




یادگیری ترکیبی (Hybrid Learning)
آیا این امکان وجود دارد که بتوانیم تکنیکها و روشهایی در حوزه یادگیری عمیق ابداع کنیم تا از سد محدودیتهایی که یادگیری باناظر و بدون ناظر را احاطه کردهاند عبور کنیم، بهطوری که حجم وسیعی از دادههای فاقد برچسبگذاری و استفادهنشده را تطابق داده و از آنها استفاده کنیم؟ در ظاهر، انجام چنین کاری سخت بهنظر میرسد، زیرا نیازمند پارادایمهای پیشرفتهتر و البته پیچیدهتری هستیم.
یادگیری مرکب (Composite learning)
چگونه میتوان مدلها یا مولفههای مختلف را به روشهای خلاقانهای به یکدیگر متصل کرد تا یک مدل مرکب را که شامل بخشهای مختلفی است پدید آورد؟
یادگیری کاهشیافته (Reduced learning)
چگونه میتوان اندازه و جریان اطلاعات مدلها را بهگونهای کاهش داد تا عملکرد بهبود پیدا کرده و فرآیند استقرار سادهتر شود، در حالیکه قدرت پیشبینی دستخوش تغییری نشده یا حتا بهتر شود؟
دورنمای شبکههای عصبی عمیق نشان میدهد که آینده یادگیری عمیق از آن سه پارادایمی است که به آنها اشاره کردیم و جالب آنکه هر یک از آنها با دیگری مرتبط است.
یادگیری ترکیبی (Hybrid Learning)
این پارادایم در تلاش است بر محدودیتهای پیرامون یادگیری تحت نظارت و بدون نظارت (خودناظر) غلبه کند. بهطور کلی، مدلهای یادگیری ماشین تحت نظارت و بدون نظارت با مشکلاتی مثل عدم دسترسی به منابع دادهای بالا، هزینه زیاد دسترسی به دادههای برچسبگذاریشده و فقدان اطلاعات کافی در مورد حوزه خاصی از تجارت روبهرو هستند. در حقیقت، یادگیری ترکیبی بهدنبال پاسخی برای این پرسش است که چگونه میتوانیم از روشهای نظارتشده برای حل مشکلات پیرامون مدلهای بدون ناظر استفاده کنیم؟
بهعنوان مثال، یادگیری نیمه-نظارتی (semi-supervised learning) در جامعه یادگیری ماشین، بهدلیل عملکرد فوقالعاده خوبی که در حل مشکلات الگوهای نظارتی و بهویژه دادههای کمتر برچسبگذاریشده دارد، مورد توجه قرار گرفته است. بهعنوان مثال، یک شبکه مولد تخاصمی نیمهنظارتی با طراحی خوب، پس از مشاهده تنها 25 نمونه آموزشی، قادر است با دقتی بالای 90 درصد در مجموعه دادههای MNIST (پایگاه بزرگی از دستخطها )خروجی درستی ارائه کند.
یادگیری نیمهنظارتی یا به تعبیری نیمهنظارتشده برای مجموعه دادههایی طراحی شده که در آنها دادههای نظارتنشده زیادی در دسترس نیست و تنها دادههای نظارتشده کمی در اختیار پژوهشگران قرار دارد. در حالیکه بهطور سنتی یک مدل یادگیری نظارتشده بر روی یک بخش از دادهها و یک مدل بدون نظارت برای بخش دیگری آموزش داده میشوند، یک مدل نیمهنظارتشده میتواند دادههای برچسبگذاریشده را با بینشهای استخراج شده از دادههای بدون برچسب ترکیب کند. شکل 1

شکل 1
این موضوع را نشان میدهد. شبکه مولد تخاصمی نیمهنظارتشده SGAN سرنام Semi-supervised Generative Adversarial Network اقتباسی از مدل استاندارد شبکه مولد متخاصمی است. در اینجا، متمایزگری که هر دو خروجی 0/1 را نشان میدهد و مشخص میکند که آیا تصویری تولید شده یا خیر، در عین حال خروجی کلاس را نیز نشان میدهد (آموزش چندخروجی).
