










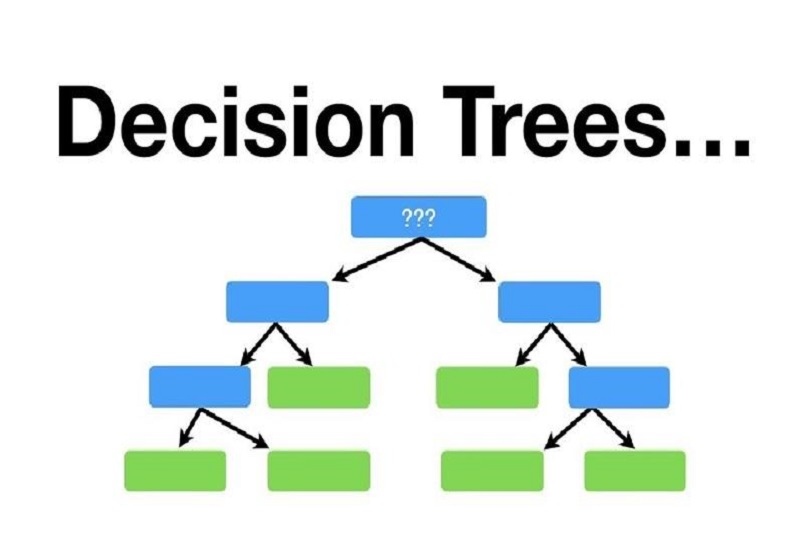
درخت تصمیم در قالب الگوریتم
درخت تصمیم مشتمل بر یک سری گره است که هر گره شامل یک تصمیم و یا یک شرط است. از ریشه درخت شروع میشود و با پیمودن مسیرهای مختلف درخت به گرههای دیگر میرسیم، تا زمانی که به یک برگ برسیم که نتیجه نهایی را نشان میدهد.
درخت تصمیم میتواند به عنوان یک الگوریتم تصمیمگیری استفاده شود. در این الگوریتم، مجموعه دادههای ورودی برای هر گره درخت بررسی میشود و براساس شرط و یا تصمیمی که در آن گره قرار دارد، به یکی از شاخههای درخت هدایت میشویم. این فرآیند تا زمانی ادامه مییابد که به یک برگ درخت برسیم که نتیجه نهایی را نشان میدهد. از مزایای استفاده از درخت تصمیم میتوان به سادگی در پیادهسازی، قابلیت تعمیم و قابلیت فهم آسان آن اشاره کرد.
مطلب پیشنهادی
 تصمیمگیری بر مبنای درخت در یادگیری ماشین
تصمیمگیری بر مبنای درخت در یادگیری ماشین
مطلب پیشنهادی
چه مسائلی را میتوان با استفاده از درخت تصمیم حل کرد؟
از مسائل مهمی که امکان حل آنها با استفاده از درخت تصمیم وجود دارد به موارد زیر باید اشاره کرد:
- تشخیص بیماری: میتوان درخت تصمیم را به کار برد تا با استفاده از علائم بالینی بیمار، به تشخیص بیماری بپردازیم.
- تصمیمگیری در بازاریابی: میتوان با استفاده از درخت تصمیم، تصمیماتی را در زمینه بازاریابی گرفت. به عنوان مثال، با تحلیل دادههای مشتریان میتوان به تصمیمهایی در زمینه تخفیف، تعیین قیمت و... دست یافت.
- تخمین قیمت مسکن: میتوان با استفاده از درخت تصمیم، به تخمین قیمت مسکن پرداخت. به عنوان مثال، با در نظر گرفتن ویژگیهای مختلف مسکن، میتوان به تخمین قیمت آنها دست یافت.
- تشخیص دستهبندی متن: میتوان با استفاده از درخت تصمیم، به تشخیص دستهبندی متن پرداخت. به عنوان مثال، میتوان با تحلیل کلمات موجود در متن، آن را در یکی از دستهبندهای تعریف شده قرار داد.
- تشخیص چهره: میتوان با استفاده از درخت تصمیم، به تشخیص چهره پرداخت. به عنوان مثال، با تحلیل ویژگیهای مختلف چهره، میتوان به تشخیص چهره فرد دست یافت.
به طور کلی، درخت تصمیم در حل مسائل مختلفی که نیاز به تصمیمگیری دارند، کاملا مفید است.
درخت تصمیم در یادگیری ماشین
درخت تصمیم یک روش مهم در یادگیری ماشین است که برای حل مسائل دستهبندی و پیشبینی استفاده میشود. در این روش، یک مجموعه دادهها برای آموزش به یک الگوریتم درخت تصمیم داده میشود. سپس با استفاده از این درخت، میتوان پیشبینیهایی انجام داد یا به طبقهبندی دادهها پرداخت.
