


دسته بندی داده ها با شبکه عصبی مصنوعی چیست؟
دستهبندی دادهها با استفاده از شبکه عصبی مصنوعی به استفاده از قدرت محاسباتی شبکههای عصبی به منظور تشخیص و گروهبندی دادهها اشاره دارد. با آموزش یک شبکه عصبی با دادههای برچسبدار میتوانیم آن را برای تشخیص و دستهبندی دادههای جدید مورد استفاده قرار دهیم. در فرآیند دستهبندی دادهها با استفاده از شبکه عصبی مصنوعی، ابتدا باید دادههای مورد نیاز را جمعآوری و پیشپردازش کنیم. سپس، باید معماری شبکه عصبی را طراحی کرده و آن را با استفاده از دادههای آموزشی، آموزش دهیم. پس از آموزش، عملکرد شبکه با دادههای ارزیابی یا اعتبارسنجی بررسی میشود تا مشخص شود که عملکردش به چه صورتی است. در نهایت، میتوانید شبکه را برای دستهبندی دادههای جدید استفاده کنید.
به طور معمول در بیشتر موارد ما از شبکههای عصبی عمیق (Deep Neural Networks) استفاده میکنیم که شامل چند لایه عصبی هستند. این لایهها شامل لایه ورودی، لایههای پنهان و لایه خروجی هستند. هر لایه شامل یک یا چند نورون است که با استفاده از توابع فعالسازی، محاسبات را انجام میدهند. با اعمال الگوریتمهای بهینهسازی و تابع هدف مناسب، شبکه عصبی مصنوعی به صورت خودکار وزنها و پارامترهای خود را تنظیم میکند تا بهترین عملکرد را در دسته بندی دادهها داشته باشد. به عنوان مثال، در فرآیند دستهبندی تصاویر، میتوان از شبکههای عصبی عمیق مانند شبکههای عصبی پیچشی (Convolutional Neural Networks) استفاده کرد. این شبکهها با استفاده از لایههای پیچشی به صورت مکرر، توانایی تشخیص الگوهای تصویری را دارند و میتوانند تصاویر را به دستههای مختلفی مانند خودرو، حیوانات، میوهها و غیره دسته بندی کنند.
دستهبندی (Classification) چیست؟
دستهبندی به معنای تقسیم دادهها به گروههای مختلف براساس ویژگیها یا خصوصیات خاص است. در فرآیند دستهبندی، هدف این است که دادهها را در دستههای متمایز و معین قرار دهیم به نحوی که اعضای هر دسته به یکدیگر شباهت بیشتری داشته باشند و از دیگر دستهها متمایز باشند. همچنین، دستهبندی به ما امکان میدهد بر اساس دستههای مختلف، تصمیمگیریها و پیشبینیها را انجام دهیم. دستهبندی در زمینههای مختلفی مورد استفاده قرار میگیرد. به عنوان مثال، در پردازش تصویر، دستهبندی به ما اجازه میدهد تا تصاویر را به دستههای مختلفی مانند خودرو، حیوانات، میوهها و غیره دسته بندی کنیم. در حوزه تشخیص صدا، میتوانیم صداها را به دستههای مختلف مانند گفتار انسان، صدای خودرو، صدای حیوانات و غیره دسته بندی کنیم. همچنین در حوزه پردازش زبان طبیعی، میتوانیم متنها را بر اساس موضوعات مختلف دسته بندی کنیم. برای دستهبندی دادهها، معمولا از الگوریتمهای یادگیری ماشین استفاده میشود. این الگوریتمها با استفاده از دادههای آموزشی که دارای برچسب هستند، مدلهایی را آموزش میدهند که قادر به تشخیص و دستهبندی دادههای جدید هستند. دستهبندی یکی از وظایف اساسی در تحلیل دادهها و یادگیری ماشین هستند و در بسیاری از زمینهها استفاده میشوند. با دستهبندی دادهها، میتوانیم الگوها و ارتباطات مختلف را در دادهها بشناسیم و از آنها در تصمیمگیریها و پیشبینیها استفاده کنیم.
