده را شناسایی و مدیریت میکند. برای حل این مشکل به یک مرجع اجرای پرسوجو نیاز داریم.
مرجع اجرای پرسوجو: یک مرجع برای پیادهسازی اجرای وظایف
- با وجودی که درک الگو و نحوه کوئریگیری کار سادهای است، اما از آنجایی که پیادهسازیهای گوناگونی برای اجرای کوئریگیری وجود دارد، فهميدن اینکه هر کدام از این پیادهسازیها چه تاثیری در وضعیت عملکرد دارند کار دشواری است. GraphQL یک پیادهسازی برای بازیابی اطلاعات شما نیست، بلکه این امکان را فراهم میکند که یک درخواست کوئری را به چند حلکننده مسئله (Resolver) تقسیم کرده و در نهایت به یک پاسخ دست پيدا کنید.
- Resolverها مشخص میکنند که چگونه یک عنصر از کوئری (آنچه GraphQL آنرا فیلد مینامد) به داده تبدیل میشود. سپس بر اساس فراهمکننده GraphQL، چهارچوب مورد استفاده یا در صورت نیاز کدنویسی توسط توسعهدهنده این Resolverها پیادهسازی میشوند. با اینحال در اغلب موارد Resolverها بهطور خودکار در دسترس قرار دارند. وقتی Resolverها در دسترس قرار گرفتند، پیادهسازی میشوند تا مشخص شود آیا این امکان وجود دارد تا GraphQL را به شکل بومی استفاده کنیم یا خیر. بهطور کلی Resolverها توابعی هستند که از ساختار مشخصی تبعیت میکنند. در جاوا اسکریپت یک resolver چیزی شبیه به قطعه کد زیر است:
function someresolver(obj, args, context, info) {
return // do something to get your data
}
و هر کدام از فیلدهای ما یک resolver متناظر خواهند داشت. فیلدها همان ویژگیهای درون الگوی شما هستند.
// todo-schema.gql
type Todo {
title: String!
completed: Boolean!
list: List
}
type List {
title: String!
todos: [Todo] @relation
}
type Query {
getList(id: ID): List!
}
هر کدام از این فیلدها یک تابع resolver دارند که یا به وسیله کتابخانه تولید میشوند یا بهطور دستی پیادهسازی میشوند. اجرای یک کوئری GraphQL در ریشه فیلد آغاز میشود که در مثال ما getList است. از آنجایی که وظیفه getList بازگرداندن یک فهرست است باید فیلدهای درون این فهرست را پر کنیم.
بنابراین برای هر کدام از این فیلدها باید resolver را فراخوانی کرد. در واقع این فرآیند یک فراخوانی عملکرد بازگشتی است. برای روشنتر شدن موضوع به مثال زیر دقت کنید:
query {
getList(“<some id>”){
todos {
title
}
}
}
- getList یک فهرست تک عضوی فیلد todos را بازمیگرداند
- Todos فهرست آیتمها را از getList دریافت میکند و فهرستی از Todoها مرتبط با آن فهرست را باز میگرداند.
- Todos یک آیتم Todo از todos resolver دریافت و یک رشته عنوان را بازمیگرداند.
رویکرد فوق به خودی خود یک روش بازگشتی ظریف برای پاسخ به کوئری است. با این حال خواهیم دید که انتخابهای صورت گرفته در اجرای واقعی تأثیر زیادی بر عملکرد، مقیاسپذیری و رفتار API دارند.
الگوهای نوشتن Resolverها
برای درک رویکردهای مختلف، باید یاد بگیریم که چگونه ساخت موتور اجرای GraphQL را شروع کنیم. قواعد انجام اینکار به کتابخانه سروری که انتخاب میکنیم بستگی دارد، اما هر کدام از این کتابخانهها از دستورالعملهای resolver تبعیت میکند.
Resolverها همان توابع هستند
همانگونه که توضیح داده شد، پیادهسازی یک موتور GraphQL همان پیادهسازی توابعی بهنام resolver با یک نشان خاص است.
function someresolver(obj, args, context, info) {
return // do something to get your data
}
هر کدام از آرگومانها برای اهداف متفاوتی در نظر گرفته شدهاند. مهمترین آنها برای این پیادهسازی شامل این موارد است:
- Obj آبجکت قبلی است. در مثال قبل اشاره کردیم که todos resolver شی List را که توسط getList آماده شده بود دریافت میکند. پارامتر شی برای انتقال نتیجه resolver قبلی در نظر گرفته شده است.
- Args آرگومان است. در getList یک ID را منتقل میکنیم، بنابراین Args معادل{id: "some id"} خواهد بود.
