









خوشهبندی چیست؟
بخشبندی که اصطلاح کاملتر و دقیقتر آن تحلیل خوشهبندی (Cluster Analysis) است به فرآیندی اشاره دارد که با استفاده از آن میتوان مجموعهای از اشیا را به گروههای مجزا از یکدیگر تخصیص داد. اعضا هر خوشه بر مبنای ویژگیهایی که دارند به یکدیگر شباهت دارند و در مقابل میزان شباهت بین خوشهها کم است. خوشهبندی با هدف برچسبگذاری اشیا انجام میشود تا امکان شناسایی اشیایی که عضو گروههای مختلف هستند با سهولت انجام شود. در این روش دادهها به گروههای معناداری تقسیم میشوند که محتویات هر خوشه ویژگیهای مشابه، اما متفاوت از سایر اشیایی دارد که در گروههای دیگر قرار گرفتهاند. از مکانیزم خوشهبندی در مجموعه دادههای بزرگ و در مواردی که تعداد خصلتهای دادهای زیاد باشد استفاده میشود.
همانگونه که اشاره شد در فرآیند خوشهبندی، گروهبندی مجموعهای از اشیاء بر مبنای ویژگیهای مشابه انجام میشود و این الگوریتمهای دادهکاوی اکتشافی هستند که از روشهای معمول تجزیه و تحلیل آماری برای دسترسی به اشیا استفاده میکنند. اصلیترین تفاوت تحلیل خوشهبندی و تحلیل طبقهبندی نبود برچسبهای اولیه برای مشاهدات است. در خوشهبندی بر اساس ویژگیهای مشترک و روشهای اندازهگیری فاصله یا شباهت بین اشیا برچسبهایی بهطور خودکار تخصیص داده شود، در حالی که در طبقهبندی برچسبهای اولیه وجود دارد و باید از الگوریتمهای پیشگویانه برای برچسبگذاری مشاهدات جدید استفاده کرد. در دادهکاوی، نتیجه گروهها مورد توجه هست و در طبقهبندی خودکار، قدرت تشخیصی مورد توجه است. با توجه به روشهای مختلف اندازهگیری شباهتها یا الگوریتمهای تشکیل خوشه، این احتمال وجود دارد که نتایج خوشهبندی برای مجموعه دادههای ثابث متفاوت باشد.
اصطلاحات خوشهها شامل گروههایی با فاصلههای کم بین اعضای خوشه، مناطق متراکم فضای داده، فواصل یا توزیعهای آماری خاص است. بنابراین خوشه بندی میتواند به عنوان یک مسئله بهینهسازی چند هدفه انجام شود. الگوریتم خوشهبندی مناسب و تنظیمات پارامتری (مثل تابع بردار فاصله، آستانه تراکم یا تعداد خوشه مورد انتظار) بستگی به تنظیم مجموعه دادهها توسط فرد و استفاده خاص از نتایج دارد. تجزیه و تحلیل خوشهای یک روش خودکار نیست، بلکه یک فرآیند تکراری از کشف دانش یا بهینهسازی چند هدفه تعاملی است که مبتنی بر آزمون و خطا است. در بیشتر موارد باید دادههای پیش پردازش شده و پارامترهای مدل اصلاح شوند تا نتیجه دلخواه بهدست آید.
به سختی میتوان تعریف دقیق و روشنی برای مفهوم خوشه ارائه کرد، یکی از دلایلش این است که الگوریتمهای خوشهبندی زیادی وجود دارد، با اینحال، همه آنها یک وجه اشتراک دارند که حداقل دارای یک گروه از اشیاء دادهای هستند. پژوهشگران از مدلهای مختلف خوشه استفاده میکنند و برای هر یک از این مدلهای خوشه، الگوریتمهای مختلفی را طراحی کردهاند.
مدلهای خوشهبندی
درست است که بیشتر الگوریتم و روشهای خوشهبندی ساختار یکسانی دارند، با اینحال، تفاوتهایی در شیوه اندازهگیری شباهت یا فاصله و انتخاب برچسب برای اشیا هر خوشه در این روشها وجود دارد. بر همین اساسی طبقهبندی آنها دید بهتری از روش خوشهبندی استفاده شده در الگوریتمها ارائه میکند. بهطور کلی، الگوریتمهای خوشهبندی را میتوان به 4 گروه اصلی الگوریتمهای خوشهبندی تفکیکی، سلسله مراتب، مبتنی بر چگالی و مبتنی بر مدل تقسیم کرد که البته برخی منابع مدلهای بیشتری به شرح زیر را ارائه میکنند.
مدلهای متصل: به عنوان مثال، خوشهبندی سلسله مراتبی، مدلهایی براساس فاصله متصل را ایجاد میکند.
مدلهای مرکزی: به عنوان مثال، الگوریتم k-means، هر خوشه را با یک بردار متوسط نشان میدهد.
مدلهای توزیع: خوشهها با استفاده از توزیعهای آماری، مانند توزیع نرمال چند متغیره که در الگوریتم حداکثر انتظار، استفاده شدهاست.
مدلهای تراکم: به عنوان مثال، DBSCAN و OPTICS خوشه را به عنوان مناطق متراکم متصل در فضای داده تعریف میکنند.
مدلهای زیر فضایی: به عنوان خوشه مشترک یا خوشهای دو حالت شناخته میشود. خوشهها با هر دو اعضای خوشه و ویژگیهای مرتبط مدلسازی میشوند.
مدلهای گروهی: برخی از الگوریتمها یک مدل تصحیح شده برای نتایج خود را ارائه نمیدهند و فقط اطلاعات گروهبندی را ارائه میدهند.