تکنیک فوق بر مبنای این ایده توسعه پیدا کرده که یک مدل بتواند از طریق تکنیک یادگیری متمایزکننده، تفاوت میان تصاویر واقعی و تولیدشده را تشخیص دهد و در ادامه ساختار آنها را بدون استفاده از دادههای برچسبگذاریشده درک کند. در ادامه برای بهبود خروجی، مقدار کمی دادههای برچسبگذاریشده برای تقویت عملکرد در اختیار مدل قرار میگیرد تا مدلهای نیمهنظارتشده بتوانند با کمترین مقدار دادههای نظارتی، بالاترین سطح از عملکرد را ارائه کنند.
علاوه بر این، شبکههای مولد تخاصمی در حوزه دیگری از یادگیری ترکیبی تاثیرگذار هستند که یادگیری خودنظارتی (self-supervised learning) نام دارد و در آن مسائل بدون ناظر بهشکل صریح بهعنوان موارد نظارتشده در اختیار مدل قرار میگیرند. شبکههای مولد تخاصمی بهطور مصنوعی دادههای نظارتشده را از طریق معرفی یک مولد (generator) ایجاد میکنند و برچسبهایی برای شناسایی تصاویر واقعی/تولیدشده ایجاد میکنند تا یک فرآیند کاری خودناظر بهعنوان یک فرآیند کاری نظارتشده به سرانجام برسد. تقریبا مشابه کاری که در جلسات آزمونهای ریاضی گسسته انجام میدهیم و سعی میکنیم از طریق استدلالها و استقرا به پاسخ برسیم.
روش دیگر، استفاده از مدلهای رمزگذار-رمزگشا برای فشردهسازی است. در سادهترین شکل، تکنیک فوق توصیفکننده شبکههای عصبی با تعداد محدودی گره میانی است که نوعی گلوگاه متراکم بهوجود میآورند. در اینجا دو مولفه در دو طرف این گلوگاه قرار دارند و بهنام کدگذار (Coder) و کدگشا (Encoder) شناخته میشوند.

شکل 2
در اینجا، شبکه برای تولید خروجی یکسان با ورودی برداری (یک کار نظارتشده مصنوعی از دادههای بدون نظارت) آموزش دیده است. از آنجایی که یک گلوگاه بهعمد در میانه قرار دارد، شبکه نمیتواند اطلاعات را بهطور غیرفعال منتقل کند. در مقابل، باید بهترین روشها را برای حفظ محتوای ورودی در یک واحد کوچک شناسایی کند، بهطوری که اطلاعات در آن سوی گلوگاه توسط رمزگشا بهطور منطقی رمزگشایی شود.
برای تشریح این مسئله اجازه دهید به ذکر مثالی بپردازیم. هنگامیکه تجربه کار عملی با یک زبان برنامهنویسی مثل سیپلاسپلاس را دارید و در ادامه تصمیم میگیرید به مقطع کارشناسی نرمافزار وارد شوید، استاد درس سیپلاسپلاس در کلاس مسئلهای را مطرح میکند و شما بر مبنای دانش قبلی بهراحتی آنرا حل میکنید، حتا اگر راهحلی که ارائه میکنید بهینه نباشد. اما هنگامیکه استاد شما را محدود کند که تنها بر مبنای اطلاعاتی که تاکنون آموزش داده باید مسئله را حل کنید، آنگاه مجبور هستید کمی تامل کنید تا بتوانید بهترین راهحل را برای مسئله ارائه کنید. کاری که تکنیک کدگذار و کدگشا انجام میدهد به همین ترتیب است.
پس از تکمیل آموزش، رمزگذار و رمزگشا از هم جدا میشوند. در اینجا میتوان از آنها برای دریافت دادههای فشرده یا رمزگذاریشده بهمنظور انتقال حجم کمتری از دادهها، بدون آنکه دادهها از دست بروند استفاده کرد. همچنین میتوان از آنها برای کاهش ابعاد دادهها استفاده کرد.
بهعنوان مثالی دیگر، مجموعه بزرگی از متون بهطور مثال، نظرهایی را که در یک پلتفرم دیجیتال وارد میشوند در نظر بگیرید. ما میتوانیم از طریق بهکارگیری برخی روشهای خوشهبندی یا یادگیری چندگانه، برچسبهای خوشهای برای مجموعههای متنی تولید کنیم، بهطوری که در ادامه از آنها بهعنوان برچسب استفاده کنیم (البته بهشرطی که خوشهبندی بهخوبی انجام شود).
