










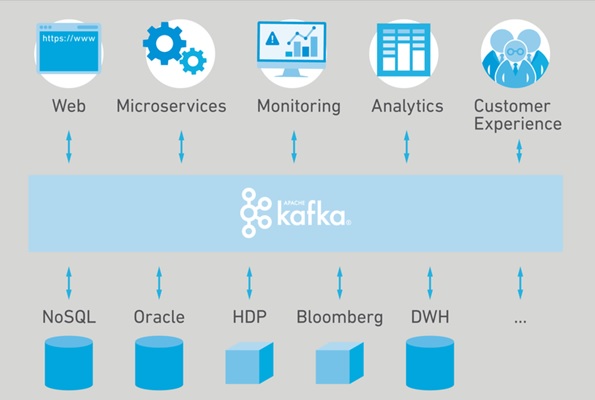
آپاچی کافکا
این پروژه با هدف ارائه یک زیرساخت قدرتمند با زمان تأخیر کم واحد و یکپارچه برای دستکاری اطلاعات ورودی به صورت بلا درنگ تولید شدهاست. لایه ذخیرهسازی آن اساساً برای یک معماری کارگزار – صف در مقادیر انبوه و مقیاسهای بزرگ به صورت توزیع شدهاست. کافکا برای پردازش جریان دادهها (Stream Processing) و کارگزار ارسال و دریافت پیام (Message Broker) مورد استفاده قرار میگیرد. علاوه بر این، کافکا امکان اتصال به سیستمهای خارجی (برای دادههای ورودی / خروجی) از طریق Kafka Connect و provides Kafka Streams را فراهم میکند. کافکا برای مدریت حجم انبوهی از دادهها که بی وقفه در حال ارسال هستند و فرصت کافی برای پردازش و ذخیرهسازی وجود ندارد بهترین عملکرد را دارد، علاوه بر این کافکا به خوبی قادر به مدیریت خطاها است.
چگونه از کافکا استفاده کنیم؟
اولین قدم برای استفاده از کافکا ساخت یک Topic است. از این به بعد میتوان از طریق ارتباط TCP پیامهای جدید را جهت ذخیرهسازی در Topic جدید ارسال نمود. این کار به سادگی از طریق Clientهایی که به زبانها و برای پلتفرمهای مختلف طراحی شدهاند قابل انجام است. سپس این پیامها باید در جایی ذخیره گردد. کافکا این پیامها را در فایلهایی با نام Log ذخیرهسازی مینماید. دادههای جدید به انتهای فایلهای Log افزوده میگردند. کافکا این توانایی را دارد که پیامهای ارسالی را بر روی مجموعه ای از سرورهای کافکا که با یکدیگر کلاستر (Cluster) شدهاند، ذخیرهسازی نماید. اگر بهطور مثال تعداد n سرور کافکا در یک کلاستر وجود داشته باشند، دادههای مرتبط با هر پیام ارسالی پس از ذخیرهسازی بر روی سرور لیدر، بر روی تمامی سرورهای پشتیبانی نیز کپی خواهد گردید. با این وصف، حتی اگر n-1 عدد از سرورها از سرویس خارج شوند، دادههای Topic مورد نظر کماکان در دسترس و قابل استفاده خواهند بود. از این رو تحمل پذیری در برابر خطا به خوبی در کافکا دیده شده میشود.
خواندن اطلاعات ذخیره شده روی کافکا (Kafka) نیز از طریق Clientها قابل انجام است. کلاینت مصرفکننده پیام که به اصطلاح Consumer نامیده میشود، جهت خواندن پیامها باید خود را Subscribe یک Topic مشخص نماید. از این پس با اجرای متد Poll، دادهها به سمت مصرفکننده سرازیر میشوند. در هنگام تعریف Topic جدید این امکان وجود دارد که دادههای مرتبط با آن در چند پارتیشن ذخیره شوند. در واقع کافکا تمامی پیامهای ارسالی به یک Topic را در تمامی پارتیشنها به همان ترتیبی که ارسال شدهاند به صورت توزیع شده ذخیره میکند. در این مدل ذخیرهسازی، هر پارتیشن بر روی یک سرور ذخیره شده و سایر سرورهای حاضر در Cluster نسخه پشتیبان آن پارتیشن را کپی خواهند کرد. این ویژگی کافکا به مصرفکننده این امکان را میدهد که به صورت موازی اطلاعات را دریافت نماید.
آپاچی اسپارک
آپاچی اسپارک (Apache Spark) یک چارچوب رایانش توزیعشده متنباز است. این نرمافزار در ابتدا توسط دانشگاه کالیفرنیا، برکلی توسعه داده میشد که بعدها کد آن به بنیاد نرمافزار آپاچی هدیه گردید که از آن زمان توسط آنها نگهداری میشود. اسپارک یک رابط برنامهنویسی کاربردی برای برنامهنویسی تمام خوشهها با موازیسازی دادههای ضمنی و تحمل خطا فراهم میکند. اسپارک از حافظه اصلی برای نگهداری دادههای برنامه استفاده میکند که این امر باعث سریعتر اجرا شدن برنامهها میشود (برخلاف مدل نگاشت/کاهش که از دیسک به عنوان مکان ذخیرهسازی دادههای میانی استفاده میکند). همچنین یکی دیگر از مواردی که باعث افزایش کارایی اسپارک میشود، استفاده از مکانیسم حافظه نهان هنگام استفاده از دادههایی است که قرار است دوباره در برنامه استفاده شوند. اینکار باعث کاهش سربار ناشی از خواندن و نوشتن از دیسک میشود. یک الگوریتم برای پیادهسازی در مدل نگاشت/کاهش، ممکن است به چندین برنامه مجزا تقسیم شود و در هنگام اجرا هر بار باید دادهها از دیسک خوانده شده، پردازش شوند و دوباره در دیسک نوشته شوند. اما با استفاده از مکانیسم حافظه نهان در اسپارک، دادهها یکبار از دیسک خوانده میشوند و در حافظه اصلی کَش میشوند و عملیاتهای متفاوت بروی آن اجرا میشود. در نتیجه استفاده از این روش نیز باعث کاهش چشمگیر سربار ناشی از ارتباط با دیسک در برنامهها و بهبود کارایی میشود.