مدلهای مبتنی بر گراف: یک کلاس، یعنی یک زیر مجموعه از گرهها در یک گراف به طوری که هر دو گره در زیر مجموعه با یک لبه متصل میشود که میتواند به عنوان یک شکل اولیه از خوشه مورد توجه قرار گیرد.
مدلهای عصبی: شبکه عصبی غیرقابل نظارت، شناخته شدهترین نقشه خود سازمانی است و معمولاً این مدلها میتوانند به عنوان مشابه با یک یا چند مدل فوق شامل مدلهای زیر فضایی، زمانی که شبکههای عصبی یک فرم تجزیه و تحلیل مؤلفه اصلی یا مستقل تجزیه و تحلیل المان میباشد.
خوشه بندی اساساً مجموعهای از خوشهها است که معمولاً شامل تمام اشیاء در مجموعه دادهها میشود. افزونبر این، میتوان رابطهٔ خوشهها را به یکدیگر تعریف کند، به عنوان مثال، سلسله مراتب خوشههای تعبیه شده در یکدیگر.
طبقهبندی خوشهبندی بر مبنای سختی
خوشهبندی را میتوان براساس سختی تمایز به صورت زیر مشخص کرد:
خوشهبندی سخت: هر شیء متعلق به خوشه است یا نه.
خوشهبندی نرم (همچنین: خوشه فازی): هر شیء به درجه خاصی از هر خوشه متعلق است (به عنوان مثال، احتمال وابستگی به خوشه)
خوشهبندی جداسازی دقیق ( پارتیشن بندی): هر شیء دقیقا به یک خوشه متعلق است.
خوشهبندی جداسازی دقیق با ناپیوستگی: اشیاء میتوانند به هیچ خوشهای تعلق نداشته باشند.
خوشهبندی همپوشانی (همچنین: خوشهبندی جایگزین، خوشهبندی چندگانه): اشیاء ممکن است متعلق به بیش از یک خوشه باشد؛ معمولاً خوشههای سخت را شامل میشود
خوشهبندی سلسله مراتبی: اشیایی که متعلق به خوشه فرزند هستند، متعلق به خوشه پدر و مادر هم هستند.
خوشهبندی زیر فضا: در حالی که خوشهبندی همپوشانی، که در یک زیر فضای منحصر به فرد تعریف شده، انتظار نمیرود که خوشهها با همپوشانی داشته باشند.
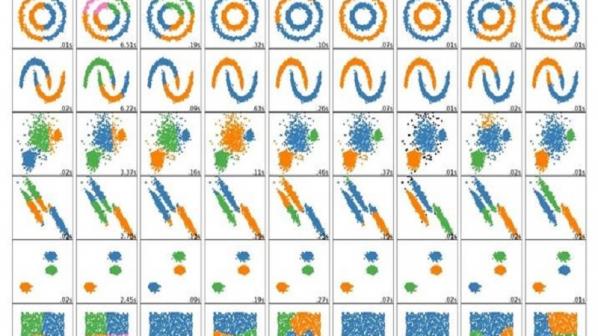
بهترین الگوریتم خوشهبندی برای یک مسئله خاص، اغلب باید به صورت تجربی انتخاب شود، مگر اینکه یک دلیل ریاضی برای ترجیح دادن یک مدل خوشه بر دیگری وجود داشته باشد. لازم به ذکر است که یک الگوریتم که برای یک نوع مدل طراحی شدهاست و در یک مجموعه دادهای که شامل تفاوت اساسی مدل است، شکست میخورد. به عنوان مثال، k-means نمیتواند خوشههای غیرمحدب را پیدا کند.
خوشهبندی سلسه مراتبی
خوشهبندی براساس اتصال، که به عنوان خوشهبندی سلسله مراتبی شناخته میشود، بر مبنای ایده اصلی اشیائی است که بیشتر مربوط به اشیای نزدیک، نسبت به اشیاء دورتر است. این الگوریتمها اشیا را برای ایجاد خوشهها بر اساس فاصله آنها متصل میکنند. خوشه را میتوان به طورکلی با حداکثر فاصله مورد نیاز برای اتصال قطعات خوشه توصیف کرد. در فاصلههای مختلف، خوشههای متفاوتی شکل میگیرند که میتواند با استفاده از یک دندروگرام نشان داده شود، که توضیح میدهد که نام معمول «خوشهبندی سلسله مراتبی» از آن میآید: این الگوریتمها یک پارتیشن بندی مجموعه داده را ارائه نمیدهند، بلکه یک سلسله مراتب گستردهای از خوشههایی که در فاصلههای معینی با یکدیگر ادغام میشوند، ارائه میدهد. خوشهبندی سلسله مراتبی شامل دو نوع خوشهبندی میباشد:
single linkage -1 این روش که به روش Bottom-Up و Agglomerative نیز معروف است روشی است که در آن ابتدا هر داده به عنوان یک خوشه در نظر گرفته میشود. در ادامه با به کارگیری یک الگوریتم هر بار خوشههای دارای ویژگیهای نزدیک به هم با یکدیگر ادغام شده و این کار ادامه مییابد تا به چند خوشهٔ مجزا برسیم. مشکل این روش حساس بودن به نویز و مصرف زیاد حافظه میباشد.
complete linkage -2 در این روش که به روش Top-Down و Divisive نیز معروف است ابتدا تمام دادهها به عنوان یک خوشه در نظر گرفته شده و با به کارگیری یک الگوریتم تکرار شونده هربار دادهای که کمترین شباهت را با دادههای دیگر دارد به خوشههای مجزا تقسیم میشود. این کار ادامه مییابد تا یک یا چند خوشه یک عضوی ایجاد شود. مشکل نویز در این روش برطرف شدهاست.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.




















نظر شما چیست؟