پس از تفسیر هر خوشه (بهطور مثال، خوشه A نظراتی را نشان میدهد که بازتابی از شکایت در مورد یک محصول است، خوشه B بازتابدهنده بازخوردهای مثبت است و غیره) یک معماری عمیق پردازش زبان طبیعی مانند BERT میتواند برای طبقهبندی متون جدید در این خوشهها استفاده شود. دقت کنید در اینجا دادهها کاملاً بدون برچسب هستند و از کمترین مقدار ممکن استفاده میشود.
در اینجا، دومرتبه هدف این است که یک برنامه کاربردی برای تبدیل فرآیندهای بدون نظارت به فرآیندهای تحت نظارت ایجاد کرد. در عصری که بخش عمدهای از دادهها فاقد برچسب هستند، مجبور هستیم از رویکردهای خلاقانهای برای عبور از سد محدودیت الگوریتمهای یادگیری تحت نظارت و بدون نظارت با اتکا بر یادگیری ترکیبی استفاده کنیم.
یادگیری مرکب (Composite Learning)
یادگیری مرکب، رویکردی متفاوت از حالت ترکیبی دارد و همانگونه که از نامش پیدا است، نه بهدنبال استفاده از دانش یک مدل بلکه بهدنبال بهکارگیری دانش چند مدل است. ایدهای که در پسزمینه شکلگیری تکنیک یادگیری مرکب وجود دارد به این نکته اشاره دارد که اگر بتوانیم از طریق ترکیبات منحصربهفرد یا اطلاعات ایستا و پویا، کاری کنیم که یادگیری عمیق بهطور مداوم در حال آموزش باشد، در نهایت درک عمیقتر و عملکرد بهتری پیدا میکند.
یادگیری انتقالی (Transfer learning) یک مثال واضح از یادگیری مرکب است و بر این ایده تاکید دارد که وزنهای یک مدل را میتوان از مدلی که برای یک کار مشابه از قبل آموزش دیده است به عاریت گرفت و آنها را بهگونهای ویرایش کرد که برای انجام یک کار خاص استفاده شوند. مدلهای ازپیشآموزشدیده مانند Inception یا VGG-16 با معماریها و وزنهایی ساخته شدهاند که برای تشخیص تمایز میان چند کلاس مختلف از تصاویر طراحی شدهاند.
بهطور مثال، اگر در نظر داشته باشیم یک شبکه عصبی برای تشخیص حیوانات (گربه، سگ و غیره) آموزش دهیم، طبیعی است که یک شبکه عصبی پیچشی (convolutional neural network) را از ابتدا آموزش نمیدهیم، زیرا دستیابی به نتایج مطلوب زمانبر خواهد بود. در مقابل، یک مدل ازپیشآموزشدیده مانند Inception را انتخاب میکنیم که قبلاً اصول تشخیص تصویر را در اختیار دارد و در ادامه چند مجموعه داده دیگر را برای آموزش در اختیار مدل قرار میدهیم.
بهطور مشابه، در فرآیند جایگذاری کلمات در شبکههای عصبی پردازش زبان طبیعی سعی میشود کلماتی که از نظر فیزیکی و معنایی بهیکدیگر نزدیکتر هستند، در یک مجموعه آموزش بسته که قرار است تشریحکننده روابط باشند استفاده شوند (بهطور مثال، واژه سیب و پرتغال فاصله معنایی کمتری نسبت به سیب و کامیون برای یک مدل دارند). هدف این است که فرآیند تشخیص معنایی و نقشهبرداری بهشکل معنادارتر و سریعتر انجام شود. از اینرو، در مدل مرکب سعی میشود از تواناییهای چند مدل برای ساخت یک مدل قدرتمند استفاده شود.
بدیهی است در چنین پارادایمی مدلها در رقابت برای ارائه نتایج، درک بهتری از مفاهیم بهدست میآورند. در سناریو، مبتنی بر شبکههای مولد متخاصمی مرکب که مبتنی بر دو شبکه عصبی است، هدف مولد فریب دادن متمایزگر است و هدف متمایزگر فریب نخوردن است.