این توابع یک زنجیره resolver را شکل میدهند
ما با یک تابع resolver نمیتوانیم کار زیادی انجام دهیم و کتابخانه سرور GraphQL باید بداند که چگونه یک کوئری را برای resolverهای مختلف طرحریزی کند و چگونه کار را از یک resolver به resolver بعدی واگذار کند. بهطور مثال، قواعد دستوری برای تعیین نقشه کوئریها شبیه به حالت زیر است:
{
Todo: {
title(obj, args, context, info) { ... }
completed(obj, args, context, info) { ... }
list(obj, args, context, info) { ... }
},
List: {
title(obj, args, context, info) { ... }
todos(obj, args, context, info) { ... }
}
Query: {
getList(obj, args, context, info) { ... }
}
}
اگر ما کوئری زیر را بنویسیم میتوانیم با اولین نگاه به resolverهای ریشه در جایی که getList قرار دارد آنرا با resolverها مطابقت دهیم. از آنجایی که resolver یک List را بازمیگرداند، موتور اجرای GraphQL میداند که getList یک فهرست را بازمیگرداند، بنابراین برای resolver فیلد todos باید درون List را جستوجو کند.
query {
getList(“<some id>”){
todos {
title
}
}
}
به این شكل resolverها تحت عنوان زنجيره resolver نامگذاری میشوند (شکل زیر).

توضیحات بالا ممکن است این تصور را ایجاد کنند که کوئریگیری توسط GraphQL کاملا به صورت خطی انجام میشود، اما در حقيقت زنجيره resolverها بیشتر شبیه به ساختارهای درختی هستند (شکل زیر).
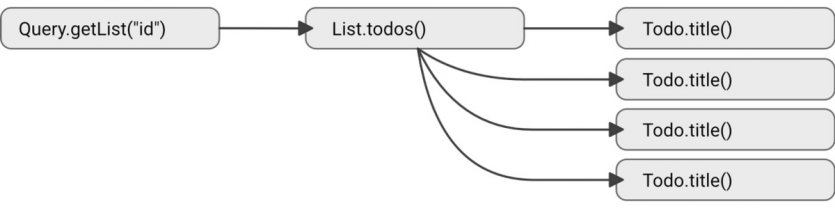
پیادهسازی GraphQL به صورت ساده
وقتی ما resolverها را به جای یک سیستم بازگشتی پیچیده به صورت ساده پیادهسازی میکنیم به یک API کند دسترسی داریم. با اینحال، این توانایی را داریم تا نتایج پیادهسازی ساده طرح درختواره کوئریها را برای یک پایگاه داده ارسال کنیم (شکل زیر).
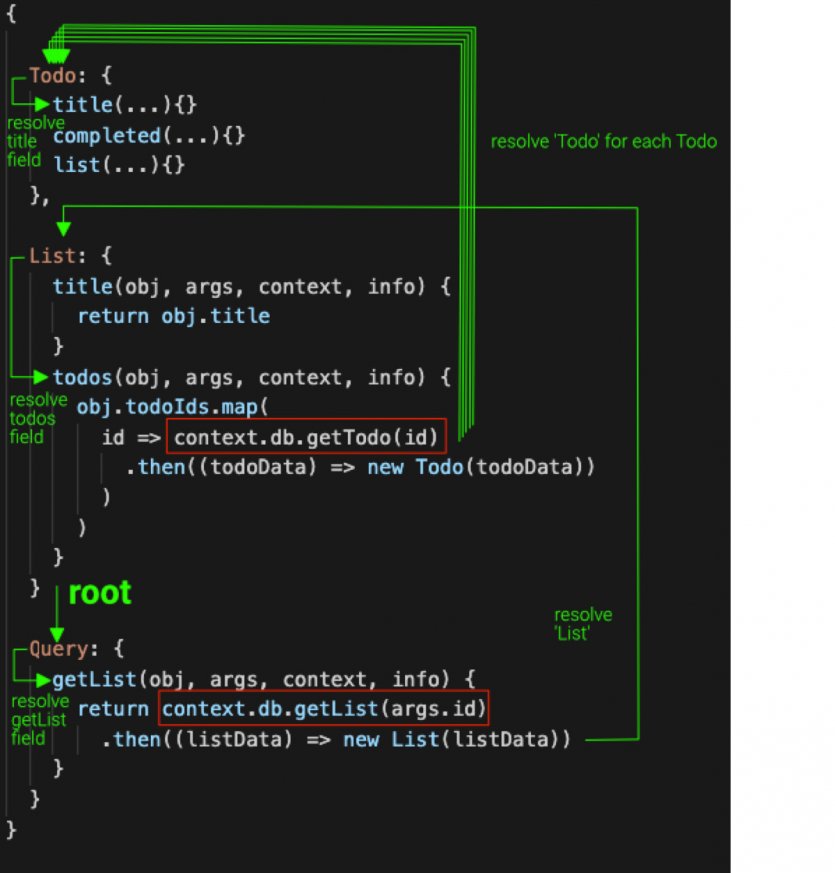
اگر چه در پیادهسازی قطعه کد بالا تنها دو پایگاه داده فراخوانی شده، اما تنها یکی از آنها (getTodo(id)) برای هر Todo که به List مرتبط است فراخوانی شده است. یک REST API این امکان را میدهد تا هر یک از این منابع را جدا از فرانتاند فراخوانی کنیم. در زمان استفاده از GraphQL باید به دو مورد زیر دقت کنید:
- در زمان چند فراخوانی همزمان از فرانتاند، لازم است تا دادهها نیز در فرانتاند به یکدیگر مرتبط شوند.