خوشهبندی (Clustering) چیست؟
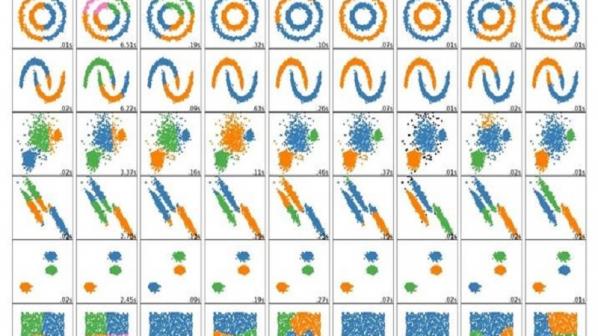
خوشهبندی به معنای تقسیم دادهها به گروههای مشابه بر اساس ویژگیها و الگوهای مشترک است. هدف اصلی خوشهبندی این است که دادهها را به گروههایی تقسیم کنیم که اعضای هر گروه شباهت بیشتری به یکدیگر داشته باشند و دادههای گروههای مختلف از یکدیگر متمایز باشند. به طور کلی، خوشهبندی بر مبنای شباهت و همبستگی دادهها انجام میشود. در خوشهبندی در تعامل با یادگیری بدون نظارت (Unsupervised) استفاده میشود، به این معنی که دادهها بدون برچسب موجود هستند و هدف این است که الگوهای مشترک و روابط مخفی در دادهها شناسایی شوند. در این روش، الگوریتمهای خوشهبندی براساس ویژگیهای مشابه دادهها، فاصله بین آنها یا ارتباطات آنها اقدام به تقسیم دادهها به خوشههای مختلف میکنند. به طور معمول، در خوشهبندی، تعداد خوشهها مشخص نیست و بر اساس خصوصیات دادهها و نیازهای مسئله تعیین میشود. در این زمینه الگوریتمهای خوشهبندی معروفی مثل K-Means، Hierarchical Clustering، DBSCAN و Gaussian Mixture Models (GMM) در دسترس قرار دارند.
خوشهبندی یکی از روشهای مهم در تحلیل دادهها و یادگیری ماشین است و در بسیاری از زمینهها از آن استفاده میشود. با کشف الگوها و رابطههای موجود در دادهها، میتوانیم درک بهتری از دادهها و ساختار آنها داشته باشیم و استراتژیهای مناسب برای هر گروه اتخاذ کنیم. هدف اصلی خوشهبندی این است که دادهها را بر اساس شباهتها به گروههایی تقسیم کند. در عمل، اعضای هر گروه زیادی به یکدیگر دارند. برخلاف دستهبندی که نیاز به برچسبهای قبلی برای دادهها داریم، خوشهبندی بر پایه ویژگیها و ساختار دادهها انجام میشود. در خوشهبندی، تعداد خوشهها ممکن است مشخص نباشد و به عنوان ورودی تعیین شود یا توسط الگوریتمها تعیین شود. همچنین، معیارهای مختلفی برای اندازهگیری شباهت بین دادهها در خوشهبندی استفاده میشود، مانند معیار فاصله اقلیدسی. با استفاده از خوشهبندی، میتوانیم ویژگیهای مشترک و الگوهای مخفی در دادهها را شناسایی کنیم. این اطلاعات میتوانند در تصمیمگیریها، پیشبینیها و استخراج دانش مفید به ما کمک کنند.
دستهبندی دادهها با استفاده از شبکه عصبی مصنوعی
فرایند دستهبندی با استفاده از شبکههای عصبی مصنوعی شامل چند مرحله است. مرحله اول تهیه دادهها است. در این مرحله، دادههای آموزشی برای آموزش شبکه عصبی تهیه میشوند. دادهها ممکن است شامل تصاویر، متن، صدا و سایر نوعهای دادهها باشند. همچنین، دادهها به دستههای مختلف برچسبگذاری شدهاند تا بتوانیم شبکه را به درستی آموزش دهیم. مرحله بعد طراحی ساختار شبکه عصبی است. در این مرحله، ساختار شبکه عصبی برای دستهبندی دادهها طراحی میشود. ساختار شبکه شامل لایههای مختلفی از نورونها است که هر کدام وظایف خاص خود را دارند. مرحله بعد نوبت به آموزش شبکه عصبی میرسد. در این مرحله، شبکه عصبی با استفاده از دادههای آموزشی به طور مکرر آموزش داده میشود. هدف اصلی در آموزش شبکه عصبی این است که وزنها به گونهای تنظیم شوند که خطا در پیشبینی برچسبها کمینه شود. برای این منظور، از الگوریتمهای بهینهسازی مانند پسانتشار (Backpropagation) استفاده میشود. پس از آموزش شبکه، نوبت به ارزیابی آن از طریق دادههای تست میرسد تا دقت و کارایی آن مشخص شود.