رقابت بین مدلها بهعنوان یادگیری تخاصمی (Adversarial learning) نامیده میشود که نباید با نوع دیگری از یادگیری تخاصمی که به طراحی ورودیهای مخرب و بهرهبرداری از مرزهای تصمیمگیری محدود در مدلها اشاره دارد، اشتباه گرفته شود. در نمونههای تخاصمی، این امکان وجود دارد که ورودیهایی برای شبکه مخرب طراحی شده باشند و بهلحاظ مفهومی، امکان تشخیص معتبر بودن و صحیح بودن آنها برای مدل وجود نداشته باشد، اما بازهم بهاشتباه توسط مدل طبقهبندی شوند.
یادگیری تخاصمی میتواند انواع مختلفی از مدلها را تحریک کند، بهطوری که عملکرد یک مدل را در رابطه با عملکرد دیگر مدلها نشان داد. لازم به توضیح است که هنوز هم باید تحقیقات زیادی در زمینه یادگیری تخاصمی انجام شود.
از سوی دیگر، یادگیری رقابتی (Competitive learning) وجود دارد که شبیه به یادگیری تخاصمی است، اما در مقیاس گره به گره انجام میشود، بهطوری که گرهها برای حق پاسخ به زیرمجموعهای از دادههای ورودی با یکدیگر رقابت میکنند. یادگیری رقابتی در یک لایه رقابتی پیادهسازی (competitive layer) میشود که در آن مجموعهای از سلولهای عصبی به جز برخی وزنهای توزیعشده تصادفی یکسان هستند. بردار وزن هر سلول عصبی با بردار ورودی مقایسه میشود و سلول عصبی که بیشترین شباهت را دارد، بهعنوان سلول عصبی برنده فعال میشود (خروجی = 1) و مابقی در وضعیت غیرفعال (خروجی = 0) قرار میگیرند. این تکنیک بدون نظارت، مولفه اصلی نقشههای خودسازماندهی و کشف ویژگی است.
نمونه جالب دیگر از یادگیری ترکیبی در مورد جستوجوی معماری عصبی است. بهعبارت سادهتر، یک شبکه عصبی (معمولاً تکراری) در یک محیط یادگیری تقویتی یاد میگیرد که بهترین شبکه عصبی را برای مجموعه داده ایجاد کند و بهترین معماری را برای شما پیدا میکند.
روشهای جمعی (Ensemble methods) از مولفههای بنیادین یادگیری ترکیبی هستند. روشهای Deep Ensemble نشان دادهاند که عملکرد قابل قبولی دارند و باعث محبوبیت روزافزون مدلهای مبتنی بر انتها به انتها، مانند رمزگذارها و رمزگشاها شدهاند.
بخش اعظم یادگیری مرکب یافتن راههای منحصربهفرد برای ایجاد ارتباط بین مدلهای مختلف است و بر این ایده استوار است که یک مدل واحد، حتا یک مدل بسیار بزرگ نمیتواند در تمام شرایط عملکرد عالی نسبت به چند مدل/مولفه کوچکی داشته باشد که هر کدام در بخشی از کار خود تخصص دارند. بهعنوان مثال، وظیفه ساخت چتباتی برای یک رستوران را در نظر بگیرید (شکل 3).
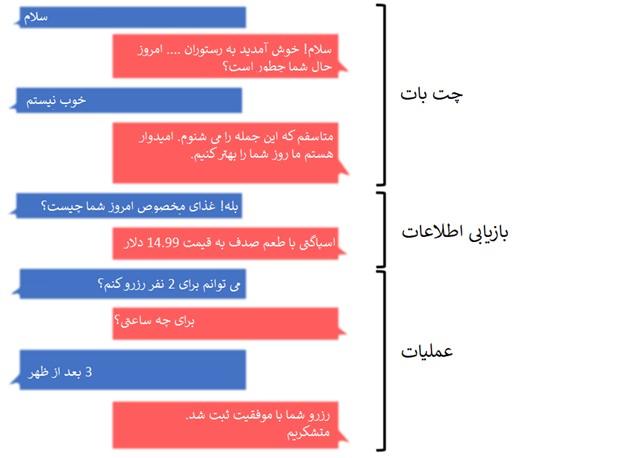
شکل 3
ما میتوانیم این فرآیند را به سه بخش مجزا تقسیم کنیم: لذتها/چتبات، بازیابی اطلاعات و یک فرآیند اجرایی. در ادامه مدلی طراحی کنیم که متخصص در رسیدگی به این فرآیندها باشد یا مدلی طراحی کنیم که هر بخش آن مسئولیت رسیدگی به یک وظیفه مشخص را داشته باشد (شکل 4).