درخت تصمیم با استفاده از یک سری از تصمیمات یا شروط ساخته میشود. هر گره درخت شامل یک شرط است که برای تصمیمگیری در مورد دادهها استفاده میشود. برای هر شرط، دادههای مجموعه آموزش به دو دسته تقسیم میشود. سپس با استفاده از الگوریتمهای خاص، بهترین شرط برای جداسازی دادهها انتخاب میشود و به عنوان شرط در گره درخت قرار میگیرد.
به طور معمول، درخت تصمیم به صورت بازگشتی ساخته میشود، به این معنی که برای هر گره درخت، یک زیر درخت جدید ساخته میشود که شامل دادههایی است که توسط شرط گره به دو دسته تقسیم شدهاند. این فرآیند تکرار میشود تا زمانی که به یک شرط پایانی برسیم و دادهها به دو دسته جداگانه تقسیم نشوند.
درخت تصمیم در یادگیری ماشین بسیار مفید است، زیرا به عنوان یک الگوریتم سریع و قابل فهم با دادههای بزرگ میتواند کارآمد باشد. همچنین، درخت تصمیم قابلیت تفسیر و تحلیل آسانی دارد و میتواند برای مسائل پیشبینی و دستهبندی مختلف مانند تشخیص بیماری، پیشبینی فروش و تصمیمگیری در بازاریابی استفاده شود.
آیا درخت تصمیم میتواند برای مسائل پیشبینی و دستهبندی دادههای غیرعددی استفاده شود؟
پاسخ مثبت است. درخت تصمیم میتواند برای مسائل پیشبینی و دستهبندی دادههای غیر عددی نیز استفاده شود. درخت تصمیم به طور کلی برای دادههای گسسته (دادههایی که دارای متغیرهای کیفیتی هستند، مانند رنگ، نوع و ...) و دادههای پیوسته (دادههایی که دارای متغیرهای کمی هستند، مانند قیمت، طول و ...) قابل استفاده است.
برای دادههای گسسته، درخت تصمیم میتواند شرایطی را برای هر متغیر کیفی تعیین کند و سپس مجموعه دادهها را بر اساس این شرایط به دستههای مختلف تقسیم کند. به عنوان مثال، در یک مسأله دستهبندی متن، درخت تصمیم میتواند برای هر کلمه، شرطی تعیین کند که متن را به دو دسته مختلف تقسیم کند.
برای دادههای پیوسته، درخت تصمیم میتواند با استفاده از مقادیر بینایی متغیرهای کمی، شرایطی را برای تقسیم دادهها به دستههای مختلف تعیین کند. به عنوان مثال، در یک مسأله پیشبینی قیمت مسکن، درخت تصمیم میتواند با استفاده از مقادیر قیمت، شرایطی را برای تقسیم مسکنها به دو دسته مختلف تعیین کند.
به طور کلی، درخت تصمیم به عنوان یک الگوریتم دستهبندی و پیشبینی، میتواند با دادههای گسسته و پیوسته کار کند، بنابراین امکان استفاده از آن در ارتباط با مسائل مختلفی از جمله تشخیص بیماری، پیش بینی فروش و تصمیمگیری در بازاریابی مفید باشد.
چگونه درخت تصمیم در یادگیری ماشین را با پایتون پیادهسازی کنیم؟
اکنون که اطلاعات کلی در ارتباط با درخت تصمیم به دست آوریم، اجازه دهید به ذکر مثال عملی در این زمینه بپردازیم. پیادهسازی درخت تصمیم در یادگیری ماشین به وسیله کتابخانههای مختلفی از جمله scikit-learn در زبان پایتون امکانپذیر است. در اینجا یک مثال ساده برای پیادهسازی درخت تصمیم با استفاده از کتابخانه scikit-learn در پایتون آمده است:
ابتدا، باید کتابخانه scikit-learn را با استفاده از دستور زیر نصب میکنید:
pip install scikit-learn
سپس، برای ساخت یک مدل درخت تصمیم، میتوانید از کلاس DecisionTreeClassifier کتابخانه scikit-learn استفاده کنید. مثال زیر نشان میدهد که چگونه یک مدل درخت تصمیم را با استفاده از داده های آموزشی ساخته و آن را برای پیشبینی استفاده کنید:
from sklearn.tree import DecisionTreeClassifier
ساخت دادههای آموزش
X_train = [[0, 0], [1, 1]]
y_train = [0, 1]
ساخت مدل درخت تصمیم
clf = DecisionTreeClassifier()
# آموزش مدل با داده های آموزشی
clf.fit(X_train, y_train)
# پیشبینی برچسب داده جدید
X_test = [[2., 2.]]
y_pred = clf.predict(X_test)
در این مثال، دادههای آموزشی شامل دو ویژگی دو بعدی هستند و برچسبهای آنها در لیست y_train قرار دارد. بعد از آن، یک مدل درخت تصمیم با استفاده از کلاس DecisionTreeClassifier ساخته میشود و با داده های آموزشی آموزش داده میشود. سپس، با استفاده از داده تست جدید، برچسب آن با استفاده از پیشبینی مدل درخت تصمیم به دست میآید.