- باید به فکر راهحلهای جایگزینی برای ساخت یک نقطه پایانی سفارشی با هدف بهبود عملکرد یا برای هر یک از درخواستهای جدید ارائه شده توسط برنامه باشید. بهطور مثال، اگر برای اپلیکیشن موبایل یک رابط کاربری جدید در اختیار دارید، ممکن است درخواست متفاوتی داشته باشد (شکل 4). در پیادهسازی ساده ما تعداد بیشتری کوئری بین بکاند و پایگاه داده داریم و نتایج باید در بکاند ترکیب شوند. الحاق چند درخواست کوچک به حافظه نیاز دارد و در حجمهای گسترده ممکن است پایگاه داده را دچار اختلال کند.
دستهبندی با Dataloader
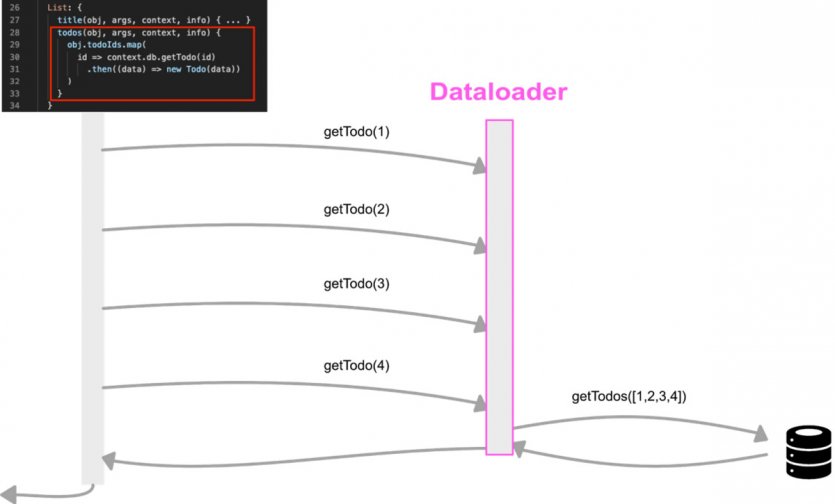
فیسبوک یک نرمافزار کارآمد بهنام Dataloader ساخته که اجازه میدهد بخشی از مشکل را برطرف کنید. وقتی از Dataloader استفاده میکنید، کوئریهای مشابه در هر فریم ذخیره میشوند. شکل پنج نحوه فرآیندهای انجام شده توسط Dataloader را نشان میدهد (شکل زیر).

Dataloader تمام این کوئریها را دریافت میکند، منتظر پایان فریم میماند و در انتها آنها را در یک کوئری ترکیب میکند (شکل زیر). علاوه بر این، Dataloader برخی از نتایج جستوجو را در حافظه ذخیره میکند. با Dataloader تعداد فراخوانیهای پایگاه داده به میزان چشمگيری بهینهسازی میشود.
جمعبندی
استفاده از GraphQL بسیار ساده است و به همین دلیل است که به سرعت به زبان محبوبی برای کوئریگیری از یک پایگاه داده تبدیل شده است. این واقعیت که میتوان از یک زبان آشنا برای بازیابی دادهها از انواع مختلفی از پایگاههای داده و APIها استفاده کرد، نقش مهمی در محبوبیت GraphQL داشته است. با GraphQL، شما دادههایی که دوست دارید را مینویسید و همان دادههایی که نیاز دارید را به دست میآورید و دیگر واکشی اطلاعات بیش از حد نیاز چنان که در REST مرسوم است ضرورتی نخواهد داشت
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.



















نظر شما چیست؟