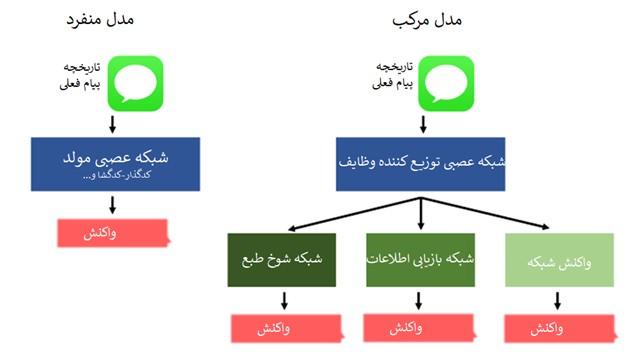
شکل 4
جای تعجب نیست که مدل مرکب میتواند عملکرد بهتری داشته باشد، در حالی که فضای کمتری را اشغال میکند. علاوه بر این، این نوع توپولوژیهای غیرخطی را میتوان بهراحتی با ابزارهایی مانند واسطهای برنامهنویسی کاربردی (APIs) کتابخانههایی مثل Keras ایجاد کرد. پیشنهاد شخصی من این است که برای پردازش انواع متنوعی از دادهها، مثل ویدئوها و دادههای سه بعدی، محققان باید روی ساخت مدلهای مرکب متمرکز شوند.
یادگیری کاهشی (Reduced Learning)
اندازه مدلها، بهویژه در حوزه پردازش زبان طبیعی به یکی از داغترین مباحث یادگیری عمیق تبدیل شده و تاکنون تحقیقات زیادی در این زمینه انجام شده است. جدیدترین مدل GPT-3 دارای 175 میلیارد پارامتر است که مقایسه آن با مدل BERT مانند قیاس دوچرخه با هواپیما است (شکل 5).

شکل 5
همانگونه که در شکل ۵ مشاهده میکنید، GPT-3 کاملا قدرتمند است. ما بهسمت دنیایی مبتنی بر هوش مصنوعی در حال حرکت هستیم، جایی که یک یخچال هوشمند میتواند بهطور خودکار مواد غذایی سفارش دهد و هواپیماهای بدون سرنشین میتوانند بخش عمدهای از وظایف شهری را بر عهده بگیرند. علاوه بر این، شاهد این موضوع هستیم که روشهای یادگیری ماشین قدرتمند بهتدریج به مولفههای سختافزاری کامپیوترهای شخصی، گوشیهای هوشمند و حتا تجهیزات اینترنت اشیاء وارد شدهاند. تمامی این مولفهها نیازمند یک الگوریتم هوشمند سبکوزن هستند. الگوریتمی که توانایی ساخت شبکههای عصبی کوچکتر را با حفظ عملکرد داشته باشد.
بهنظر میرسد که بهطور مستقیم یا غیرمستقیم، تقریبا همهچیز در تحقیقات یادگیری عمیق به کاهش مقدار پارامترها در حال حرکت است که با بهبود تعمیم و در نتیجه بهبود عملکرد همراه است. بهعنوان مثال، معرفی لایههای پیچشی کمک کرده است تا تعداد پارامترهای مورد نیاز شبکههای عصبی برای پردازش تصاویر کاهش پیدا کند. بهطوری که سعی میشود وزنهای یکسان ترکیب شوند و شبکههای عصبی توالیها را بهتر و با پارامترهای کمتر پردازش کنند.
لایههای تعبیهشده به صراحت موجودیتها را به مقادیر عددی با معانی فیزیکی ترسیم میکنند، بهطوری که بار اضافی روی پارامترها قرار نمیگیرد.