لازم به ذکر است که این مثال بسیار ساده است و در موارد پیچیدهتر، باید به عوامل دیگری مانند پیش پردازش دادهها، تنظیم پارامترها، و ... توجه کرد.
چگونه درخت تصمیم در یادگیری ماشین را با سیپلاسپلاس پیاده سازی کنیم؟
در سی پلاس پلاس، میتوانید درخت تصمیم را با استفاده از کتابخانههای مختلفی پیادهسازی کنید. یکی از کتابخانههای مناسب برای این کار، کتابخانه منبع باز است.
برای استفاده از MLPACK در سی پلاس پلاس، ابتدا باید آن را نصب کنید. برای این کار، میتوانید از سیستم مدیریت بسته مانند apt-get استفاده کنید:
sudo apt-get install libmlpack-dev
سپس برای ساخت درخت تصمیم با استفاده از MLPACK، باید کدی مشابه با زیر را پیاده سازی کنید:
#include <mlpack/core.hpp>
#include <mlpack/methods/decision_tree/decision_tree.hpp>
using namespace mlpack;
using namespace mlpack::tree;
int main()
{
// ساخت داده های آموزشی
arma::mat data; // داده های آموزشی به صورت ماتریس ذخیره می شوند
data::Load("dataset.csv", data); // فایل داده ها را بارگیری می کنیم
arma::Row<size_t> labels; // برچسب های آموزشی
data::Load("labels.csv", labels); // فایل برچسب ها را بارگیری می کنیم
// ساخت مدل درخت تصمیم
DecisionTree<> dtree(data, labels); // ساخت درخت تصمیم
// ذخیره مدل درخت تصمیم
data::Save("decision_tree.xml", "tree", dtree);
// پیش بینی برچسب داده جدید
arma::vec testPoint = ...; // تعیین داده جدید
size_t predictedClass;
dtree.Classify(testPoint, predictedClass); // پیش بینی برچسب داده جدید
return 0;
}
در این مثال، دادههای آموزشی و برچسبها از فایل csv بارگیری میشوند و سپس با استفاده از کلاس DecisionTree<> درخت تصمیم ساخته میشود. سپس با استفاده از تابع Classify()، میتوانید برچسب داده جدید را پیش بینی کنید. در نهایت، مدل درخت تصمیم به فایل XML ذخیره میشود.
لازم به ذکر است که این مثال نیز بسیار ساده است و برای موارد پیچیدهتر همانند مثال قبلی نیاز به پیش پردازش دادهها، تنظیم پارامترهای مختلف و ... است.
آیا برای پیشبینی برچسب داده جدید، باید همیشه درخت تصمیم را مجددا ساخت؟
خیر، برای پیشبینی برچسب داده جدید، نیازی به ساخت مجدد درخت تصمیم نیست. هرگاه درخت تصمیم ساخته شده با دادههای آموزشی، مدلی قابل استفاده برای پیشبینی برچسب دادههای جدید است. به عبارتی، درخت تصمیم یک مدل یادگیری ماشین است که با استفاده از دادههای آموزشی ساخته شده و برای پیشبینی برچسب دادههای جدید مورد استفاده قرار میگیرد.
برای پیشبینی برچسب دادههای جدید با استفاده از درخت تصمیم، فقط کافی است که ویژگیهای داده جدید را به عنوان ورودی به مدل بدهید و برچسب مربوط به آن را با استفاده از درخت تصمیم پیشبینی کنید. برای مثال، در پایتون با استفاده از کد زیر میتوانید برچسب داده جدید را با استفاده از مدل درخت تصمیم پیش بینی کنید:
# فرض بر این است که مدل DecisionTreeClassifier با نام clf ساخته شده است.
# داده جدید
new_data = [[0.2, 0.8], [0.5, 0.5], [0.7, 0.3]]
# پیش بینی برچسب داده جدید
predicted_labels = clf.predict(new_data)
در این مثال، با دادن دادههای جدید به عنوان ورودی به مدل درخت تصمیم که قبلاً با دادههای آموزشی ساخته شده، برچسبهای مربوط به آن دادهها با استفاده از تابع predict() پیشبینی میشود.