اسپارک از چه مولفههای ساخت شده است؟
Spark Core: هسته اسپارک حاوی عملیاتهای اولیه اسپارک از جمله اجزای موردنیاز برای زمانبندی وظایف، مدیریت حافظه، مقابله با خطا، تعامل با سیستم ذخیرهسازی و … میباشد . هسته اسپارک همچنین محل توسعه APIهایی میباشد کهRDDها را تعریف میکنند و RDDها مفهوم اصلی برنامهنویسی اسپارک میباشند. RDDها نشانگر مجموعهای از آیتمها هستند که بر روی گرههای محاسباتی متعدد توزیع شده و میتوان آنها را به صورت موازی پردازش کرد. هسته اسپارک APIهای متعددی را برای ایجاد و دستکاری این مجموعهها ارائه میدهد.
Spark SQL: اسپارک SQL چهارچوبی برای کار کردن با دادههای ساختیافته و دارای ساختار میباشد. این سیستم پرسوجو دادهها را از طریق SQL و همچنین آپاچی هایو، نوع دیگر SQL که HQL نیز نامیده میشود، امکانپذیر ساخته و از منابع داده از جمله جداول هایو، ساختار دادههای Parquet،CSV و JSON پشتیبانی میکند. علاوه بر ارائه یک رابط کاربری SQL برای اسپارک، اسپارک SQL توسعه دهندگان را قادر میسازد تا پرسوجوهای SQL را با عملیاتهای تغییر دادهها بروی RDDها که در پایتون، جاوا و اسکالا پشتیبانی میشود، ترکیب کرده و در یک برنامه پرسجوهای SQL را با تحلیلهای پیچیده منسجم کرد. این انسجام نزدیک با محیط پردازشی ارائه شده توسط اسپارک، اسپارک SQLرا از سایر ابزارهای انبار داده متن باز متمایز میکند.
Spark Streaming: مولفه پردازش دادههای جریانی اسپارک یکی از اجزای اسپارک است که پردازش جریان دادهها را فراهم میآورد. از نمونههای جریان دادهها میتوان به فایلهای لاگ ایجاد شده توسط سرورهای وب یا مجموعه پیامهای حاوی به روز رسانی وضعیت ارسال شده توسط کاربران یک وب سرویس و یا در شبکههای اجتماعی نظیر ارسال کردن یک پست اشاره کرد. این مؤلفه APIهایی را برای تغییر جریانهای داده که با APIهای مربوط به RDDهای موجود در هسته اسپارک همخوانی دارد، ارائه میدهد و این امر موجب تسهیل توسعه برنامه برای توسعهدهندگان و سوییچ بین برنامههایی که دادهها را در حافظه اصلی، بر روی دیسک و یا در زمان واقعی پردازش میکنند، میشود. در معماری توسعه این APIها، به منظور برخورداری از قابلیت تحمل خطا، بهرهوری بالا و مقیاس پذیری، همانند مؤلفه هسته اسپارک به نکات مربوط به توسعه سیستمهای توزیع شده توجه شدهاست.
MLlib: اسپارک دارای کتابخانهای متشکل از APIهای یادگیری ماشین (ML) با نام MLlib میباشد. MLlib انواع مختلفی از الگوریتمهای یادگیری ماشین از جمله طبقهبندی، تحلیل رگرسیون، خوشهبندی و پالایش گروهی را ارائه میدهد و همچنین از قابلیتهای مثل ارزیابی مدل و ورود دادهها پشتیبانی میکند. MLlib همچنین ساختارهای سطح پایین یادگیری ماشین مثل الگوریتم بهینهسازی گرادیان نزولی را فراهم میآورد. تمام این روشها با منظور اجرا کردن این برنامهها در سطح کلاستر اسپارک طراحی شدهاند.
GraphX: GraphX یک کتابخانه برای پردازش گرافها و انجام پردازشهای موازی بروی دادههای گراف میباشد. GraphX همانند مؤلفههای اسپارک استریمینگ و اسپارک SQL، APIهای RDDها را توسعه داده و ما را قادر میسازد تا گرافهای جهتدار با نسبت دادن مشخصات به هر گره و یال ایجاد کنیم. GraphX همچنین عملگرهای مختلفی را برای تغییر گرافها (نظیر subgraph و mapVertices) و کتابخانهای از الگوریتمهای گراف (نظیر PageRank و شمارش مثلثهای گراف) فراهم آورده است
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.


















نظر شما چیست؟