بهطور مثال، این امکان وجود دارد که از تکنیک منظمسازی در هر نقطهای که احساس میکنید دادهها با مشکل بیشبرازش (overfitting) روبهرو شدهاند و عملکرد کاهش پیدا کرده استفاده کرد. بهطور مثال، اگر لایههای Dropout با شکست روبهرو شوند، این امکان وجود دارد که معیارها را ارزیابی کرد و و در لایههای L1 و L2 تغییراتی در پارامترها بهوجود آورد. میتوانید از تکنیک منظمسازی (Regularization) لایه اول و لایه دوم استفاده کنید تا شبکه از تمام پارامترهای خود بهشکل بهینه استفاده کند و مطمئن شوید که هیچ یک از لایهها بیشازاندازه بزرگ نمیشوند و هر کدام بالاترین و باکیفیتترین سطح از اطلاعات را ارائه میکنند.
با ایجاد لایههای تخصصی، شبکهها برای دادههای پیچیدهتر و بزرگتر به پارامترهای کمتر و کمتری نیاز دارند. سایر روشهای جدیدتر نیز به صراحت بهدنبال فشردهسازی شبکه هستند.
موضوع مهم دیگری که در مورد یادگیری کاهشیافته وجود دارد، هرس است. هرس (pruning) شبکه عصبی بهدنبال حذف سیناپسها و سلولهایی عصبی است که ارزشی برای خروجی شبکه ندارند. از طریق هرس، شبکهها میتوانند عملکرد خود را حفظ کنند.
تمامی این تلاشها با هدف فشردهسازی و کوچک کردن مدلهایی انجام میشود که قرار است روی دستگاههای مصرفی مثل گوشیهای هوشمند مستقر شوند. دقیقا همین ملاحظات باعث شد تا سیستم ترجمه ماشین عصبی گوگل (GNMT) عملکرد سرویس Google Translate را بهبود دهد. بهطوری که امروزه سرویسی با دقت بالا در ترجمه است که حتا بهشکل آفلاین نیز امکان استفاده از آن وجود دارد.
امروزه بخشی از تحقیقات پیرامون یادگیری عمیق حول محور یادگیری کاهشی در حرکت هستند و سعی دارند از بهترین معیارهای عملکردی برای مسئله خاصی استفاده کنند تا فرآیند استقرار یک مدل به بهترین شکل انجام شود.
بهعنوان مثال، ورودیهای خصمانه که پیشتر به آنها اشاره کردیم، ورودیهای مخربی هستند که برای فریب یک شبکه طراحی شدهاند. بهطور مثال، اسپری رنگ یا برچسب روی تابلوها میتواند ماشینهای خودران را فریب دهد تا بیشازحد مجاز شتاب بگیرند. برای حل این مشکل، باید بار کاری مدلها را سبک کرد و اطمینان حاصل کرد که مدل قادر به تفسیر و درک مواردی است که ممکن است در مجموعه دادهها لحاظ نشده باشد.
کلام آخر
یادگیری ترکیبی بهدنبال گذر از مرزهای یادگیری تحت نظارت و بدون نظارت است. روشهایی مانند یادگیری نیمهنظارتشده و خودنظارتشده، میتوانند بینشهای ارزشمندی را از دادههای بدون برچسب استخراج کنند و کمک کنند بهشکل کارآمدتر و بهینهتری از دادههای بدون نظارت استفاده کنیم.
همانطور که وظیفهها پیچیدهتر میشوند، یادگیری ترکیبی یک کار را به چند مولفه سادهتر تجزیه میکند. هنگامیکه این مولفهها با هم کار میکنند یا در مقابل یکدیگر قرار میگیرند، نتیجه نهایی یک مدل قدرتمند و کارآمد خواهد بود.
در مقطع فعلی یادگیری کاهشیافته چندان مورد توجه قرار نگرفته است، زیرا نگاهها به سمت یادگیری عمیق معطوف شده است، اما در آینده نزدیک هنگامیکه پارادایمها به سمت طراحی مبتنی بر استقرار متمایل شوند، شاهد رشد تحقیقات در این حوزه خواهیم بود.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.























نظر شما چیست؟