فلذا در کل، برای پیشبینی برچسب داده جدید، نیازی به ساخت مجدد درخت تصمیم نیست و مدل ساخته شده با دادههای آموزشی قابل استفاده برای پیشبینی برچسب دادههای جدید است.
آیا میتوانم مدل درخت تصمیم را با الگوریتمهای دیگری ترکیب کنم؟
بله، شما میتوانید درخت تصمیم را با الگوریتمهای دیگری ترکیب کنید. این روش به عنوان یک روش آموزشی ترکیبی شناخته میشود که به عنوان ترکیب الگوریتمها معروف است. در این روش، تعدادی از مدلهای یادگیری ماشین، مانند درخت تصمیم، با استفاده از دادههای آموزشی ساخته میشوند و در نهایت نتایج آنها ترکیب میشود تا بهترین نتیجه را برای پیش بینی برچسب دادههای جدید بدست آورد.
دو روش معمول برای ترکیب مدلها وجود دارد:
- روش رایگیری: در این روش، برای پیشبینی برچسب دادههای جدید، برچسبی که بیشترین تعداد رای را در مدلهای یادگیری ماشین به دست آورده باشد، به عنوان برچسب نهایی انتخاب میشود. این روش برای مدلهایی که قابلیت آموزش سریع و پردازش سریع را دارند، مانند درخت تصمیم، مناسب است.
- روش میانگینگیری: در این روش، نتایج پیشبینی برچسب دادههای جدید توسط مدلهای یادگیری ماشین ترکیب شده و میانگین آنها به عنوان برچسب نهایی انتخاب میشود. این روش برای مدلهایی که قابلیت آموزش کند و دقت بالا را دارند، مانند شبکههای عصبی، مناسب است.
برای ترکیب درخت تصمیم با دیگر مدلها، میتوانید از روشهای آموزشی ترکیبی مانند روش آنسامبل استفاده کنید. به عنوان مثال، میتوانید درخت تصمیم را با الگوریتمهایی مانند روش رایگیری اکثریت (Majority Voting) یا با مدلهای دیگری مانند شبکههای عصبی ترکیب کنید.
آیا روش میانگینگیری برای ترکیب درخت تصمیم با مدلهای دیگری مانند SVM مناسب است؟
بله، روش میانگینگیری برای ترکیب درخت تصمیم با مدلهای دیگری مانند SVM نیز مناسب است. در واقع، روش میانگینگیری برای ترکیب مدلهای یادگیری ماشین به عنوان یک روش آموزشی ترکیبی شناخته میشود که به عنوان آنسامبل یا ترکیب الگوریتمها معروف است.
در این روش، نتایج پیشبینی برچسب دادههای جدید توسط مدلهای یادگیری ماشین ترکیب شده و میانگین آنها به عنوان برچسب نهایی انتخاب میشود. مزیت این روش این است که با ترکیب نتایج پیشبینی برچسب دادههای جدید، دقت پیشبینی برچسب بالاتری به دست میآید.
برای ترکیب درخت تصمیم با مدلهای دیگری مانند SVMمیتوانید از روش میانگینگیری استفاده کنید. در این روش، برای پیش بینی برچسب دادههای جدید، نتایج پیشبینی برچسب توسط درخت تصمیم و SVM ترکیب شده و میانگین آنها به عنوان برچسب نهایی انتخاب میشود.
برای مثال، در پایتون میتوانید از کد زیر برای ترکیب درخت تصمیم و SVM با استفاده از روش میانگینگیری استفاده کنید:
# فرض بر این است که دو مدل DecisionTreeClassifier و SVC با نامهای clf1 و clf2 ساخته شدهاند.
# همچنین، فرض بر این است که دادههای آموزشی و دادههای جدید به ترتیب در متغیرهای X_train و X_test ذخیره شدهاند.
# آموزش دو مدل
clf1.fit(X_train, y_train)
clf2.fit(X_train, y_train)
# پیشبینی برچسب دادههای جدید با استفاده از مدلهای ساخته شده
y_pred1 = clf1.predict(X_test)
y_pred2 = clf2.predict(X_test)
# ترکیب نتایج پیشبینی برچسب با استفاده از میانگینگیری
y_pred = (y_pred1 + y_pred2) / 2
در این مثال، با استفاده از دو مدل DecisionTreeClassifier و SVC، نتایج پیشبینی برچسب دادههای جدید ترکیب شده و میانگین آنها به عنوان برچسب نهایی انتخاب میشود.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.


















نظر شما چیست؟