در چه زمان هایی نیاز به دسته بندی داده ها داریم؟
ما به دلایل مختلفی اقدام به دستهبندی دادهها میکنیم، اما به طور کلی هنگامی که قصد انجام یکسری کارهای مشخص را داریم به سراغ دستهبندی دادهها میرویم. اولین مورد تحلیل دادهها است. ما در حوزههای مختلف از دستهبندی دادهها برای تحلیل و استخراج اطلاعات مفید استفاده میکنیم. به عنوان مثال، در تجزیه و تحلیل اجتماعی، دادههای مربوط به رفتار رویدادها و افراد میتوانند بر اساس دستهبندیهایی مانند سن، جنسیت، محل زندگی و غیره مورد بررسی قرار دهیم.
در بسیاری از مسائل، نیاز به تشخیص الگوها و روابط بین دادهها وجود دارد. با دستهبندی دادهها، میتوان الگوهای مشترک و ویژگیهای مهم را در دادهها شناسایی کرده و از این طریق الگوها را تشخیص داد. علاوه بر این، در حوزههایی مثل علوم اجتماعی، مالی، پزشکی و غیره، نیاز به پیشبینی رویدادها و وقوع آنها در آینده داریم. با دستهبندی دادهها و تحلیل الگوها، میتوان پیشبینیهای دقیقتری ارائه کرد و تصمیمگیریهای بهتری انجام داد. جالب آنکه در برخی از صنایع و سیستمها، تشخیص عیب و خطا اهمیت زیادی دارد. از طریق دستهبندی دادهها میتوان الگوها و ویژگیهای غیر طبیعی را شناسایی کرده و عیبها و خطاها را تشخیص داد. در حوزه بینایی ماشین و پردازش تصویر، نیز دستهبندی تصاویر کاربرد زیادی دارد. با دستهبندی تصاویر، میتوان اشیاء، چهرهها، صحنهها و غیره را تشخیص داد و اقدام به دستهبندی کرد. در حوزه پردازش زبان طبیعی، دستهبندی متون و جملات نیز به منظور تفکیک و مدیریت اطلاعات اقدام به دستهبندی دادهها میکنیم. به عنوان مثال، میتوان متون را بر اساس موضوع، نوع جمله، احساسات موجود در آن و غیره دستهبندی کرد. در سیستمهای توصیهگر نیز دستهبندی دادهها برای تعیین سلیقهها، علایق و ویژگیهای موردنظر کاربران استفاده میشود. با دستهبندی دادهها، سیستم میتواند پیشنهادات و توصیههایی را بر اساس دستهبندیهای کاربران ارائه دهد.
یک مثال عملی از نحوه دسته بندی داده ها
برای درک بهتر مطلب اجازه دهید به یک مثال ساده در زمینه دستهبندی دادهها با زبان پایتون اشارهای داشته باشیم.
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
accuracy = knn.score(X_test, y_test)
print("دقت مدل:", accuracy)
در این مثال، از مجموعه داده Iris استفاده شده است که شامل ویژگیهای گلها (طول و عرض گلبرگها و ستونها) و برچسبهای دستههای مختلف گلها است. در ابتدا، دادهها را به دو گروه آموزشی و آزمایشی تقسیم میکنیم. سپس، یک مدل دستهبندی KNN ایجاد میشود و با استفاده از دادههای آموزشی فرآیند آموزش آغاز میشود. سپس، برچسبهای پیشبینی شده برای دادههای آزمایشی محاسبه میشوند و دقت مدل نیز محاسبه و نمایش داده میشود. قطعه کد بالا نشان میدهد که چگونه میتوان با استفاده از الگوریتمهای مختلف دستهبندی، دادهها را به دستههای مختلف تقسیم کرد و از مدلهای طراحی شده برای پیشبینی برچسبهای جدید استفاده کرد.
ماهنامه شبکه را از کجا تهیه کنیم؟
ماهنامه شبکه را میتوانید از کتابخانههای عمومی سراسر کشور و نیز از دکههای روزنامهفروشی تهیه نمائید.
ثبت اشتراک نسخه کاغذی ماهنامه شبکه
ثبت اشتراک نسخه آنلاین
کتاب الکترونیک +Network راهنمای شبکهها
- برای دانلود تنها کتاب کامل ترجمه فارسی +Network اینجا کلیک کنید.
کتاب الکترونیک دوره مقدماتی آموزش پایتون
- اگر قصد یادگیری برنامهنویسی را دارید ولی هیچ پیشزمینهای ندارید اینجا کلیک کنید.





















نظر شما چیست؟